
用特权信息作超分网络的知识蒸馏——Learning with Privileged Information for Efficient Image Super-Resolution
论文标题:《Learning with Privileged Information for Efficient Image Super-Resolution》 ECCV-2020
作者信息:Wonkyung Lee, Junghyup Lee, Dohyung Kim, Bumsub Ham ——Yonsei University
关键词:Privileged information, knowledge distillation, mutual information
第一部分:知识蒸馏的回顾
一、蒸馏的基本形式与说明
将教师网络的知识蒸馏到学生网络中去(用一个教师网络去指导学生网络)
其中教师网络是一个效果比较好(比如分类的正确率比较高),但参数量大,计算成本高的网络;
学生网络是一个比较小的网络;
如果单单只用学生网络去学习、去训练,那么它的训练效果不是很好,因为其表征能力有限;而用了教师网络来指导,可以提升学生网络的模型效果;
知识蒸馏的目的是节省计算与存储成本。
二、软标签蒸馏——《Distilling the Knowledge in a Neural Network》
该论文是Hinton大神在2015年发表的,可以认为是知识蒸馏的开山之作。
在本论文中,学生网络不仅要跟真实数据标签(硬标签)作比较,而且要和教师网络的输出(软标签)做比较。

1、为什么要用软标签?
a.soft target可作为一个正则化项,去约束student network中参数的分布;
b.原本的数据的标签是离散的(一张图准确对应一个类标),而soft target把类别之间的关联性给出了。(可以想象成是一种label augmentation)
2、标签软化
在原本的softmax中,增加了温度系数T,可以让教师网络的输出更加平滑;
比如原本是(0.01, 0.03, 0.96),变成(0.2,0.3,0.5);
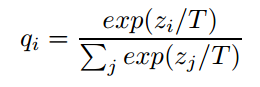
3为什么要用温度系数?
a.小概率结果对损失函数的贡献微乎其微。解决的方法无非是:在计算损失函数时放大其他类的概率值所对应的损失值;
b.使得类与类之间的关联信息更明显;
二、特征蒸馏——《FitNets Hints for Thin Deep Nets》
该论文是2015年发表在ICLR上的,算是对软标签蒸馏的扩展;
在该论文发表时,ResNet还没有问世,训练一些深层的网络是一件很困难的事情;
1、论文的主要idea
该论文的主要想法是学生网络采用一个更窄(卷积核小)但更深(卷积层多)的网络结构,称为FitNet,然后用教师网络的特征参数去指导学生网络的特征参数;
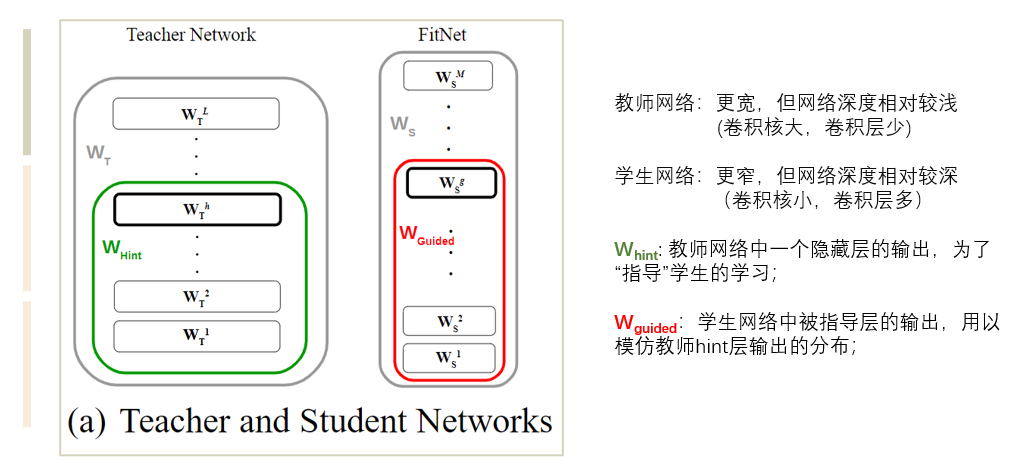
2、FitNets的训练过程
step1:按常规方法讲教师网络训练好;
step2:使用hint损失函数(作特征蒸馏),让学生网络guided层的输出去拟合教师网络hint层的输出;
由于hint层和guided层的维度、大小并不匹配,于是在二者之间添加一个回归器;
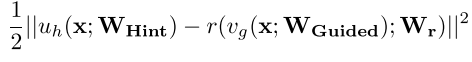
第一项表示教师网络输入x后,到hint层的输出;后一项是学生网络的,但多一个回归器及回归器的参数;
step3:用软标签+硬标签完整地训练学生网络。
三、知识蒸馏究竟在做什么?
传统的损失函数:(第一项是模型结果与真实值的误差,通常用平均绝对值或交叉熵;后一项是正则化项)
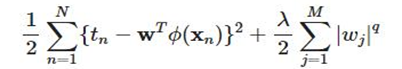
软标签损失函数:(第一项是模型结果与真实值的误差,第二项是模型结果与软标签的误差)
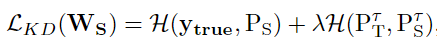
a.如果我们讲两个损失函数对应起来,软标签可视作一个正则化项,去约束学生网络中的特征参数;
b.而上面的特征蒸馏更是直接地让教师网络的特征对学生网络的特征参数进行约束;
c.蒸馏,就是让学生网络去学校教师网络特征参数的分布,去寻找学生网络特征参数与教师网络特征参数之间的映射关系。
第二部分:《Learn with privileged information for efficient image super-resolution》
四、标题中的privileged information是什么?
直译是特权信息,也叫附加、额外信息,是教师网络中,用以辅组学生网络训练的信息。
论文原文:a teacher to make use of extra (privileged) information at training time, and assisting the training processof a student network with the complementary knowledge;
直观理解:在课堂学习(训练阶段)时,我们做一道题,不仅仅有它的正确答案,而且会有老师给我们解释其中的来龙去脉,这里“教师的解释”就是privilege information。
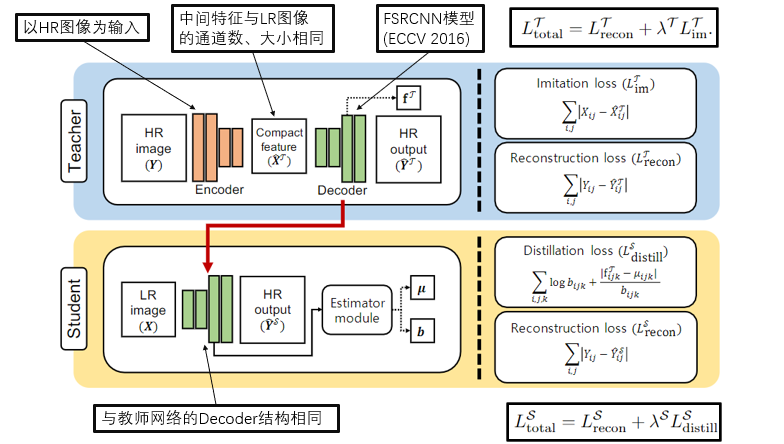
五、论文中所提出框架的概览
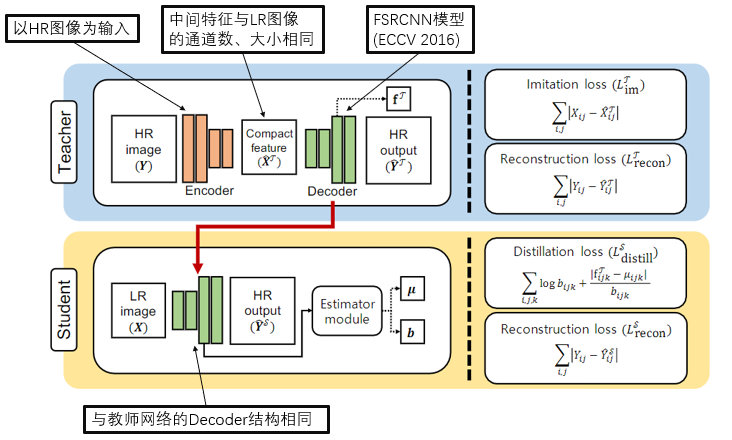
六、教师网络
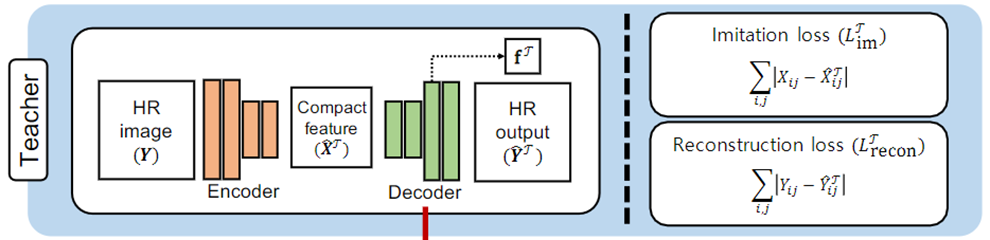
a.沙漏前端(Encoder)用以提取HR图的紧凑特征;
b.沙漏后端(Decoder)使用FSRCNN*模型,利用提取到的特征去重建HR图像;
c.为了避免Encoder得表征能力过强,同时也是为了利于学生网络学习,在教师网络的中间使用模仿损失函数(Imitation loss)去约束Encoder;
d.重建损失函数(Reconstruction loss)用以计算重建的图像与原图的差距;
e.模仿损失与重建损失联合起来,可以让网络中间提取的特征在‘利于重建’与‘利于学生学习’之间达到一个平衡。
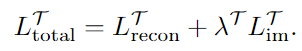
*FSRCNN出自《Accelerating the Super-Resolution Convolutional Neural Networks》(ECCV 2016)
七、学生网络
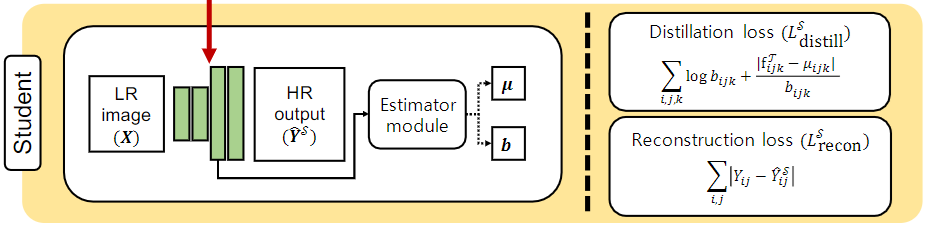
a.学生网络的结构与教师网络的Decoder模块一致,使用FSRCNN模型;
b.蒸馏损失函数(Distillation loss)用以学习教师网络Decoder模块中参数分布;
c.重建损失函数(Reconstruction loss)用以计算重建的图像与原图的差距;
d.蒸馏损失与重建损失联合起来,可以让学生网络在模仿教师网络的同时,也根据自身情况微调。

八、蒸馏损失函数如何设计?
本文使用VID的方法,其出发点是最大化教师网络和学生网络对应层的信息熵之间的互信息。
1、什么是互信息?

a.互信息:是两个随机变量间相互依赖性的度量,即当知道了其中一方之后,另一方的不确定性减少的量,用I(X,Y)表示。
b.两个随机变量之间的互信息越大,表明二者之间的关系越强。
c.相对于相关系数,互信息可以捕捉到变量之间非线性的统计相关性。
2、VID方法:
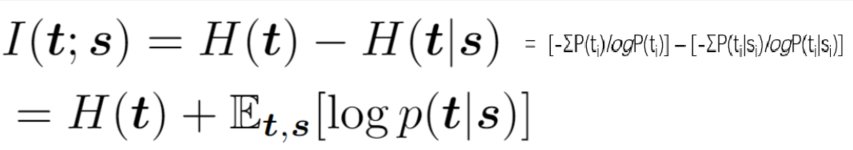
H(t)是教师网络某一层特征的信息熵,H(s)是学生网络某一层特征的信息熵;
H(t|s)表示当知道了学生网络的特征信息之后,教师网络的特征信息熵的减少,当H(t|s)越小则互信息越大(请从上面的韦恩图理解)。
但是,在蒸馏的过程中,学生网络的特征参数是不断变化的,所以计算p(t|s)是很困难的。
于是,本文采用VID*方法,使用一个概率分布q(t|s)去模拟p(t|s),也就是本文中的蒸馏损失函数。
*VID方法出自《Variational Information Distillation for Knowledge Transfer》 CVPR 2019
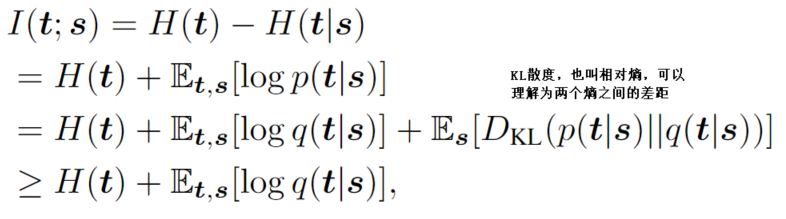
在教师网络训练完成后,H(t)也就固定下来了,视作一个常数;同时,logq(t|s)和q(t|s)的单调性一样,所以只需要模拟q(t|s)
3、蒸馏损失函数

4、为什么要用这样的分布去模拟?
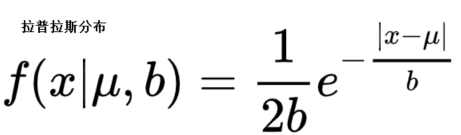
可以看到蒸馏损失函数的第二项和拉普拉斯分布中e的指数是一致的(而指数和该整个式子的单调性一致),可以认为VID方法用拉普拉斯分布去模拟p(t|s)。
由于训练过程学生网络的特征参数是不断变化的,按照中心极限定理,它们总和的平均,就是高斯或者近高斯的。
高斯分布和拉普拉斯分布很像,该论文也尝试了用高斯分布去模拟。
九、再看论文中所提出框架
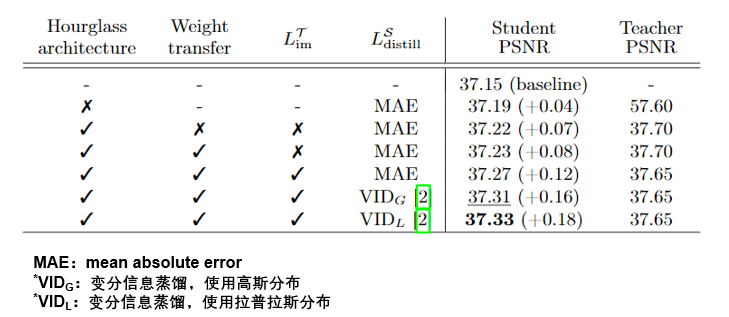
十、消融实验
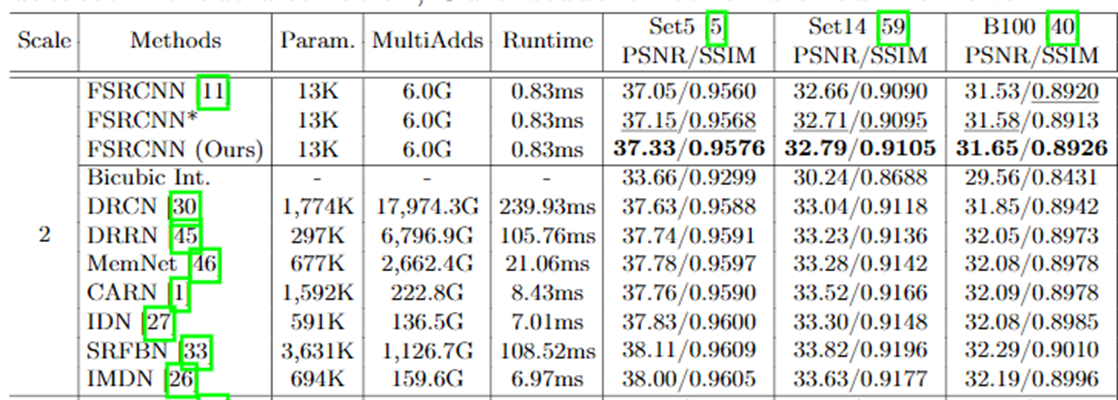
十一、测试表现
可以从下表看到,该论文提出的蒸馏方法可以有效地提高FSRCNN的表现,但与其他大容量的模型,还是有一定差距。
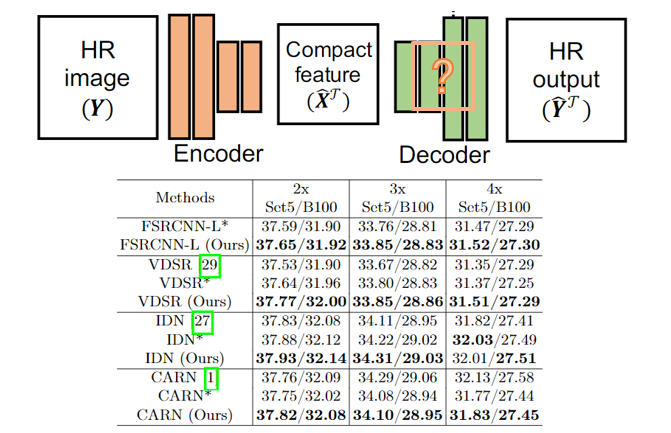
十二、其他学生网络
该论文还使用VDSR、IDN、CARN作Decoder和学生网络去蒸馏,效果均有提升。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号