

Item-CF和User-CF算法训练过程优化的心得
〇、背景
数据集:MovieLens-1M(其中用户数6040,电影数3592,评分数1000000);
工具:Java、MySQL、Redis;
主要参考资料:《推荐系统实践》项亮;
一、Item-CF算法描述
1.Item-CF算法思想
为当前用户推荐——与当前用户感兴趣物品相似的 且 当前用户没有接触的物品。
2.实现步骤
(1)计算物品之间的相似度;
(2)根据物品相似度和用户的行为历史,作出推荐。
二、User-CF算法描述
1.User-CF算法思想
先找到目标用户的相似用户(即与他有相同兴趣的其他用户),然后把 相似用户喜欢的 且 目标用户未作出行为的 物品推荐给目标用户。
2.实现步骤
(1)计算用户兴趣的相似度;
(2)找到与当前用户兴趣相似的用户集合,从该集合的历史物品列表中作出推荐。
三、遇到的问题
基于物品/用户的协同过滤算法是实现推荐系统的基本算法,同时也算是学习推荐系统的入门。两个算法的思想简单明了,所涉及的知识点也比较容易理解,但实现过程中也会有一些坑,比如说——训练过程太耗时。
以Item-CF为例,在算法实现过程中,我先计算物品之间的相似度,并将结果以set的数据结构暂存到Redis(一个基于内存的键值对数据库),方便使用。
而Item-CF算法最耗时的地方是 计算用户对某物品兴趣度的过程,公式如下:
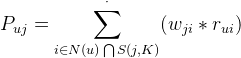
其中Puj表示,用户u对物品j的兴趣度。N(u)表示用户u喜欢的物品集合,S(j,K)表示与物品j最相似的K个物品,这里取K=10。而N(u)∩S(j,K)表示与物品j相似,且用户u感兴趣的物品。wji表示物品j和物品i的相似度。rui表示用户u对物品i的兴趣。
每个用户对每个物品都需要计算,其时间复杂度大概为O(U*I*10),U为用户数,I为物品数,10表示与当前物品最相似的10个物品。
四、重复步骤的优化
这里的优化主要指的是,在MovieLens数据集下,计算用户对某电影兴趣度的过程优化。
1.重复的步骤
从下面的伪代码可以看出:当user=1 movie=1时,会从redis取与当前电影相似的10部电影;当user=2 movie=1时,又会取一遍!这样算下来,会有六千多次的多余,大大影响了效率。
1 for(int user=1;user<=6040;user++){ 2 //从数据库中取当前用户的评分历史 3 4 for(int movie=1;movie<=3952;movie++){ 5 //从redis中取与当前电影相似的10部电影 6 } 7 8 }
2.优化方法:
以空间换时间,在算法开始时就把所有电影的相似电影取出来当作Java静态变量待用。
优点:避免了重复;缺点:占用了Java虚拟机的堆空间,使得垃圾回收更加频繁(当然,可以设置参数,加大堆内存解决)。
五、数据库查询的优化
1.数据库的多次查询
从下面的代码可以看出:6040个用户,每循环一次就要查询一次数据库,即对用户的查询需要六千多次。
而一次查询一个用户的数据,反复查6040次,和一次直接查询6040个用户,时间差是非常大的。
1 for(int user=1;user<=6040;user++){ 2 //从数据库中取当前用户的评分历史 3 4 }
2.优化方法
通过一次查询多个用户数据而非一次查询一个用户,可以大大提高效率。
本方法其实是使用到了SQL语句中的“in”关键字来一次性查询多个用户数据,例如:Select * from user id in 1,2,3....
但该注意的地方是,若一次性查询太多个用户的数据,会造成Java虚拟机内存溢出(Out Of Memory异常),所以得在实践中找到最佳的可以一次性查询的数据数量。
六、计算过程优化
这里的优化主要指的是,在MovieLens数据集下,计算用户对某电影兴趣度的过程优化。
1.耗时
即使通过上面的优化,但由于数据量大,且个人电脑的硬件限制等,耗时还是不可接受的(粗略计算超过12小时)。
2.解决方法
利用多线程,步骤如下:
(1)方法切分
将整个计算过程细分为若干个独立的计算单元,每个计算单元作一条线程。
比如:将查询用户的评分历史作一条线程,将查询与本电影相似的电影作一条线程,将计算用户对某电影兴趣度作一条线程。
(2)线程合作
多线程的执行具有不可预知性,我们需要制约它们的前后顺序。我这里采用的是“读者-写者”的方法。
比如:A线程查询用户后将结果传递给B线程;B线程收到A线程的数据后开始执行,并将本线程的结果传给C线程.....
具体到Java中,可以使用BlockingQueue集合类来实现数据互斥地写入、读出。
(3)效果
用本方法优化后,可以达到一个"线程流水线"的效果,大大缩减算法训练时间,如图所示:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号