【中英双语】Spark官方文档解读(一)——Spark概述
文章目录
如果你从本文中学习到丝毫知识,那么请您点点关注、点赞、评论和收藏
大家好,我是爱做梦的鱼,我是东北大学大数据实验班大三的小菜鸡,非常渴望优秀,羡慕优秀的人。从5月25号我们开始了为期两个月的实习,我们需要做一个大型大数据项目,一个项目由三个学生+一个企业的项目经理完成。请大家持续关注我的专栏,我会每天更新。
专栏:大数据案例实战——大三春招大数据开发
专栏:Spark官方文档解读【Spark2.4.5中英双语】
博客地址:子浩的博客https://blog.csdn.net/weixin_43124279
欢迎大家关注微信公众号【程序猿干货铺】
一群热爱技术并且向往优秀的程序猿同学,不喜欢水文,不喜欢贩卖焦虑,只喜欢谈技术,分享的都是技术干货。Talk is cheap. Show me the code

Apache Spark™ is a unified analytics engine for large-scale data processing.
Apache Spark™是用于大规模数据处理的统一分析引擎。
1. Speed
Run workloads 100x faster.
Apache Spark achieves high performance for both batch and streaming data, using a state-of-the-art DAG scheduler, a query optimizer, and a physical execution engine.
1. 速度
运行工作负载的速度提高了100倍。
Apache Spark使用最新的DAG调度程序,查询优化器和物理执行引擎,可实现批处理和流数据的高性能。
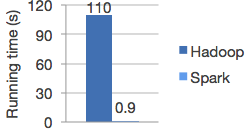
Logistic regression in Hadoop and Spark
Hadoop和Spark中的逻辑回归
2. Ease of Use
Write applications quickly in Java, Scala, Python, R, and SQL.
Spark offers over 80 high-level operators that make it easy to build parallel apps. And you can use it interactively from the Scala, Python, R, and SQL shells.
2. 使用方便
使用Java,Scala,Python,R和SQL快速编写应用程序。
Spark提供了80多个高级算子,可轻松构建并行应用程序。 您可以从Scala,Python,R和SQL Shell交互使用它。
df = spark.read.json("logs.json")
df.where("age > 21").select("name.first").show()
# Spark's Python DataFrame API
# Read JSON files with automatic schema inference
# Spark的Python DataFrame API通过自动模式推断读取JSON文件
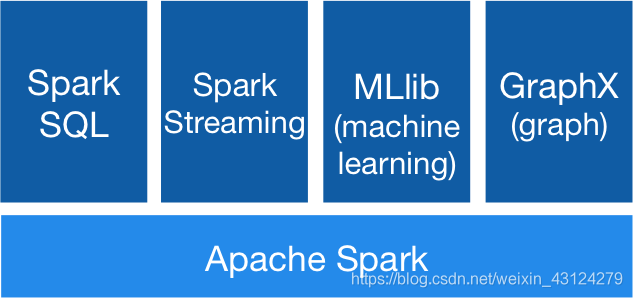
3. Generality
Combine SQL, streaming, and complex analytics.
Spark powers a stack of libraries including SQL and DataFrames, MLlib for machine learning, GraphX, and Spark Streaming. You can combine these libraries seamlessly in the same application.
3. 通用性
结合SQL、流和复杂分析。
Spark为一堆库提供了支持,包括SQL和DataFrames、用于机器学习的MLlib、GraphX和Spark Streaming。您可以在同一个应用程序中无缝地组合这些库。
4. Runs Everywhere
Spark runs on Hadoop, Apache Mesos, Kubernetes, standalone, or in the cloud. It can access diverse data sources.
You can run Spark using its standalone cluster mode, on EC2, on Hadoop YARN, on Mesos, or on Kubernetes. Access data in HDFS, Alluxio, Apache Cassandra, Apache HBase, Apache Hive, and hundreds of other data sources.
4. 运行在所有地方
Spark可在Hadoop,Apache Mesos,Kubernetes,单机或云中运行。 它可以访问各种数据源。
您可以在EC2,Hadoop YARN,Mesos或Kubernetes上使用Spark的独立集群模式运行它。 访问HDFS,Alluxio,Apache Cassandra,Apache HBase,Apache Hive和数百种其他数据源中的数据。
个人总结
Spark 作为下一代大数据处理引擎,在非常短的时间里崭露头角,并且以燎原之势席卷业界。Spark 对曾经引爆大数据产业革命的 Hadoop MapReduce 的改进主要体现在这几个方面:
- 首先,Spark 速度很快,支持交互式使用和复杂算法。
- 其次,Spark 非常好用。Spark 丰富的 API 带来了更强大的易用性。由于高级 API 剥离了对集群本身的关注,你可以专注于你所要做的计算本身,只需在自己的笔记本电脑上就可以开发Spark 应用。
- 最后,Spark 是一个通用引擎, Spark 不单单支持传统批处理应用,更支持交互式查询、流式计算、机器学习、图计算等各种应用,满足各种不同应用场景下的需求。而在Spark 出现之前,我们一般需要学习各种各样的引擎来分别处理这些需求。
- Spark基本可以运行在所有地方

