
关于JDK中的集合总结(三)
泛型:
jdk1.5出现的安全机制。
好处:
1,将运行时期的问题ClassCastException转到了编译时期。
2,避免了强制转换的麻烦。
<>:什么时候用?当操作的引用数据类型不确定的时候。就使用<>。将要操作的引用数据类型传入即可.
其实<>就是一个用于接收具体引用数据类型的参数范围。
在程序中,只要用到了带有<>的类或者接口,就要明确传入的具体引用数据类型 。
泛型技术是给编译器使用的技术,用于编译时期。确保了类型的安全。
运行时,会将泛型去掉,生成的class文件中是不带泛型的,这个称为泛型的擦除。
为什么擦除呢?因为为了兼容运行的类加载器。
java程序运行要靠虚拟机去启动一个类装载器。
类加载器:专门用于读取类文件,并解析类文件,并且把这个文件加载进入内存的一个程序。
1.4版本和1.5版本都是用的这个类加载器。
我们把类型在编译时期进行检查,如果检查之后是没有错误的就可以把这个泛型去掉。
里面的类型就统一了,我们还想用以前的这个类加载器,解析,加载进内存。
以前的加载器是没有见过泛型的。所以为了兼容运行的类加载器。
泛型的补偿:在运行时,通过获取元素的类型进行转换动作。不用使用者再强制转换了。
泛型的通配符:? 未知类型。
泛型的限定:
? extends E: 接收E类型或者E的子类型对象。上限。
一般存储对象的时候用。比如 添加元素 addAll.
? super E: 接收E类型或者E的父类型对象。 下限。
一般取出对象的时候用。比如比较器。
用大写的E,因为泛型中都是接收的引用数据类型,引用数据类型不是类就是借口,或者数组,他们的书写方式都是首字母大写.
E就是个参数,代表Elements.
早期没有泛型用的是Object,进行自动类型提升,当想用到集合中的元素时候要进行强制类型转换.
泛型尖括号中可以有多个类型;
Tool<String,Demo,Person,Integer> t = new Tool<String,Demo,Person,Integer>;
泛型中不能有基础数据类型,都是引用数据类型,可以是数组。
===========================================================
集合的一些技巧:
需要唯一吗?
需要:Set
需要制定顺序:
需要: TreeSet
不需要:HashSet
但是想要一个和存储一致的顺序(有序):LinkedHashSet
不需要:List
需要频繁增删吗?
需要:LinkedList
不需要:ArrayList
如何记录每一个容器的结构和所属体系呢?
看名字!
List
|--ArrayList
|--LinkedList
Set
|--HashSet
|--TreeSet
后缀名就是该集合所属的体系。
前缀名就是该集合的数据结构。
看到array:就要想到数组,就要想到查询快,有角标.
看到link:就要想到链表,就要想到增删快,就要想要 add get remove+frist last的方法
看到hash:就要想到哈希表,就要想到唯一性,就要想到元素需要覆盖hashcode方法和equals方法。
看到tree:就要想到二叉树,就要想要排序,就要想到两个接口Comparable,Comparator 。
而且通常这些常用的集合容器都是不同步的。
============================================
Map:一次添加一对元素。Collection 一次添加一个元素。
Map也称为双列集合,Collection集合称为单列集合。
其实map集合中存储的就是键值对。
map集合中必须保证键的唯一性。
常用方法:
1,添加。
value put(key,value):返回前一个和key关联的值,如果没有返回null.
2,删除。
void clear():清空map集合。
value remove(key):根据指定的key删除这个键值对。
3,判断。
boolean containsKey(key): 如果此映射包含指定键的映射关系,则返回 true
boolean containsValue(value): 如果此映射将一个或多个键映射到指定值,则返回 true
boolean isEmpty();
4,获取。
value get(key):通过键获取值,如果没有该键返回null。
当然可以通过返回null,来判断是否包含指定键。
int size(): 获取键值对的个数。
Map常用的子类:
|--Hashtable :内部结构是哈希表,是同步的。不允许null作为键,null作为值。
|--Properties:用来存储键值对型的配置文件的信息,可以和IO技术相结合。
|--HashMap : 内部结构是哈希表,不是同步的。允许null作为键,null作为值。
|--TreeMap : 内部结构是二叉树,不是同步的。可以对Map集合中的键进行排序。
Map和Collection没有关系,Collection有迭代器,Map没有。
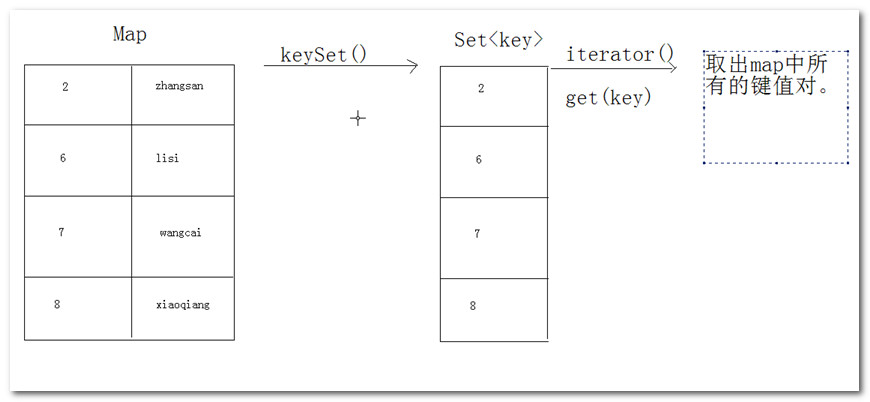
keySet
Set<K> keySet()
返回此映射中包含的键的 Set 视图。
keySet()→键的集合。
取出Map集合中所有的键值对第一种方法。
MapDemo1.java
1 import java.util.HashMap; 2 import java.util.Iterator; 3 import java.util.Map; 4 import java.util.Set; 5 6 public class MapDemo1 { 7 public static void main(String[] args) { 8 Map<Integer,String> map = new HashMap<Integer,String>(); 9 method_2(map); 10 } 11 12 public static void method_2(Map<Integer,String> map){ 13 map.put(8,"zhaoliu"); 14 map.put(2,"zhaoliu"); 15 map.put(7,"xiaoqiang"); 16 map.put(6,"wangcai"); 17 //取出map中的所有元素。 18 //原理,通过keySet方法获取map中所有的键所在的Set集合,在通过Set的迭代器获取到每一个键, 19 //再对每一个键通过map集合的get方法获取其对应的值即可。 20 21 Set<Integer> keySet = map.keySet(); 22 Iterator<Integer> it = keySet.iterator(); 23 24 while(it.hasNext()){ 25 Integer key = it.next(); 26 String value = map.get(key); 27 System.out.println(key+":"+value); 28 } 29 } 30 }
Map定义的时候就键就是Integer类型.
程序输出:
2:zhaoliu
6:wangcai
7:xiaoqiang
8:zhaoliu
嵌套类摘要
static interface Map.Entry<K,V> 映射项(键-值对)。
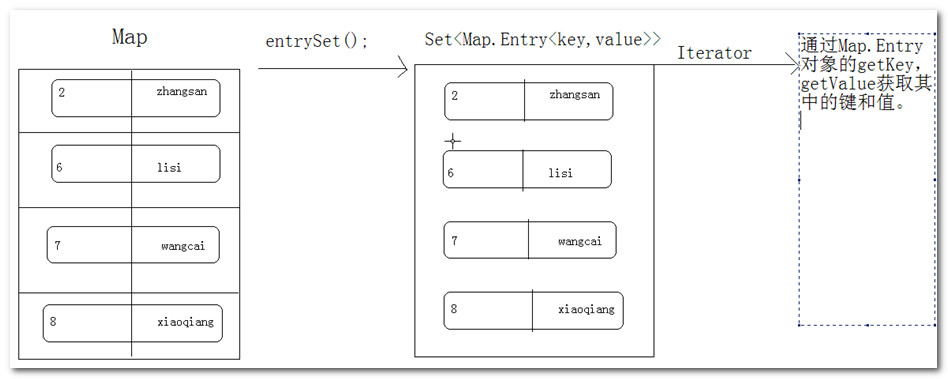
entrySet
Set<Map.Entry<K,V>> entrySet()
返回此映射中包含的映射关系的 Set 视图。
取出Map集合中所有的键值对第二种方法。
MapDemo2.java
1 public class MapDemo2 { 2 public static void main(String[] args) { 3 Map<Integer,String> map = new HashMap<Integer,String>(); 4 method_2(map); 5 } 6 7 public static void method_2(Map<Integer,String> map){ 8 map.put(8,"zhaoliu"); 9 map.put(2,"zhaoliu"); 10 map.put(7,"xiaoqiang"); 11 map.put(6,"wangcai"); 12 /* 13 * 通过Map转成set就可以迭代。 14 * 找到了另一个方法。entrySet。 15 * 该方法将键和值的映射关系作为对象存储到了Set集合中,而这个映射关系的类型就是Map.Entry类型(结婚证) 16 */ 17 Set<Map.Entry<Integer, String>> entrySet = map.entrySet(); 18 19 Iterator<Map.Entry<Integer, String>> it = entrySet.iterator(); 20 21 while(it.hasNext()){ 22 Map.Entry<Integer, String> me = it.next(); 23 Integer key = me.getKey(); 24 String value = me.getValue(); 25 System.out.println(key+"::::"+value); 26 } 27 } 28 } 29 interface MyMap{ 30 public static interface MyEntry{//内部接口 31 void get(); 32 } 33 } 34 class MyDemo implements MyMap.MyEntry{ 35 public void get(){} 36 } 37 class Outer{ 38 static class Inner{ 39 static void show(){} 40 } 41 }
输出结果:
程序输出: 2::::zhaoliu 6::::wangcai 7::::xiaoqiang 8::::zhaoliu
对比keySet和entrySet的不同:
entrySet
1 Set<Map.Entry<Integer, String>> entrySet = map.entrySet(); 2 Iterator<Map.Entry<Integer, String>> it = entrySet.iterator(); 3 4 while(it.hasNext()){ 5 Map.Entry<Integer, String> me = it.next(); 6 Integer key = me.getKey(); 7 String value = me.getValue(); 8 System.out.println(key+"::::"+value); 9 }
keySet
1 Set<Integer> keySet = map.keySet(); 2 Iterator<Integer> it = keySet.iterator(); 3 while(it.hasNext()){ 4 Integer key = it.next(); 5 String value = map.get(key); 6 System.out.println(key+":"+value); 7 }
取出Map集合中所有的键值对第三种方法。
|
values() |
这个地方虽然和前面两个地方挺像,但是这个地方仅仅是练习的Map接口中的values()方法。(其实是继承Map接口的HashMap中的values()方法。接口中的方法都是抽象方法)。
MapDemo3.java
1 public class MapDemo3 { 2 public static void main(String[] args) { 3 Map<Integer,String> map = new HashMap<Integer,String>(); 4 method_2(map); 5 } 6 public static void method_2(Map<Integer,String> map){ 7 map.put(8,"zhaoliu"); 8 map.put(2,"zhaoliu"); 9 map.put(7,"xiaoqiang"); 10 map.put(6,"wangcai"); 11 Collection<String> values = map.values(); 12 Iterator<String> it2 = values.iterator(); 13 while(it2.hasNext()){ 14 System.out.println(it2.next()); 15 } 16 } 17 }
程序输出:
程序输出:
zhaoliu
wangcai
xiaoqiang
zhaoliu
Map常用的子类:
|--Hashtable :内部结构是哈希表,是同步的。不允许null作为键,null作为值。
|--Properties:用来存储键值对型的配置文件的信息,可以和IO技术相结合。
|--HashMap : 内部结构是哈希表,不是同步的。允许null作为键,null作为值。
|--TreeMap : 内部结构是二叉树,不是同步的。可以对Map集合中的键进行排序。
后续出现的都是不同步的,效率高的。
Set集合的底层代码就是Map来实现的。
Map就能解决这个问题了,为什么还要有Set,是因为,为了保证单列集合中还能元素的唯一性,才出现的。
HashSet
此类实现 Set 接口,由哈希表(实际上是一个 HashMap 实例)支持。它不保证 set 的迭代顺序;特别是它不保证该顺序恒久不变。此类允许使用 null 元素。
类 Hashtable<K,V>
直接已知子类:
这个子类非常常用,可以和IO技术相结合。经常使用。
地址值:
如果仅仅是简单的一个城市就用字符串表示,如果是各个层级都有就用对象进行封装。
HashMapDemo.java
1 public class HashMapDemo { 2 public static void main(String[] args) { 3 /* 4 * 将学生对象和学生的归属地通过键与值存储到map集合中。 5 * 6 */ 7 HashMap<Student,String> hm = new HashMap<Student,String>(); 8 hm.put(new Student("lisi",38),"北京"); 9 hm.put(new Student("zhaoliu",24),"上海"); 10 hm.put(new Student("xiaoqiang",31),"沈阳"); 11 hm.put(new Student("wangcai",28),"大连"); 12 hm.put(new Student("zhaoliu",24),"铁岭"); 13 14 // Set<Student> keySet = hm.keySet(); 15 // Iterator<Student> it = keySet.iterator();
//这就是前面讲过的“匿名对象”,如果new一个对象就用一次,那就直接用匿名对象就可以。
17 Iterator<Student> it = hm.keySet().iterator(); 18 19 while(it.hasNext()){ 20 Student key = it.next(); 21 String value = hm.get(key); 22 System.out.println(key.getName()+":"+key.getAge()+"---"+value); 23 } 24 } 25 }
结果输出:
xiaoqiang:31---沈阳 zhaoliu:24---铁岭 lisi:38---北京 zhaoliu:24---上海 wangcai:28---大连
很明显这种输出是错误的,因为键是不能重复的,这个和当时学Set中的情况一样,Set中也是不允许出现重复的值。
解决办法:
键既然存储到了哈希表中,那么要去具备hashcode和equals方法和自己的内容,所以要在Student类中要去覆写hashcode和equals方法。
|
作者:SummerChill 出处:http://www.cnblogs.com/DreamDrive/ 本博客为自己总结亦或在网上发现的技术博文的转载。 如果文中有什么错误,欢迎指出。以免更多的人被误导。 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号