Python人工智能之路 - 第二篇 : 算法实在太难了有现成的直接用吧
本节内容 预备资料:
1.FFmpeg:
链接:https://pan.baidu.com/s/1jonSAa_TG2XuaJEy3iTmHg
密码:w6hk
2.baidu-aip:
pip install baidu-aip
终于进入主题了,此篇是人工智能应用的重点,只用现成的技术不做底层算法,也是让初级程序员快速进入人工智能行业的捷径
目前市面上主流的AI技术提供公司有很多,比如百度,阿里,腾讯,主做语音的科大讯飞,做只能问答的图灵机器人等等
这些公司投入了很大一部分财力物力人力将底层封装,提供应用接口给我们,尤其是百度,完全免费的接口
既然百度这么仗义,咱们就不要浪费掉怎么好的资源,从百度AI入手,开启人工智能之旅
开启人工智能技术的大门 : http://ai.baidu.com/
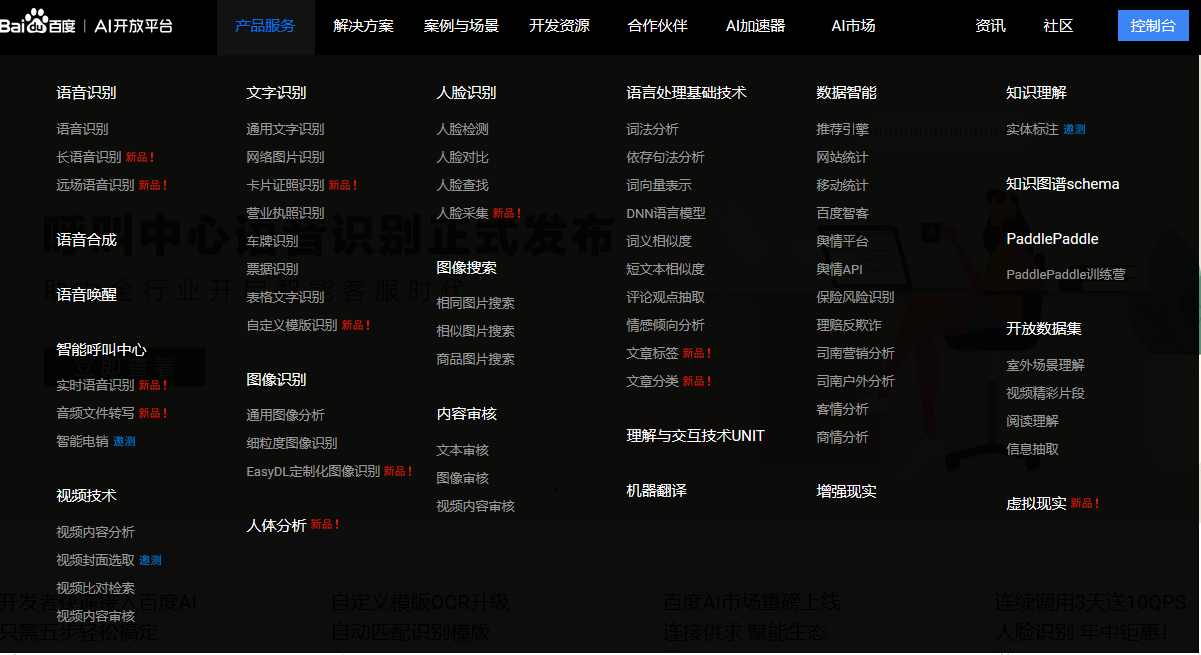
看看我大百度的AI大法,这些技术全部都是封装好的接口,看着就爽
接下来咱们就一步一步的操作一下
首先进入控制台,注册一个百度的账号(百度账号通用)

开通一下我们百度AI开放平台的授权
然后找到已开通服务中的百度语音
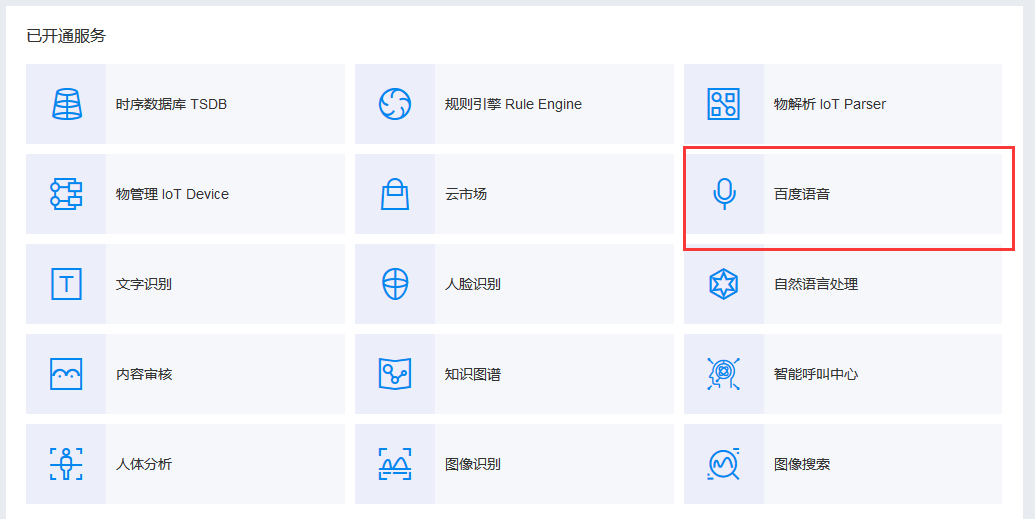
走到这里,想必已经知道咱们要从语音入手了,语音识别和语音合成
打开百度语音,进入语音应用管理界面,创建一个新的应用 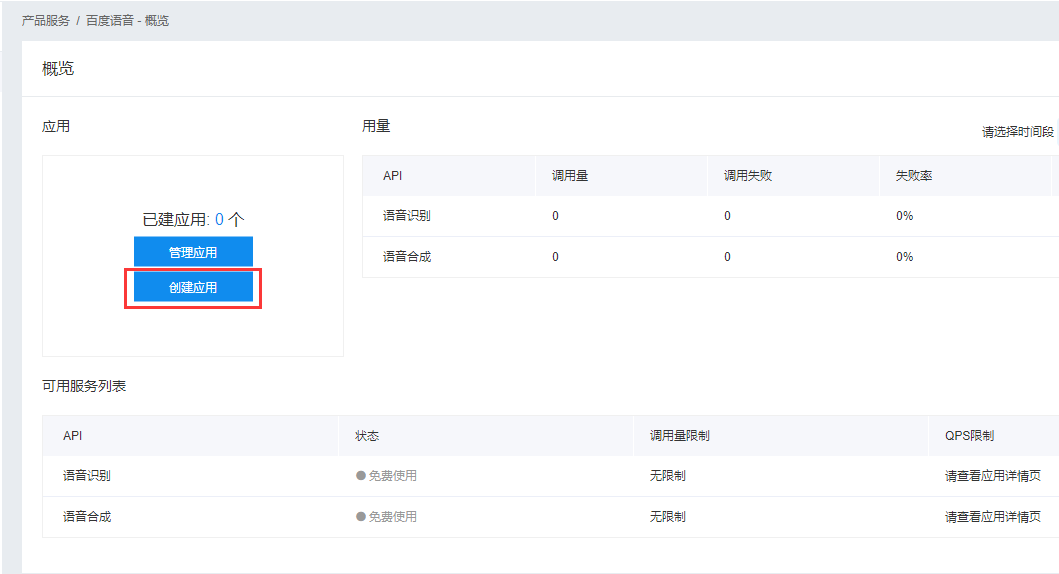
创建语音应用App

就可以创建应用了,回到应用列表我们可以看到已创建的应用了

这里面有三个值 AppID , API Key , Secret Key 记住可以从这里面看到 , 在之后的学习中我们会用到
好了 百度语音的应用已经创建完成了 接下来 我会用Python 代码作为实例进行应用及讲解
一.安装百度的人工智能SDK:
首先咱们要 pip install baidu-aip 安装一个百度人工智能开放平台的Python SDK实在是太方便了,这也是为什么我们选择百度人工智能的最大原因
安装完成之后就来测试一下:

在工程目录下,就可以看到 s1.mp3 这个文件了,来听一听
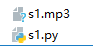
上面咱们测试了一个语音合成的例子,那么就从语音合成开始入手
二.语音合成:
技术上,代码上任何的疑惑,都可以从官方文档中得到答案
baidu-aip Python SDK 语音合成技术文档 : https://ai.baidu.com/docs#/TTS-Online-Python-SDK/top
刚才我们做了一个语音合成的例子,就用这个例子来展开说明
先来看第一段代码

这是与百度进行一次加密校验 , 认证你是合法用户 合法的应用
AipSpeech 是百度语音的客户端 认证成功之后,客户端将被开启,这里的client 就是已经开启的百度语音的客户端了
再来看第二段代码:

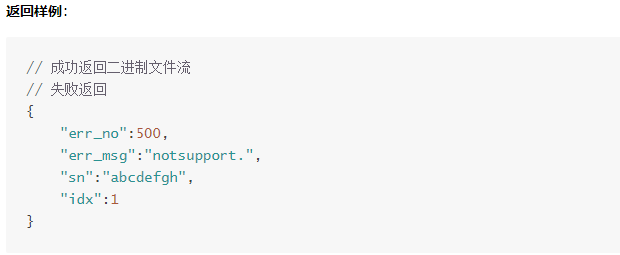
用百度语音客户端中的synthesis方法,并提供相关参数
成功可以得到音频文件,失败则返回一段错误信息
重点看一下 synthesis 这个方法 , 从 https://ai.baidu.com/docs#/TTS-Online-Python-SDK/top 来获得答案吧
从参数入手分析:

按照这些参数,从新发起一个语音合成

这次声音是不是与一点点萝莉了呢?
这都是语音语调的作用 0 - 9 其实就是 御姐音 - 萝莉音
这就是人工智能中的语音合成技术,调用百度的SDK,只用了5分钟,完成了1年的开发量,哈哈哈哈
一定要自己练习一下语音合成, 别把它玩儿坏了
三.语音识别:
哎,每次到这里,我都默默无语泪两行,声音这个东西格式太多样化了,如果要想让百度的SDK识别咱们的音频文件,就要想办法转变成百度SDK可以识别的格式PCM
目前DragonFire已知可以实现自动化转换格式并且屡试不爽的工具 : FFmpeg 这个工具的下载地址是 : 链接:https://pan.baidu.com/s/1jonSAa_TG2XuaJEy3iTmHg 密码:w6hk
FFmpeg 环境变量配置:
首先你要解压缩,然后找到bin目录,我的目录是 C:\ffmpeg\bin
然后 以 windows 10 为例,配置环境变量

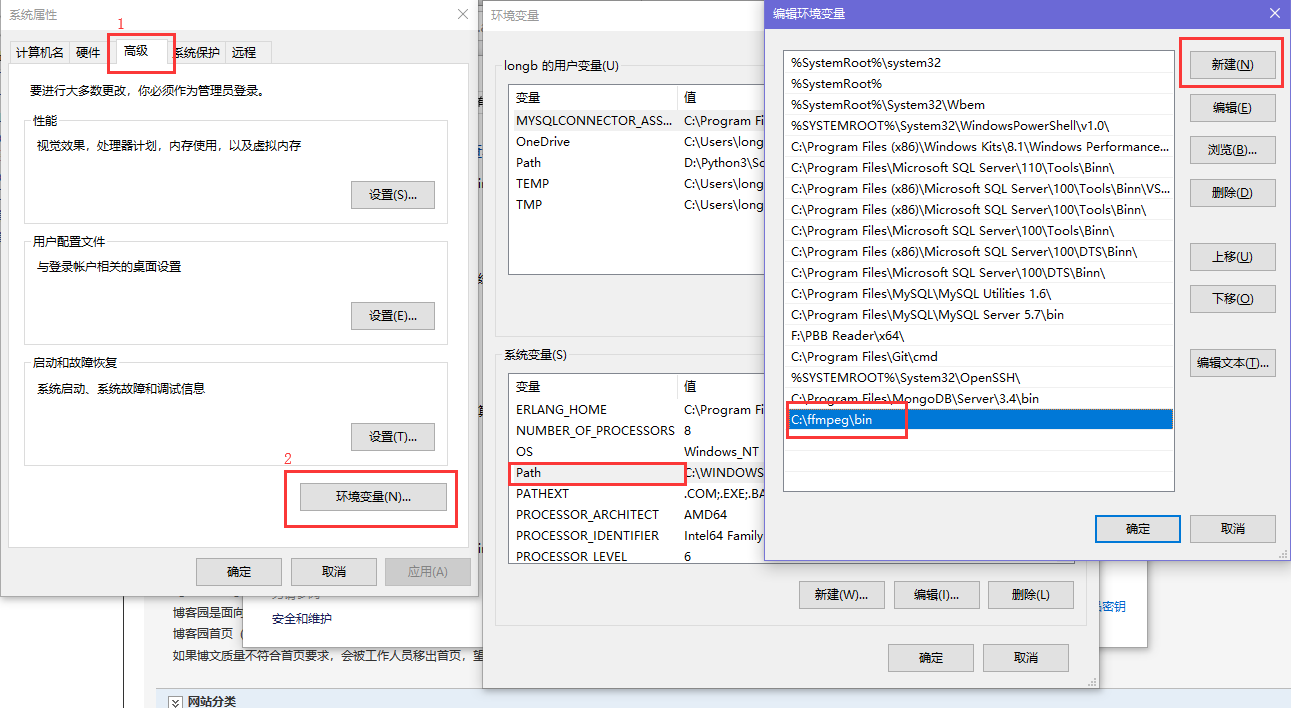
如果没搞明白的话,我也没有办法了,这么清晰这么明白
尝试一下,是否配置成功
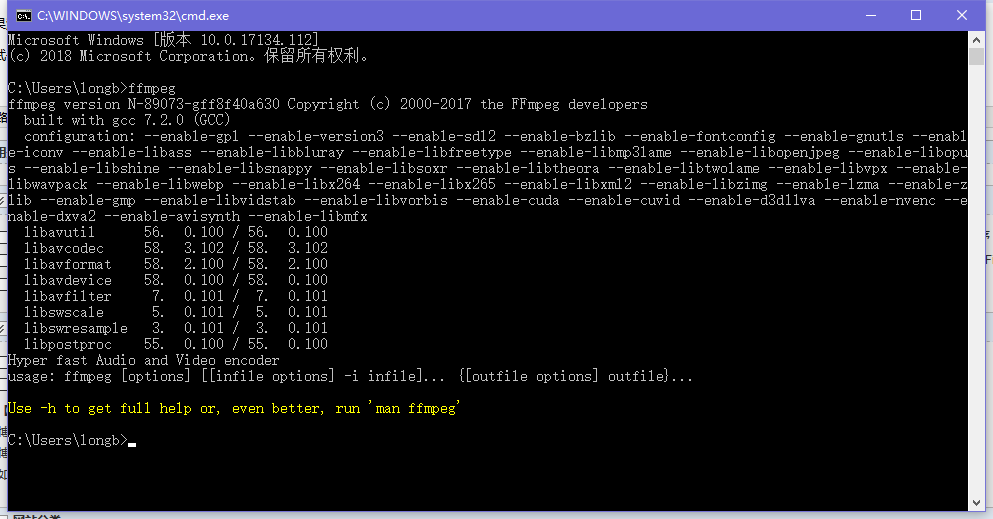
看到这个界面就算配置成功了,配置成功有什么用呢, 这个工具可以将wav wma mp3 等音频文件转换为 pcm 无压缩音频文件
做一个测试,首先要打开windows的录音机,录制一段音频(说普通话)
现在假设录制的音频文件的名字为 audio.wav 放置在 D:\DragonFireAudio\
然后我们用命令行对这个 audio.wav 进行pcm格式的转换然后得到 audio.pcm
命令是 : ffmpeg -y -i audio.wav -acodec pcm_s16le -f s16le -ac 1 -ar 16000 audio.pcm
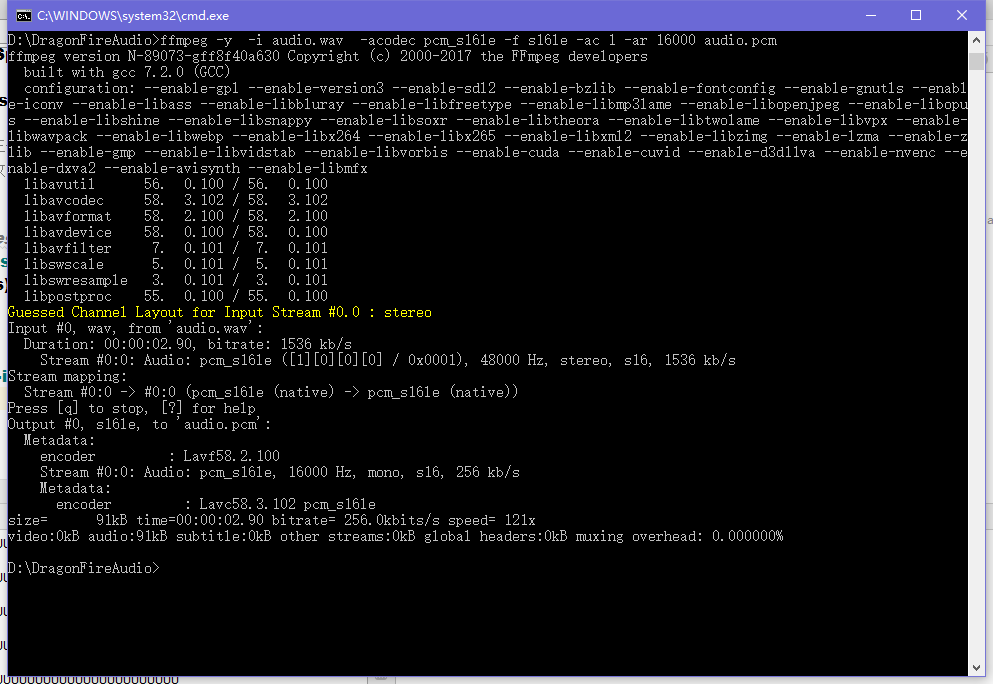
然后打开目录就可以看到pcm文件了

pcm文件已经得到了,赶紧进入正题吧
百度语音识别SDK的应用:
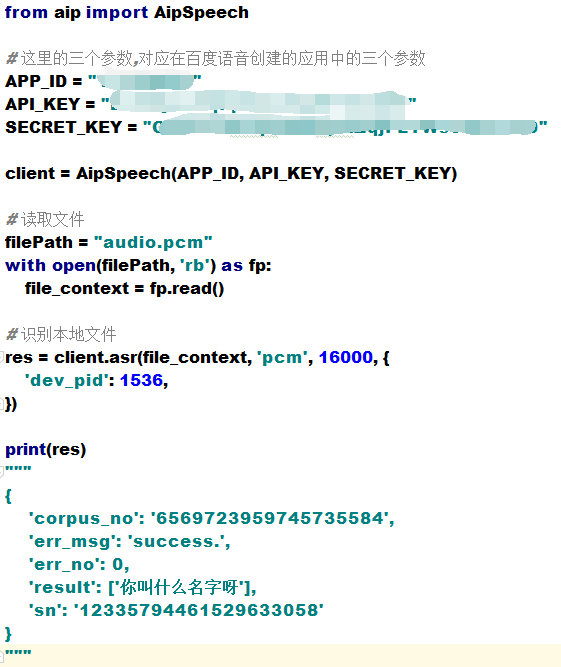
前提是你的audio.pcm 要与你当前的文件在同一个目录,还是分段看一下代码

读取文件的内容,file_context 是 audio.pcm 文件打开的二进制流

asr函数需要四个参数,第四个参数可以忽略,自有默认值,参照一下这些参数是做什么的
第一个参数: speech 音频文件流 建立包含语音内容的Buffer对象, 语音文件的格式,pcm 或者 wav 或者 amr。(虽说支持这么多格式,但是只有pcm的支持是最好的)
第二个参数: format 文件的格式,包括pcm(不压缩)、wav、amr (虽说支持这么多格式,但是只有pcm的支持是最好的)
第三个参数: rate 音频文件采样率 如果使用刚刚的FFmpeg的命令转换的,你的pcm文件就是16000
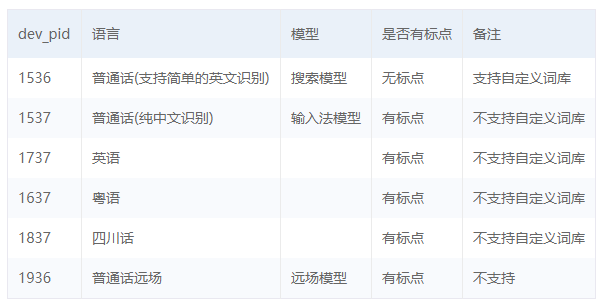
第四个参数: dev_pid 音频文件语言id 默认1537(普通话 输入法模型)
再来看下一段代码,打印返回结果:
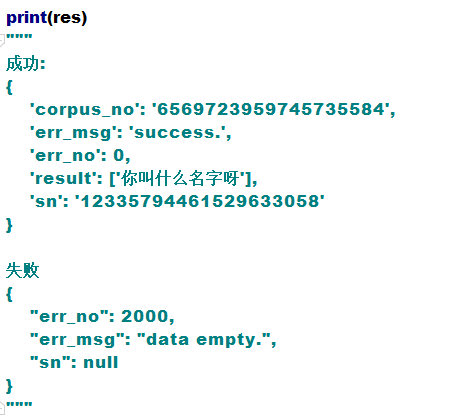
成功的dict中 result 就是我们要的识别文本
失败的dict中 err_no 就是我们要的错误编码,错误编码代表什么呢?

如果err_no不是0的话,就参照一下错误码表
到此百度AI语音部分的调用就结束了,是不是感觉很简单
刚刚学完练习一下:
1.尝试从语音识别中拿出result对应的中文
2.尝试你说一句话,然后让百度AI学你说话
3.尝试使用对话的方式,得到你叫什么名字,你今年几岁了,这样简单问题的答案

 浙公网安备 33010602011771号
浙公网安备 33010602011771号