
【题解】CF319D | 字符串 哈希 观测点检测
CF319D Have You Ever Heard About the Word
好题,涉及复杂度分析,字符串结论,思维量较大。
发现这种操作是不好同时进行的,我们只能较为“愚蠢”地模拟着操作,但是这种操作最多又有可能有 次,直接做的复杂度是 的,但是能过,考虑优化,一个比较好想到的优化是把所有长度为 的 一起缩,
首先若我们从小到大所掉了所有长度为 的串后,接着缩完长为 的串后不可能存在长为 的 串可以再被缩,证明如下:
反证,假设缩完 后有连续串 ,且 :
若 有超出 的部分,则会直接缩掉 ,不符合。
是 的子串,则一定可以选取 的一个子串使得它又是 的前缀又是 的后缀,所以 的拼接处一定存在一个长度小于 的重复没有删除,不符合。
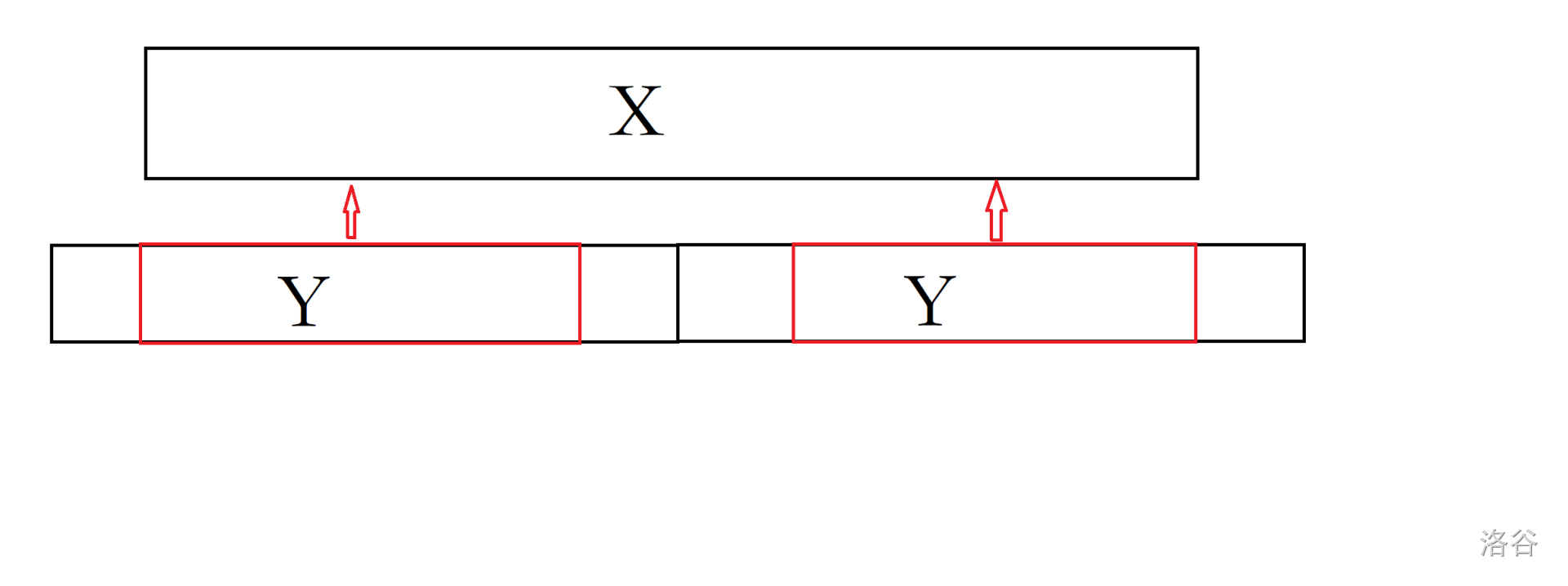
所以上述引理得证。
然后就证明了一件事:从小到大缩掉所有长度为 的串是正确的,长度为 的串是可以通过字符串算法或者相关技巧做到一次缩完,我们稍后讨论。
因为缩掉长度 的 后长度会减少 ,又因为总长是 ,所以所有串串最多有 种不同的长度,因为 。
所以我们每次遇到能删的串串直接遍历全串删就完了,接下来我们要考虑如何判断是否存在 的 串,用一个比较经典的套路就是将串分成长度为 的段,如果某段和前面的 LCP 和 后面段的 LCS 的长度之和不小于 ,那么一定存在一个这样的串,暴力缩长度为 的串,使用双指针或者哈希均可。
这样的观察点总数是 。
然后我们需要一个快速求 LCS、LCP 的算法,设其初始化复杂度为 ,单次查询复杂度为 ,则总复杂度为 ,在这里使用字符串哈希的 优于后缀数组的 ,总复杂度 。
本文已经结束了。本文作者:ღꦿ࿐(DeepSea),转载请注明原文链接:https://www.cnblogs.com/Dreamerkk/p/17107283.html,谢谢你的阅读或转载!



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步