
Python-使用requests库和正则表达式爬取淘宝商品信息
〇、环境
语言版本:python 3.8.3
编辑器:IDLE(python自带)
操作系统:win10
一、需求
1、获取taobao指定商品页面中的 价格和名称,这里以书包为例子。
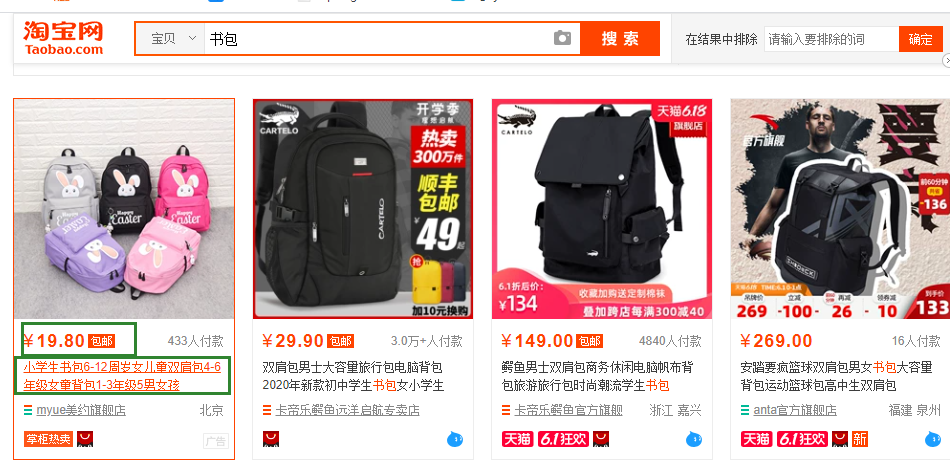
2、格式化输出

二、分析
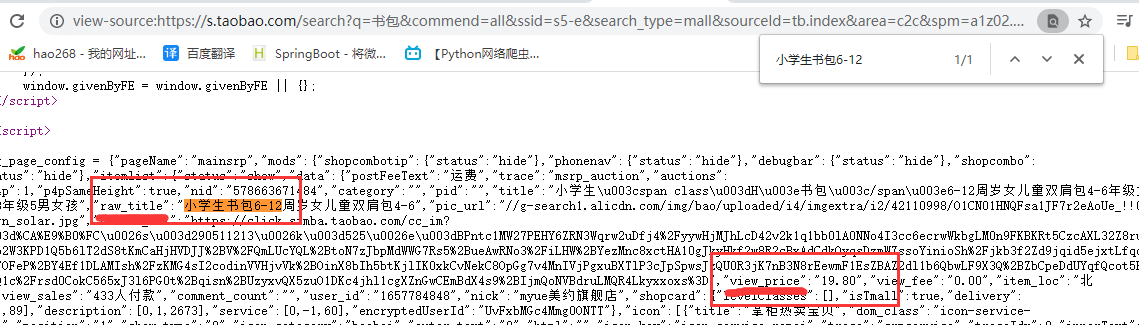
1、taobao商品页面的源代码组织形式
在商品页右键查看源代码,然后根据商品价格和商品名搜索,会发现 商品名前有“raw_title”键,价格前有“view_price”键;
依此,获取本页面的html之后,我们可以很方便的用正则表达式获取想要信息。
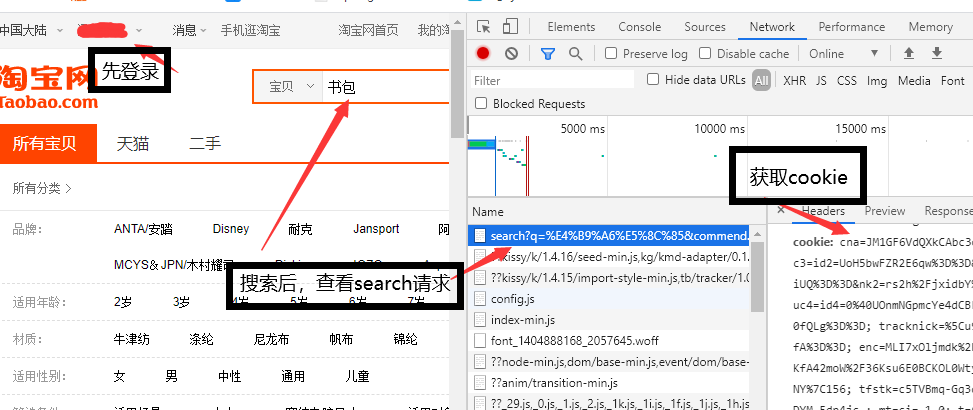
2、障碍及其解决
淘宝的反爬虫机制,会使得未登录则不可访问,所以我们得先登录,并获取cookie
三、编码实现
0、引入需要的库
import requests
import re
#requests库是网络请求库,需要提前安装(在命令行窗口以:pip install requests)
1、获取商品页的html代码
1 def getHTMLText(url): 2 try: 3 #本header中需要有cookie和user-agent字段 4 #cookie是为了模拟登录,user-agent是为了模拟某些浏览器发起的请求 5 6 header = {'cookie':'刚刚获取的cookie复制到此','user-agent':'Mozilla/5.0'} 7 r = requests.get(url,timeout=30,headers = header) 8 r.raise_for_status() 9 r.encoding = r.apparent_encoding 10 return r.text 11 except: 12 return ""
2、处理html代码,获取商品信息
1 def parsePage(ilt,html): 2 try: 3 #使用正则表达式获取价格和商品名 4 5 plt = re.findall(r'\"view_price\"\:\"[\d\.]*\"',html) 6 tlt = re.findall(r'\"raw_title\"\:\".*?\"',html) 7 for i in range(len(plt)): 8 price = eval(plt[i].split(':')[1]) 9 title = eval(tlt[i].split(':')[1]) 10 ilt.append([price,title]) 11 except: 12 print("")
3、格式化打印输出
1 def printGoodsList(ilt): 2 #使用format()函数,格式话打印 3 4 tplt = "{:4}\t{:8}\t{:16}" 5 print(tplt.format("序号","价格","商品名称")) 6 count = 0 7 for g in ilt: 8 count = count+1 9 print(tplt.format(count,g[0],g[1]))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号