Spark三种运行模式详解和实例
1、Spark的三种运行模式
1.1、Local模式
单机运行,通常用于测试。
1.2、Standalone模式
独立运行在一个spark的集群中。
1.3、Spark on Yarn/Mesos模式
Spark程序运行在资源管理器上,例如YARN/Mesos
Spark on Yarn存在两种模式
• yarn-client
• yarn-cluster
2.安装spark,并启动spark-shell;分别用local/standalone/yarn模式运行workcount。
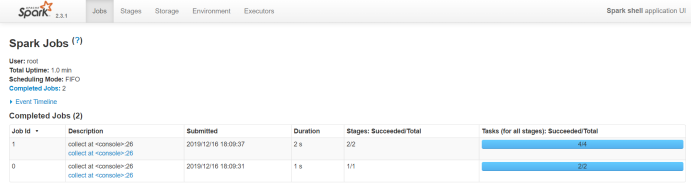
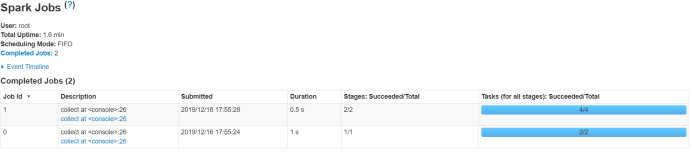
1)截取spark-UI执行进度。
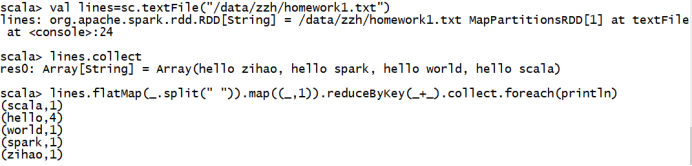
2)截取执行成功后输出的结果。
3)Spark on yarn模式,截取8088端口页面的截图。
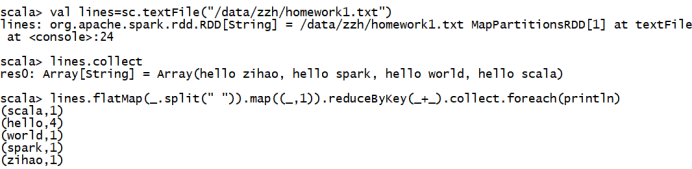
Local模式:

standalone模式:

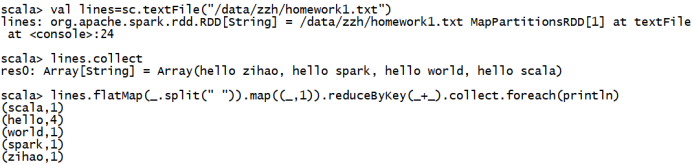
yarn模式

3.请对Spark的RDD做简要的概述。
RDD 是 Spark 提供的最重要的抽象概念,它是一种有容错机制的特殊数据集合,可以分布在集群的结点上,以函数式操作集合的方式进行各种并行操作。
通俗点来讲,可以将 RDD 理解为一个分布式对象集合,本质上是一个只读的分区记录集合。每个 RDD 可以分成多个分区,每个分区就是一个数据集片段。一个 RDD 的不同分区可以保存到集群中的不同结点上,从而可以在集群中的不同结点上进行并行计算。
4.请对Saprk的Transformation和Action做简要描述,以及spark的懒执行是什么?
1、spark的transformation
Transformation用于对RDD的创建,RDD只能使用Transformation创建,同时还提供大量操作方法,包括map,filter,groupBy,join等,RDD利用这些操作生成新的RDD,但是需要注意,无论多少次Transformation,在RDD中真正数据计算Action之前都不可能真正运行。
2、Spark的action
Action是数据执行部分,其通过执行count,reduce,collect等方法真正执行数据的计算部分。实际上,RDD中所有的操作都是Lazy模式进行,运行在编译中不会立即计算最终结果,而是记住所有操作步骤和方法,只有显示的遇到启动命令才执行。这样做的好处在于大部分前期工作在Transformation时已经完成,当Action工作时,只需要利用全部自由完成业务的核心工作。
3、懒执行
Spark中,Transformation方法都是懒操作方法,比如map,flatMap,reduceByKey等。当触发某个Action操作时才真正执行。
①不运行job就触发计算,避免了大量的无意义的计算,即避免了大量的无意义的中间结果的产生,即避免产生无意义的磁盘I/O及网络传输
②更深层次的意义在于,执行运算时,看到之前的计算操作越多,执行优化的可能性就越高

