
Mysql 常用语句
使用MySQL数据库
登录到MySQL
当MySQL服务已经运行时,我们可以通过MySQL自带的客户端工具登录到MySQL数据库中,首先打开命令提示符,输入以下格式的命名:
mysql -h 主机名 -u 用户名 -p
-h : 该命令用于指定客户端所要登录的MySQL主机名, 登录当前机器该参数可以省略;
-u : 所要登录的用户名;
-p : 告诉服务器将会使用一个密码来登录, 如果所要登录的用户名密码为空, 可以忽略此选项。
以登录刚刚安装在本机的MySQL数据库为例,在命令行下输入mysql -uroot -p 按回车确认, 如果安装正确且MySQL正在运行,就会提示输入密码
注:如要在命令行输入密码-p和密码之间不能有空格
一、数据库操作
1、创建数据库:
>CREATE DATABASE db_name; //db_name为数据库名 >CREATE DATABASE IF NOT EXISTS db_name default character set utf8 COLLATE utf8_general_ci; //条件创建数据库
2、删除数据库:
>DROP DATABASE db_name; >DROP DATABASE IF EXISTS db_name;
3、查看数据库:
>SHOW DATABASES;
4、选择数据库:
>USE db_name;
5、修改数据库
>ALTER DATABASE my_db CHARACTER SET latin1; //修改数据库字符编码
二、表的操作:
1、创建表:
(1).使用SQL语句创建
>CREATE TABLE IF NOT EXISTS tb_name( fid INT(11) NOT NULL DEFAULT '0', //fid INT类型显示11位,非空,默认值为0 ...................................... PRIMARY KEY(id) //主键 )ENGINE=InnoDB DEFAULT CHARSET=utf8 //设置表的存储引擎和默认编码(防止数据库中文乱码),一般常用InnoDB和MyISAM;InnoDB可靠,支持事务;MyISAM高效不支持全文检索.
(2).根据现有的表来创建并插入指定条件的数据
>CREATE TABLE tb_name2 SELECT * FROM tb_name;
或者部分复制:
>CREATE TABLE tb_name2 SELECT id,name FROM tb_name;
(3).创建临时表:
>CREATE TEMPORARY TABLE tb_name(这里和创建普通表一样);
2、查看表
(1).查看数据库中可用的表
>SHOW TABLES;
(2).查看表结构:
>DESC tb_name; 也可以使用: >SHOW COLUMNS in/from tb_name;
3、删除表:
>DROP [ TEMPORARY ] TABLE [ IF EXISTS ] tb_name[ ,tb_name2.......];
实例:
>DROP TABLE IF EXISTS tb_name; //存在则删除,不存在不操作
4、更改表:
>ALTER TABLE tb_name ADD[CHANGE,RENAME,DROP] [after 插入位置]...要更改的内容...
实例:
>ALTER TABLE tb_name ADD COLUMN address varchar(80) NOT NULL AFTER `column_name`; >ALTER TABLE tb_name DROP COLUMN address; >ALTER TABLE tb_name CHANGE scoer score SMALLINT(4) NOT NULL; //更改列名称或列字 >ALTER TABLE name_old RENAME name_new;
段类型(注:这里字段类型与表字段类型不一致会修改表字段类型)
5、增加删除主键
>ALTER TABLE tb_name ADD primary key (id); >ALTER TABLE tb_name DROP primary key;
三、数据增删查改
为了便于理解以下操作的含义,模拟学校学生信息管理系统,首先创建测试表和插入测试数据
CREATE TABLE `student` ( `fid` int(5) unsigned zerofill NOT NULL DEFAULT '00000', `fname` varchar(64) NOT NULL, `age` int(11) NOT NULL, `address` varchar(128) NOT NULL, `contace` varchar(12) NOT NULL, PRIMARY KEY (`fid`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8
insert into `student`(`fid`,`fname`,`age`,`address`,`contace`) values (00001,'张三',11,'湖南株洲','135698332'),(00002,'李四',12,'浙江杭州','123978986'),(00003,'王五',11,'湖南长沙','469878966'),(00004,'朱六',13,'湖北武汉','987964663'),(00005,'张三',11,'北京','124534534'),(00006,'欧阳克',13,'新疆','534534534');
CREATE TABLE `score` ( `fid` int(5) unsigned zerofill NOT NULL, `fchinese` int(11) unsigned NOT NULL, `fmatch` int(11) unsigned NOT NULL, `english` int(11) unsigned NOT NULL, `history` int(11) unsigned NOT NULL, PRIMARY KEY (`fid`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8
insert into `score`(`fid`,`fchinese`,`fmatch`,`english`,`history`) values (00001,87,97,65,77),(00002,66,87,88,90),(00003,87,46,99,88),(00004,77,94,84,88),(00005,89,97,96,99);
CREATE TABLE `infoext` ( `fid` int(5) unsigned zerofill NOT NULL, `ffname` varchar(32) NOT NULL, `fmname` varchar(32) NOT NULL, `fhobby` varchar(64) NOT NULL, PRIMARY KEY (`fid`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8
insert into `infoext`(`fid`,`ffname`,`fmname`,`fhobby`) values (00001,'史蒂夫','斯密斯','吃饭'),(00002,'萧锋','阿朱','睡觉'),(00003,'杨过','小龙女','看书'),(00004,'韦小宝','双双','溜达'),(00005,'郭靖','黄蓉','练舞'),(00006,'欧阳锋','不祥','练武');
1、插入数据
>INSERT INTO tb_name(id,name,score)VALUES(NULL,'张三',140),(NULL,'张四',178),(NULL,'张五',134); //插入多条数据直接在后边加上逗号,主键id是自增的列,可以不用写。 >INSERT INTO tb_name(name,score) SELECT name,score FROM tb_name2;
2、更新数据
>UPDATE tb_name SET score=89,age=11 WHERE id=2; //修改多列使用”,”隔开 >UPDATE tablename SET columnName=NewValue [ WHERE condition ]
3、删除数据
>DELETE FROM tb_name WHERE id=3; >DELETE FROM tb_name; //不带条件,则删除整张表数据
4、查询与条件控制
(1).WHERE 语句:
where的作用:在对查询结果进行分组前,将不符合where条件的行去掉,即在分组之前过滤数据,where条件中不能包含聚组函数。
>SELECT * FROM tb_name WHERE id=3;
(2).HAVING 语句:
having的作用:是筛选满足条件的组,即在分组之后过滤数据,条件中经常包含聚组函数,使用having 条件过滤出特定的组,也可以使用多个分组标准进行分组。
>SELECT * FROM tb_name GROUP BY age HAVING count(*)>2 //按年龄分组,并筛选出同一年龄人数大于2的组数据
(3).相关条件控制符:
=、>、<、<>、IN(1,2,3......)、BETWEEN a AND b、NOT、LIMIT
AND 、OR
Like()用法中
%:匹配任意个字符 _:匹配一个字符(可以是汉字)
IS NULL 空值检测
>SELECT * FROM student WHERE fid >= 3 AND fid <= 5; >SELECT * FROM student WHERE fid IN (2, 4, 5); >SELECT * FROM student WHERE fid BETWEEN 2 AND 4; >SELECT * FROM student WHERE fid = 3 OR fid = 4; >SELECT * FROM student WHERE fname LIKE '%三' //查找fname内容含有三的数据
5.功能函数
(a).DISTINCT:数据去重,返回指定字段内容不重复的记录
>SELECT DISTINCT `age` FROM student; //返回学生年龄分布
(b).LIMIT:指定返回前几条或者中间某几行数据
>SELECT * FROM TABLE LIMIT [OFFSET,] ROWS | ROWS OFFSET OFFSET
LIMIT可以用于强制SELECT返回指定的记录数。接受一个或两个数字参数,参数必须是一个整数常量。如果给定两个参数,第一个参数指定返回记录行的偏移量,第二个参数指定返回记录行的最大数目。
初始记录行偏移量是0(而不是1):为了与PostgreSQL兼容,MySQL也支持句法:LIMIT #OFFSET #。
> SELECT * FROM student LIMIT 5,10; //检索记录行6-15 ,注意:10为偏移量 > SELECT * FROM student LIMIT 95,-1; //检索记录行 96-last. //如果只给定一个参数,它表示返回最大的记录行数目: > SELECT * FROM student LIMIT 5; //检索前 5 个记录行,也就是说,LIMIT n等价于 LIMIT 0,n。
如果你想得到最后几条数据可以多加个 ORDER BY id DESC
(c).as 别名
>SELECT fname AS "名字" FROM student; >SELECT AVG(fchinese) AS "语文平均分" FROM score;
6、GROUP BY分组查询
所谓的分组就是将指定符合条件的数据划分到一个组,最终得到一个分组汇总表
(1).条件使用Having;
(2).排序使用ORDER BY :
ORDER BY DESC|ASC =>按数据的降序/升序排列
>SELECT COUNT(*) FROM student GROUP BY `age` HAVING COUNT(*) > 2; >SELECT fname,COUNT(age) AS "人数" FROM student GROUP BY fname;
7、联合查询用于把来自两个或多个表的行结合起来
(1).使用JOIN
JOIN 子句基于这些表之间的共同字段,把来自两个或多个表的行结合起来。
INNER JOIN
在表中存在至少一个匹配时返回行。
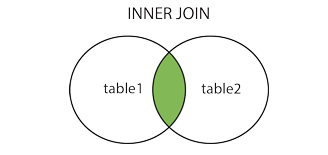
>SELECT student.fname,score.fchinese,score.english,score.fmatch FROM student INNER JOIN score ON student.fid = score.fid; 以上SQL等价于: >SELECT a.fname,a.age,b.fchinese,b.english,b.fmatch FROM student a INNER JOIN score b WHERE a.fid = b.fid; >SELECT a.fname,a.age,b.fchinese,b.english,b.fmatch FROM student a,score b WHERE a.fid = b.fid;
LEFT JOIN
从左表(table1)返回所有的行,即使右表(table2)中没有匹配。如果右表中没有匹配,则结果为 NULL。

>SELECT student.fname,score.fchinese,score.english,score.fmatch FROM student LEFT JOIN score ON student.fid = score.fid;
RIGHT JOIN
从右表(table2)返回所有的行,即使左表(table1)中没有匹配。如果左表中没有匹配,则结果为 NULL。

>SELECT student.fname,score.fchinese,score.english,score.fmatch FROM student RIGHT JOIN score ON student.fid = score.fid;
(2)、使用UNION
UNION
UNION用于合并两个或多个SELECT语句的结果集,并消去表中任何重复行。UNION内部的SELECT 语句必须拥有相同数量的列,列也必须拥有相似的数据类型。同时,每条 SELECT 语句中的列的顺序必须相同.
>SELECT * FROM student UNION SELECT * FROM score; >SELECT * FROM student UNION SELECT * FROM infoext; //报ERROR,列数量不一致
UNION ALL
当ALL随UNION 一起使用时(即UNION ALL),不消除重复行
>SELECT * FROM student UNION ALL SELECT * FROM score;
8、MySQL的一些函数
(1)、字符串链接——CONCAT()
>SELECT CONCAT(fname, "==>", address) FROM student;
(2)、数学函数:AVG、SUM、MAX、MIN、COUNT;
(3)、文本处理函数:TRIM、LOCATE、UPPER、LOWER、SUBSTRING
(4)、运算符:+、-、*、\
(5)、时间函数:DATE()、CURTIME()、DAY()、YEAR()、NOW().....
>UPDATE shop SET `fupdatetime` = NOW(); //更新shop表fupdatetime字段时间
(6)、空值处理
为了处理这种情况,MySQL提供了三大运算符:
IS NULL: 当列的值是NULL,此运算符返回true。
IS NOT NULL: 当列的值不为NULL, 运算符返回true。
<=>: 比较操作符(不同于=运算符),当比较的的两个值为NULL时返回true。
关于NULL的条件比较运算是比较特殊的.你不能使用= NULL或!= NULL在列中查找NULL值,在MySQL中,NULL值与任何其它值的比较(即使是NULL)永远返回false,即 NULL = NULL 返回false.
MySQL中处理NULL使用IS NULL和IS NOT NULL运算符。
>SELECT * FROM student WHERE fname != NULL; //返回NULL数据集 >SELECT * FROM student WHERE fname IS NOT NULL; //返回想要的数据
9、MySQL的正则表达式:
Mysql支持REGEXP的正则表达式:
>SELECT * FROM tb_name WHERE name REGEXP '^[A-D]' //找出以A-D 为开头的name
|
模式 |
描述 |
|
^ |
匹配输入字符串的开始位置。例如’^sw’可匹配swxxs或sw24dsf等 |
|
$ |
匹配输入字符串的结束位置。例如‘duan$’可匹配swduan或sssssduan等 |
|
. |
匹配除 "\n" 之外的任何单个字符。例如’swd.an’可匹配swduan或swddan等 |
|
[...] |
字符集合。匹配所包含的任意一个字符。例如, '[a-z]' 可以匹配字符a-z,[0-9]可匹配0-9。 |
|
[^...] |
非字符集合。匹配除[]中之外的的任意字符。例如, '[^abc]' 可以匹配 "def" 等。 |
|
p1|p2|p3 |
匹配 p1 或 p2 或 p3。例如,'z|food' 能匹配 "z" 或 "food"。'(z|f)ood' 则匹配 "zood" 或 "food"。 |
|
* |
匹配前面的子表达式零次或多次。例如,sw* 能匹配 "sw" 以及 "swsw"。* 等价于{0,}。 |
|
+ |
匹配前面的子表达式一次或多次。例如,'zo+' 能匹配 "zo" 以及 "zozo",但不能匹配 "z"。+ 等价于 {1,}。 |
|
{n} |
n 是一个非负整数。匹配确定的 n 次。例如,'o{2}' 不能匹配 "Bob" 中的 'o',但是能匹配 "food" 中的两个 o。 |
|
{n,m} |
m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。 |
注意,^有两个用法,一个是非,一个是文本的开始,用[]中表示非,否则是文本的开始。
使用的时候需要外面加一层[],例如[[:digit:]]
|
类 |
说明 |
|
[:alnum:] |
任意字母和数字(同[a-zA-Z0-9]) |
|
[:alpha:] |
任意字母(同[a-zA-Z]) |
|
[:blank:] |
空格和制表(同[\\t]) |
|
[:cntrl:] |
ASCII控制字符(ASCII0到31和127) |
|
[:digit:] |
任意数字(同[0-9]) |
|
[:graph:] |
和[[:print:]]相同,但不包含空格 |
|
[:lower:] |
任意小写字母(同[a-z]) |
|
[:print:] |
任意可打印字符 |
|
[:punct:] |
即不在[[:alnum:]]又不在[[:cntrl:]]中的字符 |
|
[:space:] |
包括空格在内的任意空白字符(同[\\f\\n\\r\\t\\v]) |
|
[:upper:] |
任意大写字母(同[A-Z]) |
|
[:xdigit:] |
任意16进制数字(同[a-fA-F0-9]) |
>SELECT * FROM student Where fname REGEXP 'swduan[[:digit:]]'; //可匹配swduan0-9

