

与具体的编码数据空间相比,jpeg文件头占据非常小乃至可以忽略不计的大小。
仍然拿JPEG解码--(1)JPEG文件格式概览中的《animal park》这张图片来举例,从跳过SOS(FF DA)的TAG开始——offset=0x153,
就真正进入了编码数据区域,如下图所示:

其占据的比例为:0x153/0x9721 = 339/38689 = 0.876%,还不到1%,其他jpeg图片也是类似情况。
但是,就是这么小的数据区域,却是至关重要的地方,某些关键的地方一个字节出错了的话,解码就会出错(例如huffman table
中数据),或者重建出的yuv图像异常(例如quantization table中数据)!
本篇是该系列的第三篇,主要介绍jpeg头信息解析,其中除了huffman table重建较复杂外,其他TAG的解析都比较容易。
1. APP0——FF EO
先贴出这段区域:

从ASCII值可以看出,保存了JFIF——JPEG File Interchange Format(JPEG文件交换格式),后面的几个字节应该是version信
息吧,没深究。
2. DQT——FF DB
量化表有两个,上面贴图只高亮了其中一个表。
从offset=0x16开始的两个字节(0x00 43)为这段区域的size=67,后面的一个字节为表的ID——0x00=0(可以看到第二张表中对
应位置offset=0x5D处为0x1)。
跳过前面三字节从offset=0x19处开始的64字节,即为量化表中量化值。其中需要说明的是,量化值是固定为64字节的,因为按8X8
进行DCT变换的。
工具解析的结果如下:
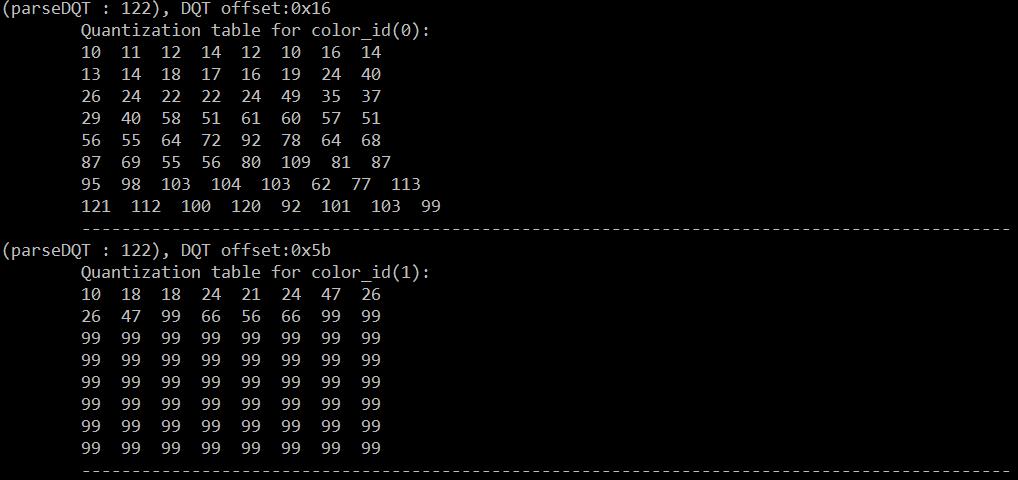
需要补充两点:
A.亮度信号的Y分量使用DQT表一,UV分量使用表二。
B.亮度信号通常采用细量化(量化值较小),对应位置处,表一通常比表二值要小。此量化原因是人眼对亮度信号比较敏感,采用颗粒度
较细来量化,细量化引入的一个问题会消耗更多的数据空间。
3. SOF——FF C0

在该JPEG解码系列中第一篇已经详细介绍过了,不再赘述。工具解析如下:

4. DHT——FF C4

共有四张表,上面只贴出第一张表。
DHT表的重建有些复杂,涉及底层更多关于数据压缩领域的知识,可以参考“范式霍夫曼编码”相关材料,本博文不再做介绍该编码原理。
但会针对具体个例进行说明,如果重建霍夫曼表。这是至关重要的一环,因为关系着后面霍夫曼解码,如果表有误,后面会解码异常。
4.1 表分类
重建霍夫曼表。一般分为四个表:DC0,DC1,AC0,AC1,因为Y分量使用两个表:DC0+AC0,而UV分量也使用两个表:DC1+AC1。
4.2 几个名词及解释
这个几个名词是个人按照自己的理解来定义的,读者需按照这个来解读,因为我的解码工具就是按照这个来使用的。
例如,parseDHT显示的下图:
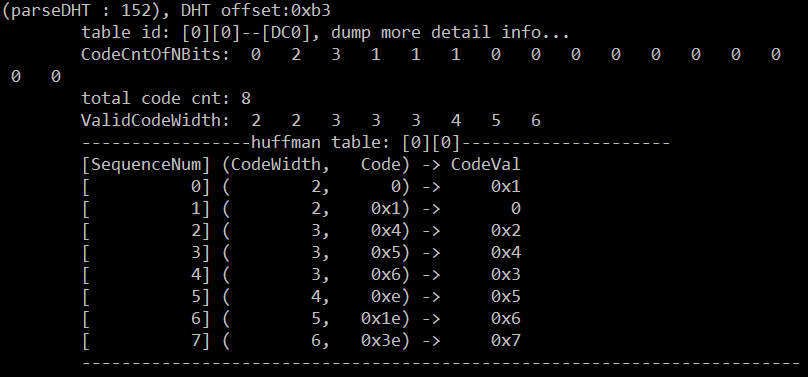
几个名词:序号(SequenceNum)、码字长度(CodeWidth)、码字(Code)、信源值/权值(CodeVal)。
SequenceNum:序号,依次递增,从0到totalCodeCnt-1。totalCodeCnt值不确定,取决于编码端编码出的数量。
上面图示的第一列数字,是依次递增的,多一个编码数据就多一行。
CodeWidth: 编码数据的宽度(码字宽度——二进制数据的bit位宽),宽度都是从2开始,最大为16。当某个码字Code的宽度为16时,表示用16位的
编码数据来表示某个像素值(确切讲并不是像素值,而是RLE的值!),当然,其出现的概率非常低,否则会出现编码数据量大于信源数据量了。
另外,码字宽度必须是依次递增的,中间不可能有跳变,因为霍夫曼编码理论上会尽量用较窄的码字来表示信源。-->也有可能产生跳变!
但一般概率较低,曾经遇到过。
相同码字宽度的若干码字,其码字依次递增。例如,图示第3-5行,码字宽度为3,其对应的码字为0x4,0x5,0x6,即二进制:100,101,110。
Question:每当码字宽度加一时,码字如何变化?
上一个码字值加1后,末尾再补一个零(即——加1右移)。当宽度增加二时,先将上一个码字值加1后再补两个零。增加三时类似,但出现
概率极低。例如上图中,从CodeWidth中2->3过渡,Code值变化为:01 -> 100;从CodeWidth的3 -> 4过渡,Code值变化为:110 ->1110。
值得注意的一点:码字宽度,不一定都是依次递增,有可能产生跳变,目的是使后面的码字不溢出,也就是补两个或多个零的情况。
Code: 码字,全部码字要求各不相等。因其是编码数据,而霍夫曼编码要求读取的完整的n位比特位的码字Code,不能与其他码字Code的前n位相等,
因此宽度值从2位的00开始。
例如,上面码字Code中间的四行分别为:0x5,0x6,0xe,0x1e,(二进制表示:101,110,1110,11110)的编码数据,其真正代表的CodeVal信源
值为4,3,5,6。由此也可以看出,信源值4出现的频率/概率最高(如果仅仅这四个做比较的话是这样(再极端情况是:P4=P3>P5>P6),如果通盘比较,
当然是第一行0x1出现的概率最大),因为要用最小(最窄)的编码数据来表示频率最高的信源值。这是huffman编码理论中的一个核心概念——出现概率最大
的值的编码宽度最窄,这样最利于压缩数据。
CodeVal:信源值(应该是接近信源的值,不是量化后的值,其值是RLE行程编码值,由两部分组成,高四位和低四位)。
即编码内容,也是霍夫曼树叶子节点权值,在解码时需要用Code来恢复出这种值。
该值的宽度由量化精度决定,通常为8位,代表yuv图形单个像素值采样精度为8位,该值是唯一的,不能重复。——》 描述错误,不是这种情况,后面再解释。
4.3 重建步骤
以例子来展示,不使用《animal park》,使用如下这一串值(红色➕号分割不同意义的值,我自己添加的):
FF C4 00 1D 00 00 03 01 01 01 01 01 01 01 00 00 00 00 00 00 00 + 04 05 06 03 02 01 00 09 07 08
step1. 剔除掉表示size的00 1D以及表示table_id的00,剩余: 00 03 01 01 01 01 01 01 01 00 00 00 00 00 00 00 + 04 05 06 03 02 01 00 09 07 08
其中,前16个数值表示含义————码字宽度(CodeWidth)为n的码字(Code)的数量,其中n从1递增到16(可以表示为该位置的index,但是其是从1开始递增),
因为最小宽度为1,最大宽度为16。
通常,宽度为1的码字不会使用,而编码是从2位开始,例如第一个码字通常为0b00,来表示出现频率最高的那个信源值。有些位置上的值为0,表示该码字宽度无
对应的码字,像第一个位置和最后7个位置的0,就没有对应的码字。
从上面分析,可以得到结论:总共使用码字的数量————16个位置上的数值之和,也即是totalCodeCnt=10(3+1+1+1+1+1+1+1),也是霍夫曼树中叶子节点的个数。
step2. 前16个字节后面的若干个字节数据:04 05 06 03 02 01 00 09 07 08
其表示码字宽度依次递增时所对应的信源值(CodeVal),其数量必然等于totalCodeCnt,因为一个有效码字(前16Byte不为0的)对应一个信源值。
step3. 对应关系生成
前16Bytes的第2个位置的03,代表码字宽度为2的码字数量为3,那么其分别为:0b00,0b01,0b10,其对应的信源值分别为后面的0x04,0x05,0x06
。。。。。。3。。。 。01。。。。。。。。3。。。 。。。1 。。。。。。。0b110。。。。。。。。。。。。。。。。。。。 。0x03
。。。。。。4。。。。 01。。。。。。。。4。。。。。。1。。。。。。。。 0b1110。。。。。。。。。。。。。。。。。。。0x02
以此类推,直到最后一个码字宽度为9的码字0x1fe,以及其代表的信源值0x08。
4.4 重建算法
本人工具提供了一个重建huffman表的算法,感兴趣的可以参考。写的不是太简洁,但能正常重建DHT。


1 //rebuild huffman table 2 int parseDHT(ABitReader* abr, struct jpegParam* param) 3 { 4 printf("(%s : %d), DHT offset:%#x\n", __func__, __LINE__, abr->getOffset()); 5 int len = abr->getBits(16); 6 len -= 2; 7 while (len>0) 8 { 9 uint8_t idx = abr->getBits(8); 10 uint8_t idx_high = idx>>4; 11 uint8_t idx_low = idx & 0x0f; 12 13 //idx_hight represent DC or AC: 0-DC, 1-AC 14 //idx_low represent color id: 0-Y, 1-uv 15 //[0][x] -- DC table, [0][0]:DC0, [0][1]:DC1 16 //[1][x] -- AC table, [1][0]:AC0, [1][1]:AC1 17 //generate pHTCodeCnt[idx_high][idx_low] 18 uint8_t *pCodeCnt = (uint8_t*)malloc(16); 19 int i, j; 20 int total_code_cnt = 0; 21 printf("\ttable id: [%d][%d]--[%s%d], dump more detail info...\n", idx_high, idx_low, idx_high==0?"DC":"AC", idx_low); 22 printf("\tCodeCntOfNBits:\t"); 23 for (i=0; i<16; i++) { 24 int code_cnt = abr->getBits(8); 25 pCodeCnt[i] = code_cnt; 26 total_code_cnt += code_cnt; 27 printf("%2d ", code_cnt); 28 } 29 printf("\n\ttotal code cnt: %d\n", total_code_cnt); 30 param->HTCodeRealCnt[idx_high][idx_low] = total_code_cnt; 31 param->pHTCodeCnt[idx_high][idx_low] = pCodeCnt; 32 33 uint8_t *pWidth = (uint8_t *)malloc(total_code_cnt); 34 param->pHTCodeWidth[idx_high][idx_low] = pWidth; 35 printf("\tValidCodeWidth:\t"); 36 for (i=0, j=0; i<16; i++, j=0) { 37 while (j++ < pCodeCnt[i]) { 38 uint8_t tmp = *pWidth++ = i+1; 39 printf("%2d ", tmp); 40 } 41 } 42 puts(""); 43 44 pWidth = param->pHTCodeWidth[idx_high][idx_low]; 45 46 //generate pHTCode[idx_high][idx_low] 47 uint16_t *pCode = (uint16_t*)malloc(2*total_code_cnt); //huffman code width: 2~16 bits -> may 1 bits! but HuffmanDecode3 can not handle this! 48 param->pHTCode[idx_high][idx_low] = pCode; 49 bool init_flag = false; 50 for (i=0; i<16; i++) { 51 int j = 0; 52 uint16_t tmp; 53 while (j++ < pCodeCnt[i]) { 54 if ((i==1 || i==0) && (j==1) && (init_flag==false)) { 55 *pCode = 0; //init val 56 init_flag = true; 57 } else if (j == 1) { //first add x bits 58 int k = i; 59 int shift_bits = 1; 60 while(pCodeCnt[--k] == 0) { 61 shift_bits++; 62 } 63 tmp = (*pCode+1)<<shift_bits; 64 *++pCode = tmp; 65 } else { 66 tmp = *pCode + 1; 67 *++pCode = tmp; 68 } 69 //printf("i:%d, j:%d, (%d , %d) => %#x\n", i, j, pCodeCnt[i], pWidth[i], *pCode); 70 } 71 } 72 73 //generate pHTCodeVal[idx_high][idx_low] 74 uint8_t *pCodeVal = (uint8_t*)malloc(total_code_cnt); //huffman code width: 2~16 bits 75 param->pHTCodeVal[idx_high][idx_low] = pCodeVal; 76 for (i=0; i<total_code_cnt; i++) { 77 *pCodeVal++ = abr->getBits(8); 78 } 79 80 printf("\t-----------------huffman table: [%d][%d]---------------------\n", idx_high, idx_low); 81 82 pWidth = param->pHTCodeWidth[idx_high][idx_low]; 83 pCode = param->pHTCode[idx_high][idx_low]; 84 pCodeVal = param->pHTCodeVal[idx_high][idx_low]; 85 puts("\t[SequenceNum] (CodeWidth, Code) -> CodeVal"); 86 for (i=0; i<total_code_cnt; i++) { 87 printf("\t[%11d] (%9d, %#6x) -> %#7x\n", i, *pWidth++, *pCode++, *pCodeVal++); 88 } 89 len -= (17+total_code_cnt); 90 puts("\t---------------------------------------------------------------------------------------------"); 91 } 92 return 0; 93 }
5. SOS——FF DA

SOS主要描述了分量号与几个DHT表的对应关系,以及编码profile。
其含义如代码所示:
1 //map comp_id to huffman_table 2 int parseSOS(ABitReader* abr, struct jpegParam* param) 3 { 4 printf("(%s : %d), SOS offset:%#x\n", __func__, __LINE__, abr->getOffset()); 5 int len = abr->getBits(16); 6 int comp_cnt = abr->getBits(8); 7 int i; 8 for (i=0; i<comp_cnt; i++) { 9 param->ht_comp_id[i] = abr->getBits(8); 10 CHECK_EQ(param->ht_comp_id[i], i+1); 11 int ht_idx = abr->getBits(8); 12 param->ht_idx[i] = ht_idx; 13 int dc_idx = ht_idx>>4; 14 int ac_idx = ht_idx & 0x0f; 15 printf("\tcolor_id[%d] use DC_table[%d], AC_table[%d]\n", param->ht_comp_id[i], dc_idx, ac_idx); 16 } 17 uint32_t baseline_flag = abr->getBits(24); 18 puts("\tonly support baseline profile! should pass for most cases!"); 19 CHECK_EQ(baseline_flag, 0x003f00); 20 21 return 0; 22 }
需要注意的是,最后3Bytes是描述所用的profile,但是基本上都是使用的baseline,这个值是固定的。
工具解析结果如下:

6. 其他补充
有些图片带缩略图——thumbnail,其存在的目的是解码大图太耗费时间,而如果jpeg图片中还嵌套着另外一份小图(缩略图),则利用该小图解码可以缩短解码大图时间,
来达到尽快展示给用户看的目的。
jpeg文件格式支持这种方式,该小图其实也是一幅分辨率较小的jpeg图片,其一般会放在APP1下的Exif段。
带thumbnail的图片,thumbnail的部分,其完整保留了前面几个小节介绍的各个TAG段。文件中,如果搜索"FF E0",会发现找到两个,一个是主图的,另外一个是缩略图的。

