16-Python-常用模块
1、模块的定义
模块:用来从逻辑上组织python代码(变量、函数、类、逻辑:实现一个功能),本质就是.py文件(例如文件名:test.py,对应的模块名则为test)。
包:用来从逻辑上组织模块,本质就是一个目录(必须带有一个__init__.py文件)
import模块的本质:导入模块的本质就是把python文件解释一遍。
import包的本质:导入包的本质就是解释包下面的__init__.py文件。
1 import module_druid # 实质是把module_druid中的所有代码都解释了(当前程序中执行)一便,然后赋值给了module_druid。 2 3 print(module_druid.name) # 调用模块中变量的方法。该方法需要加模块名名。 4 5 module_druid.func1() # 调用模块中的方法 6 7 print("华丽的分隔符".center(30, "~")) 8 9 from module_druid import name, func1 # 实质仅是把module_druid模块中的name变量,func1()放到当前程序中执行,而不是全部。 10 11 print(name) # 该方法不需要再加模块名 12 func1() # 该方法不需要再加模块名 13 14 print("华丽的分隔符".center(30, "~")) 15 16 from module_druid import * # 导入模块中所有的代码,在当前程序中执行。不建议这么使用,因为如果有重复的方法,会导致当前方法覆盖导入模块的方法。 17 18 from module_druid import func2 as druid_func2 # 取别名,避免重复 19 druid_func2() 20 21 print("华丽的分隔符".center(30, "~"))
2、time & datetime模块
2.1、 模块的语法
1 import time 2 3 4 print(time.clock()) # 返回处理器时间,3.3开始已废弃 , 改成了time.process_time()测量处理器运算时间,不包括sleep时间,不稳定,mac上测不出来 5 print(time.altzone) # 返回与utc时间的时间差,以秒计算\ 6 print(time.asctime()) # 返回时间格式"Fri Aug 19 11:14:16 2016", 7 print(time.localtime()) # 返回本地时间 的struct time对象格式 8 print(time.gmtime(time.time()-800000)) # 返回utc时间的struc时间对象格式 9 10 print(time.asctime(time.localtime())) # 返回时间格式"Fri Aug 19 11:14:16 2016", 11 print(time.ctime()) # 返回Fri Aug 19 12:38:29 2016 格式, 同上 12 13 14 # 日期字符串 转成 时间戳 15 string_2_struct = time.strptime("2016/05/22", "%Y/%m/%d") # 将日期字符串 转成 struct时间对象格式 16 print(string_2_struct) 17 18 struct_2_stamp = time.mktime(string_2_struct) # 将struct时间对象转成时间戳 19 print(struct_2_stamp) 20 21 22 # 将时间戳转为字符串格式 23 print(time.gmtime(time.time()-86640)) # 将utc时间戳转换成struct_time格式 24 print(time.strftime("%Y-%m-%d %H:%M:%S", time.gmtime())) # 将utc struct_time格式转成指定的字符串格式 25 26 27 #时间加减 28 import datetime 29 30 print(datetime.datetime.now()) # 返回 2016-08-19 12:47:03.941925 31 print(datetime.date.fromtimestamp(time.time())) # 时间戳直接转成日期格式 2016-08-19 32 print(datetime.datetime.now()) 33 print(datetime.datetime.now() + datetime.timedelta(3)) # 当前时间+3天 34 print(datetime.datetime.now() + datetime.timedelta(-3)) # 当前时间-3天 35 print(datetime.datetime.now() + datetime.timedelta(hours=3)) # 当前时间+3小时 36 print(datetime.datetime.now() + datetime.timedelta(minutes=30)) # 当前时间+30分 37 38 39 c_time = datetime.datetime.now() 40 print(c_time.replace(minute=3, hour=2)) # 时间替换
2.2、 参数解释
| Directive | Meaning | Notes |
|---|---|---|
%a |
Locale’s abbreviated weekday name. | |
%A |
Locale’s full weekday name. | |
%b |
Locale’s abbreviated month name. | |
%B |
Locale’s full month name. | |
%c |
Locale’s appropriate date and time representation. | |
%d |
Day of the month as a decimal number [01,31]. | |
%H |
Hour (24-hour clock) as a decimal number [00,23]. | |
%I |
Hour (12-hour clock) as a decimal number [01,12]. | |
%j |
Day of the year as a decimal number [001,366]. | |
%m |
Month as a decimal number [01,12]. | |
%M |
Minute as a decimal number [00,59]. | |
%p |
Locale’s equivalent of either AM or PM. | (1) |
%S |
Second as a decimal number [00,61]. | (2) |
%U |
Week number of the year (Sunday as the first day of the week) as a decimal number [00,53]. All days in a new year preceding the first Sunday are considered to be in week 0. | (3) |
%w |
Weekday as a decimal number [0(Sunday),6]. | |
%W |
Week number of the year (Monday as the first day of the week) as a decimal number [00,53]. All days in a new year preceding the first Monday are considered to be in week 0. | (3) |
%x |
Locale’s appropriate date representation. | |
%X |
Locale’s appropriate time representation. | |
%y |
Year without century as a decimal number [00,99]. | |
%Y |
Year with century as a decimal number. | |
%z |
Time zone offset indicating a positive or negative time difference from UTC/GMT of the form +HHMM or -HHMM, where H represents decimal hour digits and M represents decimal minute digits [-23:59, +23:59]. | |
%Z |
Time zone name (no characters if no time zone exists). | |
%% |
A literal '%' character. |
2.3、 时间格式之间的转换
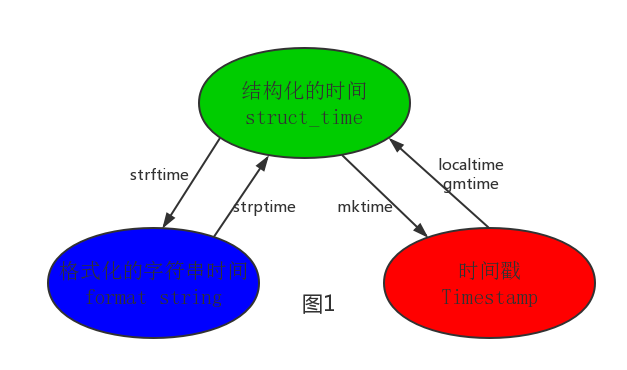
1 import time 2 # --------------------------按图1转换时间 3 # localtime([secs]) 4 # 将一个时间戳转换为当前时区的struct_time。secs参数未提供,则以当前时间为准。 5 time.localtime() 6 time.localtime(1473525444.037215) 7 8 # gmtime([secs]) 和localtime()方法类似,gmtime()方法是将一个时间戳转换为UTC时区(0时区)的struct_time。 9 10 # mktime(t) : 将一个struct_time转化为时间戳。 11 print(time.mktime(time.localtime()))#1473525749.0 12 13 14 # strftime(format[, t]) : 把一个代表时间的元组或者struct_time(如由time.localtime()和 15 # time.gmtime()返回)转化为格式化的时间字符串。如果t未指定,将传入time.localtime()。如果元组中任何一个 16 # 元素越界,ValueError的错误将会被抛出。 17 print(time.strftime("%Y-%m-%d %X", time.localtime()))#2016-09-11 00:49:56 18 19 # time.strptime(string[, format]) 20 # 把一个格式化时间字符串转化为struct_time。实际上它和strftime()是逆操作。 21 print(time.strptime('2011-05-05 16:37:06', '%Y-%m-%d %X')) 22 # time.struct_time(tm_year=2011, tm_mon=5, tm_mday=5, tm_hour=16, tm_min=37, tm_sec=6, 23 # tm_wday=3, tm_yday=125, tm_isdst=-1) 24 # 在这个函数中,format默认为:"%a %b %d %H:%M:%S %Y"。
3、random模块
1 import random 2 3 print(random.random()) # (0,1)----float 大于0且小于1之间的小数 4 5 print(random.randint(1,3)) # [1,3] 大于等于1且小于等于3之间的整数 6 7 print(random.randrange(1,3)) # [1,3) 大于等于1且小于3之间的整数 8 9 print(random.choice([1,'23',[4,5]])) # 1或者23或者[4,5] 10 11 print(random.sample([1,'23',[4,5]],2)) # 列表元素任意2个组合 12 13 print(random.uniform(1,3)) # 大于1小于3的小数,如1.927109612082716 14 15 16 item=[1,3,5,7,9] 17 random.shuffle(item) # 打乱item的顺序,相当于"洗牌" 18 print(item)
生成随机验证码:
1 import random 2 3 4 # 以下代码生成六位随机验证码 5 Random_Code = "" 6 7 for i in range(6): 8 tmp = random.randint(0, 9) 9 Random_Code += str(tmp) # 字符串拼接 10 11 print(Random_Code) 12 13 14 # 以下代码生成字母和数字的随机验证码 15 Random_Mix_Code = "" 16 17 for i in range(6): 18 random_num = random.randrange(0, 6) 19 if i == random_num: # 如果随机数和i一样 20 TMP = chr(random.randint(65, 90)) # 添加字母 21 else: 22 TMP = random.randint(0, 9) 23 Random_Mix_Code += str(TMP) # 字符串拼接 24 25 print(Random_Mix_Code)
4、OS模块
1 os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径 2 os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd 3 os.curdir 返回当前目录: ('.') 4 os.pardir 获取当前目录的父目录字符串名:('..') 5 os.makedirs('dirname1/dirname2') 可生成多层递归目录 6 os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推 7 os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname 8 os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname 9 os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印 10 os.remove() 删除一个文件 11 os.rename("oldname","newname") 重命名文件/目录 12 os.stat('path/filename') 获取文件/目录信息 13 os.sep 输出操作系统特定的路径分隔符,windows下为反斜杠"\\",Linux下为斜杠"/" 14 os.linesep 输出当前平台使用的行终止符,winows下为反斜杠"\t\n",Linux下为斜杠"\n" 15 os.pathsep 输出用于分割文件路径的字符串 winows下为";",Linux下为":" 16 os.name 输出字符串指示当前使用平台。windows->'nt'; Linux->'posix' 17 os.system("bash command") 运行shell命令,直接显示 18 os.environ 获取系统环境变量 19 os.path.abspath(path) 返回path规范化的绝对路径 20 os.path.split(path) 将path分割成目录和文件名二元组返回 21 os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素 22 os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素 23 os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False 24 os.path.isabs(path) 如果path是绝对路径,返回True 25 os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False 26 os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False 27 os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略 28 os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间 29 os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间 30 os.path.getsize(path) 返回path的大小
在Linux和Mac平台上,该函数会原样返回path,在windows平台上会将路径中所有字符转换为小写,并将所有斜杠转换为饭斜杠。
>>> os.path.normcase('c:/windows\\system32\\')
'c:\\windows\\system32\\'
规范化路径,如..和/
>>> os.path.normpath('c://windows\\System32\\../Temp/')
'c:\\windows\\Temp'
>>> a='/Users/jieli/test1/\\\a1/\\\\aa.py/../..'
>>> print(os.path.normpath(a))
/Users/jieli/test1
5、SYS模块
1 sys.argv 命令行参数List,第一个元素是程序本身路径 2 sys.exit(n) 退出程序,正常退出时exit(0) 3 sys.version 获取Python解释程序的版本信息 4 sys.maxint 最大的Int值 5 sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 6 sys.platform 返回操作系统平台名称 7 8 # 打印进度条 9 import sys,time 10 for i in range(20): 11 sys.stdout.write("#") 12 sys.stdout.flush() #实时刷新输出至屏幕 13 time.sleep(0.2) 14 print("\n")
6、shutil模块
请猛击--->http://www.cnblogs.com/linhaifeng/articles/6384466.html
7、json & pickle模块
7.1、eval方法
之前我们学习过用eval内置方法可以将一个字符串转成python对象,不过,eval方法是有局限性的,对于普通的数据类型,json.loads和eval都能用,但遇到特殊类型的时候,eval就不管用了,所以eval的重点还是通常用来执行一个字符串表达式,并返回表达式的值。
1 dic = '{"username": "test"}' 2 print(dic, type(dic)) 3 print(eval(dic), type(eval(dic))) 4 5 li1 = "[1,2,3,4,5]" 6 print(li1, type(li1)) 7 print(eval(li1), type(eval(li1))) 8 9 10 dic1 = { 11 "username": "druid", 12 "age": 25 13 } 14 with open("test.txt", "w") as f: 15 # f.write(dic1),不能直接将字典写入文件 16 f.write(str(dic1)) # 用str方法将字典序列化成字符串 17 18 print("----------我是分隔符------------") 19 20 with open("test.txt", "r") as f1: 21 res = f1.read() 22 print(res, type(res)) 23 # res["username"],res为str,不能取出对应的value 24 res = eval(res) # 反序列化 25 print(res, type(res)) 26 print(res["username"]) # 成功取出value
# eval()方法的局限性
import json
x="[null,true,false,1]"
print(eval(x)) #报错,无法解析null类型,而json就可以
print(json.loads(x))
7.2、 什么是序列化和反序列化
我们把对象(变量)从内存中变成可存储或传输的过程称之为序列化,在Python中叫pickling,在其他语言中也被称之为serialization,marshalling,flattening等等,都是一个意思。为什么要序列化?
1:持久保存状态
需知一个软件/程序的执行就在处理一系列状态的变化,在编程语言中,'状态'会以各种各样有结构的数据类型(也可简单的理解为变量)的形式被保存在内存中。
内存是无法永久保存数据的,当程序运行了一段时间,我们断电或者重启程序,内存中关于这个程序的之前一段时间的数据(有结构)都被清空了。
在断电或重启程序之前将程序当前内存中所有的数据都保存下来(保存到文件中),以便于下次程序执行能够从文件中载入之前的数据,然后继续执行,这就是序列化。
具体的来说,你玩使命召唤闯到了第13关,你保存游戏状态,关机走人,下次再玩,还能从上次的位置开始继续闯关。或如,虚拟机状态的挂起等。
2:跨平台数据交互
序列化之后,不仅可以把序列化后的内容写入磁盘,还可以通过网络传输到别的机器上,如果收发的双方约定好实用一种序列化的格式,那么便打破了平台/语言差异化带来的限制,实现了跨平台数据交互。
反过来,把变量内容从序列化的对象重新读到内存里称之为反序列化,即unpickling。
7.3、 json
如果我们要在不同的编程语言之间传递对象,就必须把对象序列化为标准格式,比如XML,但更好的方法是序列化为JSON,因为JSON表示出来就是一个字符串,可以被所有语言读取,也可以方便地存储到磁盘或者通过网络传输。JSON不仅是标准格式,并且比XML更快,而且可以直接在Web页面中读取,非常方便。
JSON表示的对象就是标准的JavaScript语言的对象,JSON和Python内置的数据类型对应如下:


序列化:
1 import json 2 3 4 dic = { 5 "key1": "value1", 6 "key2": "value2", 7 } 8 result = json.dumps(dic) # 将python基本数据类型序列化(转换成字符串) 9 print(dic, type(dic)) 10 print(result, type(result)) # 格式为字符串 11 12 with open("json1.txt", "w") as f: 13 json.dump(dic, f) # dump的作用有两种,先将dic序列化,再写入文件中
反序列化:
1 import json 2 3 with open("json1.txt", "r") as f2: 4 res = json.load(f2) # load的作用有两种,先将文件读取并放到内存,再反序列化 5 print(res, type(res)) 6 print(res["key1"]) 7 8 9 dic4 = '{"key1": "value1","key2": "value2"}' 10 res4 = json.loads(dic4) 11 print(res, type(res)) 12 print(res4["key1"]) 13 14 # 也可以用下面的方法 15 with open("json1.txt", "r") as f3: 16 res3 = f3.read() # 先从文件中读取并放到内存 17 res33 = json.loads(res3) #再反序列化 18 print(res33, type(res33)) 19 print(res33["key2"])
# 需要注意,要反序列话的内容只能是'',不能是"":
li = '["alex","eric"]' # li = "['alex','eric']"这个写法会报错,这样写法在跨语言的时候容易出错。因为其他的语言''表示字符,""才表示字符串。
ret = json.loads(li)
7.4 pickle

序列化:
1 import pickle 2 3 dic={'name':'alvin','age':23,'sex':'male'} 4 5 print(type(dic))#<class 'dict'> 6 7 j=pickle.dumps(dic) 8 print(type(j))#<class 'bytes'> 9 10 # 序列化 11 def func1(name): 12 print("你好,%s" % name) 13 14 dic1 = { 15 "username": "druid", 16 "age": 25, 17 "func": func1, 18 } 19 20 21 with open("pickle.txt", "wb") as fp: # 要使用二进制写 22 pickle.dump(dic1, fp) # dump的作用有两种,先将字典序列化,再写入文件 23 24 # 也可以使用如下的方法 25 dic11 = pickle.dumps(dic1) # 先序列化 26 print(dic11) 27 with open("pickle1.txt", "wb") as fp1: # 要使用二进制写 28 fp1.write(dic11) # 再写
反序列化:
1 import pickle 2 3 4 def func1(name): # 因为反序列化的时候,程序获取不了序列化时函数的内存地址,因此只有将函数添加到程序中。这里的函数名必须一致,但是函数体内容可以不一致。 5 print("你好,%s" % name) 6 print("你好啊%s" % name) 7 8 9 with open("pickle.txt", "rb") as f: 10 res = pickle.load(f) 11 print(res, type(res)) 12 print(res["func"]("druid"))
8、shelve模块
shelve模块比pickle模块简单,只有一个open函数,返回类似字典的对象,可读可写;key必须为字符串,而值可以是python所支持的数据类型。
import shelve f=shelve.open(r'sheve.txt') # f['stu1_info']={'name':'egon','age':18,'hobby':['piao','smoking','drinking']} # f['stu2_info']={'name':'gangdan','age':53} # f['school_info']={'website':'http://www.pypy.org','city':'beijing'} print(f['stu1_info']['hobby']) f.close()
9、XML模块、configparser模块、hashlib模块、suprocess模块、logging模块
请猛击--->http://www.cnblogs.com/linhaifeng/articles/6384466.html & http://www.cnblogs.com/alex3714/articles/5161349.html
10、RE模块
10.1、关键字

10.2、语法
1 # =================================匹配模式 2 #一对一的匹配 3 # 'hello'.replace(old,new) 4 # 'hello'.find('pattern') 5 6 #正则匹配 7 import re 8 #\w与\W 9 print(re.findall('\w','hello egon 123')) #['h', 'e', 'l', 'l', 'o', 'e', 'g', 'o', 'n', '1', '2', '3'] 10 print(re.findall('\W','hello egon 123')) #[' ', ' '] 11 12 #\s与\S 13 print(re.findall('\s','hello egon 123')) #[' ', ' ', ' ', ' '] 14 print(re.findall('\S','hello egon 123')) #['h', 'e', 'l', 'l', 'o', 'e', 'g', 'o', 'n', '1', '2', '3'] 15 16 #\n \t都是空,都可以被\s匹配 17 print(re.findall('\s','hello \n egon \t 123')) #[' ', '\n', ' ', ' ', '\t', ' '] 18 19 #\n与\t 20 print(re.findall(r'\n','hello egon \n123')) #['\n'] 21 print(re.findall(r'\t','hello egon\t123')) #['\n'] 22 23 #\d与\D 24 print(re.findall('\d','hello egon 123')) #['1', '2', '3'] 25 print(re.findall('\D','hello egon 123')) #['h', 'e', 'l', 'l', 'o', ' ', 'e', 'g', 'o', 'n', ' '] 26 27 #\A与\Z 28 print(re.findall('\Ahe','hello egon 123')) #['he'],\A==>^ 29 print(re.findall('123\Z','hello egon 123')) #['he'],\Z==>$ 30 31 #^与$ 32 print(re.findall('^h','hello egon 123')) #['h'] 33 print(re.findall('3$','hello egon 123')) #['3'] 34 35 # 重复匹配:| . | * | ? | .* | .*? | + | {n,m} | 36 #. 37 print(re.findall('a.b','a1b')) #['a1b'] 38 print(re.findall('a.b','a1b a*b a b aaab')) #['a1b', 'a*b', 'a b', 'aab'] 39 print(re.findall('a.b','a\nb')) #[] 40 print(re.findall('a.b','a\nb',re.S)) #['a\nb'] 41 print(re.findall('a.b','a\nb',re.DOTALL)) #['a\nb']同上一条意思一样 42 43 #* 44 print(re.findall('ab*','bbbbbbb')) #[] 45 print(re.findall('ab*','a')) #['a'] 46 print(re.findall('ab*','abbbb')) #['abbbb'] 47 48 #? 49 print(re.findall('ab?','a')) #['a'] 50 print(re.findall('ab?','abbb')) #['ab'] 51 #匹配所有包含小数在内的数字 52 print(re.findall('\d+\.?\d*',"asdfasdf123as1.13dfa12adsf1asdf3")) #['123', '1.13', '12', '1', '3'] 53 54 #.*默认为贪婪匹配 55 print(re.findall('a.*b','a1b22222222b')) #['a1b22222222b'] 56 57 #.*?为非贪婪匹配:推荐使用 58 print(re.findall('a.*?b','a1b22222222b')) #['a1b'] 59 60 #+ 61 print(re.findall('ab+','a')) #[] 62 print(re.findall('ab+','abbb')) #['abbb'] 63 64 #{n,m} 65 print(re.findall('ab{2}','abbb')) #['abb'] 66 print(re.findall('ab{2,4}','abbb')) #['abb'] 67 print(re.findall('ab{1,}','abbb')) #'ab{1,}' ===> 'ab+' 68 print(re.findall('ab{0,}','abbb')) #'ab{0,}' ===> 'ab*' 69 70 #[] 71 print(re.findall('a[1*-]b','a1b a*b a-b')) #[]内的都为普通字符了,且如果-没有被转意的话,应该放到[]的开头或结尾 72 print(re.findall('a[^1*-]b','a1b a*b a-b a=b')) #[]内的^代表的意思是取反,所以结果为['a=b'] 73 print(re.findall('a[0-9]b','a1b a*b a-b a=b')) #[]内的^代表的意思是取反,所以结果为['a=b'] 74 print(re.findall('a[a-z]b','a1b a*b a-b a=b aeb')) #[]内的^代表的意思是取反,所以结果为['a=b'] 75 print(re.findall('a[a-zA-Z]b','a1b a*b a-b a=b aeb aEb')) #[]内的^代表的意思是取反,所以结果为['a=b'] 76 77 #\# print(re.findall('a\\c','a\c')) #对于正则来说a\\c确实可以匹配到a\c,但是在python解释器读取a\\c时,会发生转义,然后交给re去执行,所以抛出异常 78 print(re.findall(r'a\\c','a\c')) #r代表告诉解释器使用rawstring,即原生字符串,把我们正则内的所有符号都当普通字符处理,不要转义 79 print(re.findall('a\\\\c','a\c')) #同上面的意思一样,和上面的结果一样都是['a\\c'] 80 81 #():分组 82 print(re.findall('ab+','ababab123')) #['ab', 'ab', 'ab'] 83 print(re.findall('(ab)+123','ababab123')) #['ab'],匹配到末尾的ab123中的ab 84 print(re.findall('(?:ab)+123','ababab123')) #findall的结果不是匹配的全部内容,而是组内的内容,?:可以让结果为匹配的全部内容 85 86 #| 87 print(re.findall('compan(?:y|ies)','Too many companies have gone bankrupt, and the next one is my company'))
# ===========================re模块提供的方法介绍 import re #1 print(re.findall('e','alex make love') ) #['e', 'e', 'e'],返回所有满足匹配条件的结果,放在列表里 #2 print(re.search('e','alex make love').group()) #e,只到找到第一个匹配然后返回一个包含匹配信息的对象,该对象可以通过调用group()方法得到匹配的字符串,如果字符串没有匹配,则返回None。 #3 print(re.match('e','alex make love')) #None,同search,不过在字符串开始处进行匹配,完全可以用search+^代替match #4 print(re.split('[ab]','abcd')) #['', '', 'cd'],先按'a'分割得到''和'bcd',再对''和'bcd'分别按'b'分割 #5 print('===>',re.sub('a','A','alex make love')) #===> Alex mAke love,不指定n,默认替换所有 print('===>',re.sub('a','A','alex make love',1)) #===> Alex make love print('===>',re.sub('a','A','alex make love',2)) #===> Alex mAke love print('===>',re.sub('^(\w+)(.*?\s)(\w+)(.*?\s)(\w+)(.*?)$',r'\5\2\3\4\1','alex make love')) #===> love make alex print('===>',re.subn('a','A','alex make love')) #===> ('Alex mAke love', 2),结果带有总共替换的个数 #6 obj=re.compile('\d{2}') print(obj.search('abc123eeee').group()) #12 print(obj.findall('abc123eeee')) #['12'],重用了obj
1 import re 2 print(re.findall("<(?P<tag_name>\w+)>\w+</(?P=tag_name)>","<h1>hello</h1>")) #['h1'] 3 print(re.search("<(?P<tag_name>\w+)>\w+</(?P=tag_name)>","<h1>hello</h1>").group()) #<h1>hello</h1> 4 print(re.search("<(?P<tag_name>\w+)>\w+</(?P=tag_name)>","<h1>hello</h1>").groupdict()) #<h1>hello</h1> 5 6 print(re.search(r"<(\w+)>\w+</(\w+)>","<h1>hello</h1>").group()) 7 print(re.search(r"<(\w+)>\w+</\1>","<h1>hello</h1>").group()) 8 9 补充一
1 import re 2 3 print(re.findall(r'-?\d+\.?\d*',"1-12*(60+(-40.35/5)-(-4*3))")) #找出所有数字['1', '-12', '60', '-40.35', '5', '-4', '3'] 4 5 6 #使用|,先匹配的先生效,|左边是匹配小数,而findall最终结果是查看分组,所有即使匹配成功小数也不会存入结果 7 #而不是小数时,就去匹配(-?\d+),匹配到的自然就是,非小数的数,在此处即整数 8 print(re.findall(r"-?\d+\.\d*|(-?\d+)","1-2*(60+(-40.35/5)-(-4*3))")) #找出所有整数['1', '-2', '60', '', '5', '-4', '3'] 9 10 补充二
1 #为何同样的表达式search与findall却有不同结果: 2 print(re.search('\(([\+\-\*\/]*\d+\.?\d*)+\)',"1-12*(60+(-40.35/5)-(-4*3))").group()) #(-40.35/5) 3 print(re.findall('\(([\+\-\*\/]*\d+\.?\d*)+\)',"1-12*(60+(-40.35/5)-(-4*3))")) #['/5', '*3'] 4 5 #看这个例子:(\d)+相当于(\d)(\d)(\d)(\d)...,是一系列分组 6 print(re.search('(\d)+','123').group()) #group的作用是将所有组拼接到一起显示出来 7 print(re.findall('(\d)+','123')) #findall结果是组内的结果,且是最后一个组的结果 8 9 search与findall

 浙公网安备 33010602011771号
浙公网安备 33010602011771号