
基于MOOC嵩天《Python数据分析与展示》视频学习记录——第三周:Pandas
文章目录
1.Pandas库的基本数据类型
1.1.Series类型
Series类型由一组数据及与之相关的数据索引组成。
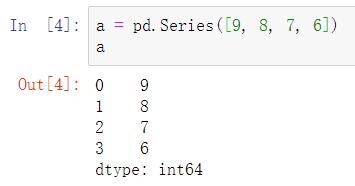
1.1.1自动索引
1.1.2.自定义索引

注:若index为第二个变量,则可以省略
1.2.创建Serises类型
1.2.1.从标量值创建
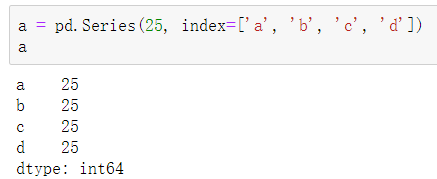
注:index不能省略
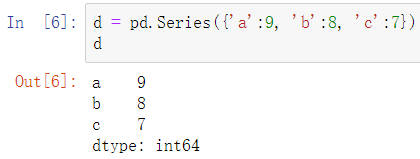
1.2.2.从字典类型创建
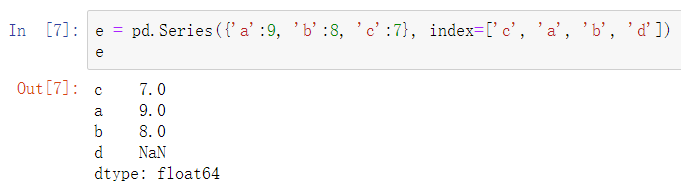
同时可以通过index指定Series的结构并从字典选取对应值:
1.2.3.从ndarray类型创建

同时也可以通过index指定索引:

1.2.4.总结

1.3.Series类型的基本操作
b = pd.Series([9, 8, 7, 6], index=['a', 'b', 'c', 'd'])
b.index # 获取索引
b.values # 获取数据

- 自动索引与自定义索引并存
- 并存但不能混用
![在这里插入图片描述]()
![在这里插入图片描述]()
![在这里插入图片描述]()
![在这里插入图片描述]()
![在这里插入图片描述]()





1.4.Series类型的对齐操作
相同索引的数值之间进行运算:

1.5.Series类型的name属性
Series对象和索引都可以有一个名字,存储在属性.name中。
Series对象可以随时修改并即刻生效。

1.6.Series类型的修改
Series对象可以随时修改并即刻生效。

2.1.DataFrame类型
- DataFrame类型由共用相同索引的一组列组成。
- DataFrame是一个表格型的数据类型,每列值类型可以不同。
- DataFrame既有行索引、也有列索引。
- DataFrame常用于表达二维数据,但可以表达多维数据。
![在这里插入图片描述]()

2.2.创建DataFrame类型
2.2.1.从ndarray对象创建

2.2.2.从一维ndarray对象字典创建

2.2.3.从列表类型的字典创建

2.3.DataFrame类型的基本操作
d.index # 获得第0列的索引
d.columns # 获得第0行的索引
d.values # 获得数据部分

DataFrame基本操作类似于Series,依据行列索引。

2.Pandas库的数据类型操作
2.1.重新索引
.reindex( )能够改变或重排Series和DataFrame索引。

.reindex( )的其他参数:


2.2.索引类型的常用方法


2.3.删除指定索引对象
.drop( )能够删除Series和DataFrame指定行或列索引。

2.4.Pandas库的数据类型运算
算术运算法则:
- 算术运算根据行列索引,补齐后运算,运算默认产生浮点数。
- 补齐时缺项填充NaN (空值)。
- 二维和一-维、一维和零维间为广播运算。
- 采用± * /符号进行的二元运算产生新的对象。
![在这里插入图片描述]()

2.4.1.方法形式的运算




2.4.2.比较运算法则
- 比较运算只能比较相同索引的元素,不进行补齐。
- 二维和一-维、一维和零维间为广播运算。
- 采用><>=<=-- !=等符号进行的二元运算产生布尔对象。
![在这里插入图片描述]()
![在这里插入图片描述]()



 浙公网安备 33010602011771号
浙公网安备 33010602011771号