Python人工智能之路 - 第三篇 : PyAudio 实现录音 自动化交互实现问答
Python 很强大其原因就是因为它庞大的三方库 , 资源是非常的丰富 , 当然也不会缺少关于音频的库
关于音频, PyAudio 这个库, 可以实现开启麦克风录音, 可以播放音频文件等等,此刻我们不去了解其他的功能,只了解一下它如何实现录音的
首先要先 pip 一个 PyAudio
pip install pyaudio
一.PyAudio 实现麦克风录音
然后建立一个py文件,复制如下代码
import pyaudio import wave CHUNK = 1024 FORMAT = pyaudio.paInt16 CHANNELS = 2 RATE = 16000 RECORD_SECONDS = 2 WAVE_OUTPUT_FILENAME = "Oldboy.wav" p = pyaudio.PyAudio() stream = p.open(format=FORMAT, channels=CHANNELS, rate=RATE, input=True, frames_per_buffer=CHUNK) print("开始录音,请说话......") frames = [] for i in range(0, int(RATE / CHUNK * RECORD_SECONDS)): data = stream.read(CHUNK) frames.append(data) print("录音结束,请闭嘴!") stream.stop_stream() stream.close() p.terminate() wf = wave.open(WAVE_OUTPUT_FILENAME, 'wb') wf.setnchannels(CHANNELS) wf.setsampwidth(p.get_sample_size(FORMAT)) wf.setframerate(RATE) wf.writeframes(b''.join(frames)) wf.close()
尝试一下,在目录中出现了一个 Oldboy.wav 文件 , 听一听,还是很清晰的嘛
接下来,我们将这段录音代码,写在一个函数里面,如果要录音的话就调用
建立一个文件 pyrec.py 并将录音代码和函数写在内
# pyrec.py 文件内容 import pyaudio import wave CHUNK = 1024 FORMAT = pyaudio.paInt16 CHANNELS = 2 RATE = 16000 RECORD_SECONDS = 2 def rec(file_name): p = pyaudio.PyAudio() stream = p.open(format=FORMAT, channels=CHANNELS, rate=RATE, input=True, frames_per_buffer=CHUNK) print("开始录音,请说话......") frames = [] for i in range(0, int(RATE / CHUNK * RECORD_SECONDS)): data = stream.read(CHUNK) frames.append(data) print("录音结束,请闭嘴!") stream.stop_stream() stream.close() p.terminate() wf = wave.open(file_name, 'wb') wf.setnchannels(CHANNELS) wf.setsampwidth(p.get_sample_size(FORMAT)) wf.setframerate(RATE) wf.writeframes(b''.join(frames)) wf.close()
rec 函数就是我们调用的录音函数,并且给他一个文件名,他就会自动将声音写入到文件中了
二.实现音频格式自动转换 并 调用语音识别
录音的问题解决了,赶快和百度语音识别接在一起使用一下:
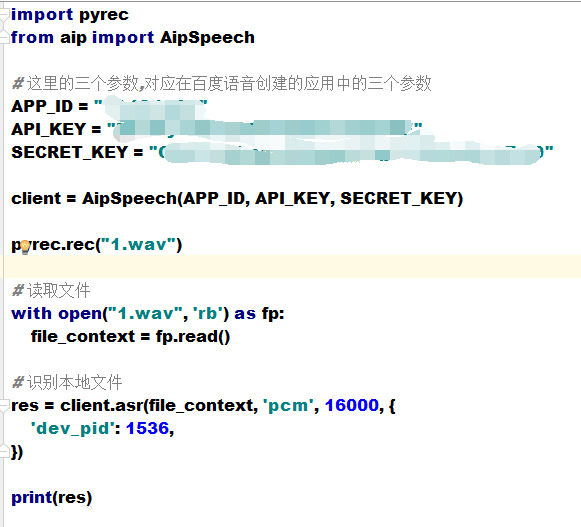
不管你的录音有多么多么清晰,你发现百度给你返回的永远是:
{'err_msg': 'speech quality error.', 'err_no': 3301, 'sn': '6397933501529645284'} # 音质不清晰
其实不是没听清,而是百度支持的音频格式PCM搞的鬼
所以,我们要将录制的wav音频文件转换为pcm文件
写一个文件 wav2pcm.py 这个文件里面的函数是专门为我们转换wav文件的
使用 os 模块中的 os.system()方法 这个方法是执行系统命令用的, 在windows系统中的命令就是 cmd 里面写的东西,dir , cd 这类的命令
# wav2pcm.py 文件内容 import os def wav_to_pcm(wav_file): # 假设 wav_file = "音频文件.wav" # wav_file.split(".") 得到["音频文件","wav"] 拿出第一个结果"音频文件" 与 ".pcm" 拼接 等到结果 "音频文件.pcm" pcm_file = "%s.pcm" %(wav_file.split(".")[0]) # 就是此前我们在cmd窗口中输入命令,这里面就是在让Python帮我们在cmd中执行命令 os.system("ffmpeg -y -i %s -acodec pcm_s16le -f s16le -ac 1 -ar 16000 %s"%(wav_file,pcm_file)) return pcm_file
这样我们就有了把wav转为pcm的函数了 , 再重新构建一次咱们的代码
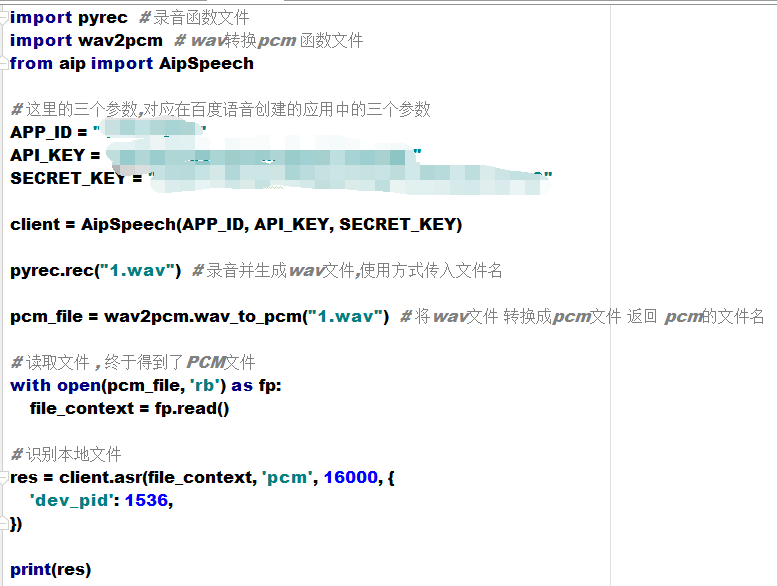
这次的返回结果还挺让人满意的嘛
{'corpus_no': '6569869134617218414', 'err_msg': 'success.', 'err_no': 0, 'result': ['老男孩教育'], 'sn': '8116162981529666859'}
拿到语音识别的字符串了,接下来用这段字符串 语音合成, 学习咱们说出来的话
三.语音合成 与 FFmpeg 播放mp3 文件
拿到字符串了,直接调用synthesis方法去合成吧

这段代码衔接上一段代码,成功获得了 synth.mp3 音频文件,并且确定了实在学习我们说的话
接下来就是让我们的程序自动将 synth.mp3 音频文件播放了 其实PyAudio 有播放的功能,但是操作有点复杂
所以我们还是选择用简单的方式解决复杂的问题,就是这么简单粗暴,是否还记得FFmpeg 呢?
FFmpeg 这个系统工具中,有一个 ffplay 的工具用来打开并播放音频文件的,使用方法大概是: ffplay 音频文件.mp3
建立一个playmp3.py文件, 写一个 play_mp3 的函数用来播放已经合成的语音
# playmp3.py 文件内容 import os def play_mp3(file_name): os.system("ffplay %s"%(file_name))
回到主文件,调用playmp3.py文件中的 play_mp3 函数

执行代码,当你看到 : 开始录音,请说话......
请大声的说出: 学IT 找老男孩教育
然后你就会听到,一个娇滴滴声音重复你说的话
四.简单问答
首先我们要把代码重新梳理一下:
把语音合成 语音识别部分的代码独立成函数放到baidu_ai.py文件中
# baidu_ai.py 文件内容 from aip import AipSpeech # 这里的三个参数,对应在百度语音创建的应用中的三个参数 APP_ID = "xxxxx" API_KEY = "xxxxxxx" SECRET_KEY = "xxxxxxxx" client = AipSpeech(APP_ID, API_KEY, SECRET_KEY) def audio_to_text(pcm_file): # 读取文件 , 终于得到了PCM文件 with open(pcm_file, 'rb') as fp: file_context = fp.read() # 识别本地文件 res = client.asr(file_context, 'pcm', 16000, { 'dev_pid': 1536, }) # 从字典里面获取"result"的value 列表中第1个元素,就是识别出来的字符串"老男孩教育" res_str = res.get("result")[0] return res_str def text_to_audio(res_str): synth_file = "synth.mp3" synth_context = client.synthesis(res_str, "zh", 1, { "vol": 5, "spd": 4, "pit": 9, "per": 4 }) with open(synth_file, "wb") as f: f.write(synth_context) return synth_file
然后把我们的主文件进行一下修改
import pyrec # 录音函数文件 import wav2pcm # wav转换pcm 函数文件 import baidu_ai # 语音合成函数,语音识别函数 文件 import playmp3 # 播放mp3 函数 文件 pyrec.rec("1.wav") # 录音并生成wav文件,使用方式传入文件名 pcm_file = wav2pcm.wav_to_pcm("1.wav") # 将wav文件 转换成pcm文件 返回 pcm的文件名 res_str = baidu_ai.audio_to_text(pcm_file) # 将转换后的pcm音频文件识别成 文字 res_str synth_file = baidu_ai.text_to_audio(res_str) # 将res_str 字符串 合成语音 返回文件名 synth_file playmp3.play_mp3(synth_file) # 播放 synth_file
然后就是大展宏图的时候了,展开你们的想象力:
res_str 是字符串,如果字符串等于"你叫什么名字"的时候,我们就要给他一个回答:我的名字叫老男孩教育
新建一个FAQ.py的文件然后建立一个函数faq:
# FAQ.py 文件内容 def faq(Q): if Q == "你叫什么名字": # 问题 return "我的名字是老男孩教育" # 答案
return "我不知道你在说什么" #问题没有答案时返
在主文件中导入这个函数,并将语音识别后的字符串传入函数中

现在来尝试一下:"你叫什么名字","你今年几岁了"
成功了,现在你可以对 FAQ.py 这个文件进行更多的问题匹配了
还是那句话,别玩儿坏了
思考题:
1.如何实现一直问答不用问一次停一次?
2.问题那么多,是不是要写这么多问题呢?
3.如果我问你是谁,是不是要重复也一次 我的名字叫老男孩教育 的答案呢?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号