

在第五章,我们学习了树这个数据结构,并且学习了其定义、遍历等操作,最后还学习了哈夫曼树。
一.树的遍历
树的遍历操作有以下三种:
1。先序遍历(根,左孩子,右孩子)
void PreOrderTravel(node t[], int x) { cout << t[x].name << " "; if(t[x].lch!=-1) PreOrderTravel(t, t[x].lch); if(t[x].rch!=-1) PreOrderTravel(t, t[x].rch); }
2。中序遍历(左孩子,根,右孩子)
void InOrderTravel(node t[], int x) { if(t[x].lch!=-1) InOrderTravel(t, t[x].lch); cout << t[x].name << " "; if(t[x].rch!=-1) InOrderTravel(t, t[x].rch); }
3。后序遍历(左孩子,右孩子,根)
void PostOrderTravel(node t[], int x) { if(t[x].lch!=-1) PostOrderTravel(t, t[x].lch); if(t[x].rch!=-1) PostOrderTravel(t, t[x].rch); cout << t[x].name << " "; }
二.实践遇到的问题。
针对“深入虎穴”这道编程题,看到输入格式的时候一开始有点懵,不知道怎么将这样的输入方式与树这个数据结构相契合。
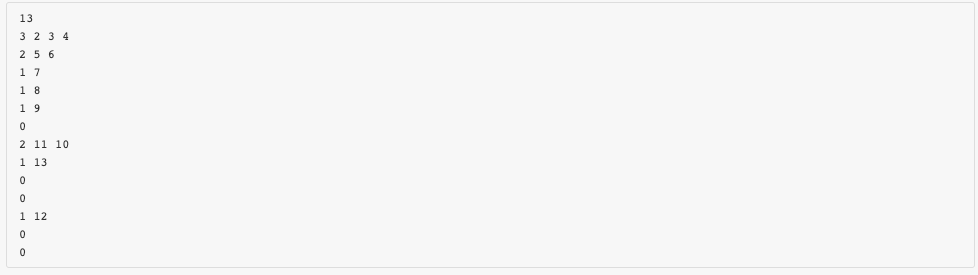
但后来在老师带领下,明白了这个输入格式所对应的逻辑图。
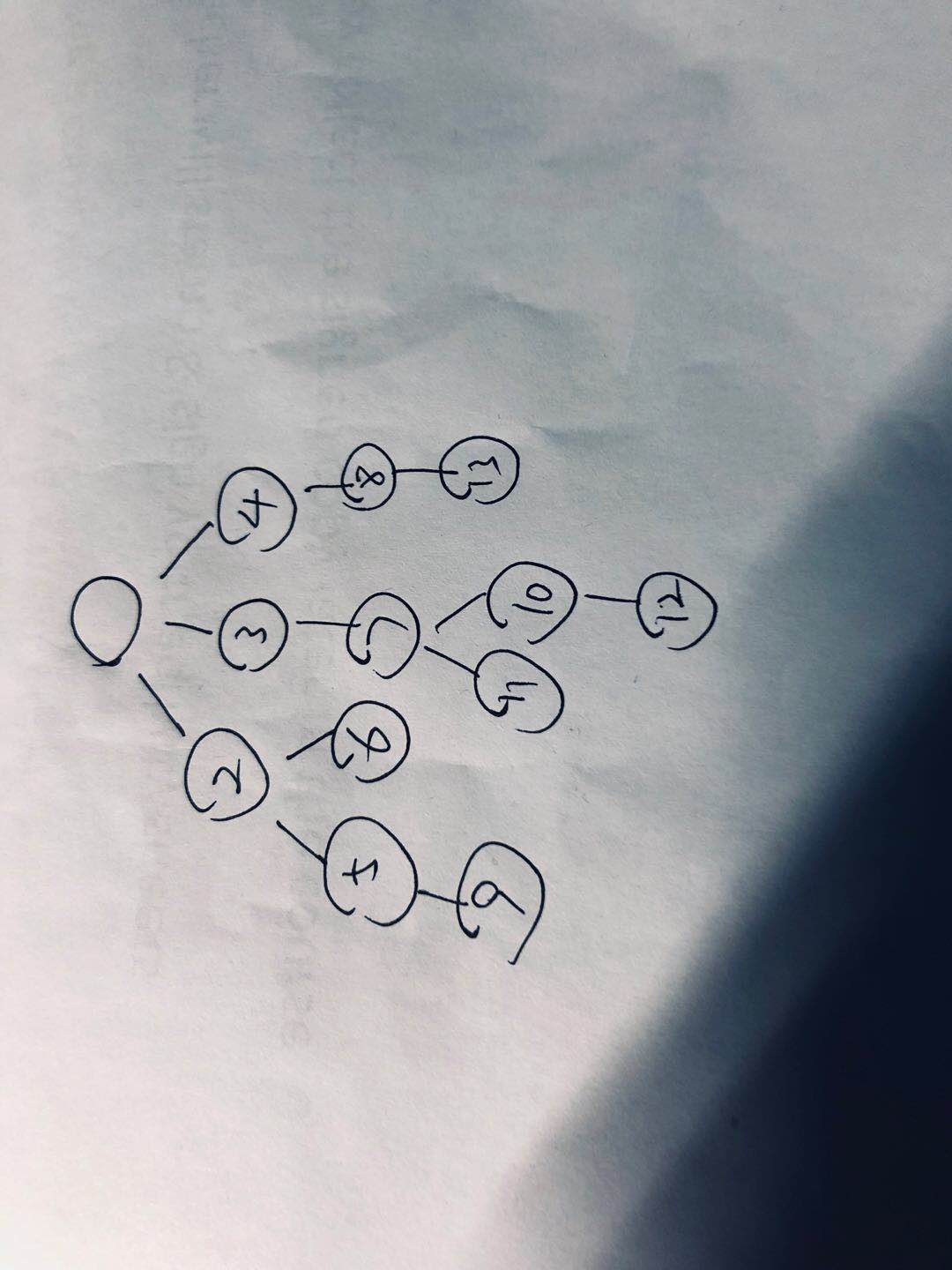
然后建立结点。
typedef struct{ int doors;//门的数量 int *p;//p指向门的编号,将p看作是整型数组 }node;
然后主函数。
int main(){ node *a; int i,j,k,root; root = input(a); cout<< find(a,root)<<endl; return 0; }
输入和寻找是最大的问题,一开始在find函数中还把循环里的i<a[x]写成了i<=a[x],导致溢出,无论怎样测试都不对
int input(node *&a) { int n,i,x,j; bool *vi; cin>>n; a = new node[n+1];//为a数组申请空间。 vi= new bool[n+1]; for(i=1;i<=n;i++) {//初始化vi为false vi[i]=false; } for(i=1;i<=n;++i) { cin>> x; a[i].doors=x; a[i].p=new int[x]; for(j=0;j<x;++j)//new的空间为x,x的有效下标为0~x—1,故循环从0开始。 { cin>>a[i].p[j]; vi[a[i].p[j]]=true; } } //找出根在数组的下标 for(i=1;i<=n;++i) { if(!vi[i])break; } return i; } int find(node *a,int root) { //从a数组的下标向下搜索 queue<int>q;//定义用于待访问的门编号的队列。 //根编号入队 q.push(root); int x,i; //当队列不为空 //x = 出队 //x后的门编号入队 while(!q.empty()){ x=q.front(); q.pop(); for(i=0 ; i<a[x].doors;++i) { q.push(a[x].p[i]); } } //答案为x return x; }
做完这道题以后,就觉得自己分析问题不够清晰,思路有些混乱,然后做题过程中十分粗心、大意。
还需要多多练习,多敲代码,继续整理笔记,理清思路。

