全栈12期的崛起之捡点儿有用的说说
1.流程控制之如果你没听说过流程控制的话那么我告诉你就是ifelseforwhile这种控制代码走向的语句它是基础中的战斗机学会它们就基本学会了Python
2.函数之三大器生成器迭代器装饰器闭包各种动态参数列表生成器推导式
3.模块之根本搞不懂的re带你走出阴影的logging工作中可能常用某某及某某某
4.面向对象之其实能用到的东西就这么一点儿有什么可难得别总把它想的那么复杂其实它就是一种思想和编程方式不用面向对象一样可以写出好程序但是不会面向对象一定找不到好工作!
Every Body Let's Go !
一.流程控制
一.1.如果没有如果最终是什么结果 之 if else


1 if #如果 2 else #否则 3 4 if True #如果成立 5 print("OK") 6 else #否则 7 print("不OK")
1 if 1 > 2: #如果 2 print("what?") 3 elif 2==2: #否则如果 4 print("Oh Yeah!") 5 else #否则 6 print("Oh my baby")
本节结束,谢谢大家
一.2.般若波罗蜜哇又升仙了咦为什么要说又呢 之 for
1 for item in "今天你特别好看": #每次item从"你今天特别好看"中拿出来一个字 2 print(item) 3 else: #可有可无,for正常结束之后走这段儿代码 4 print("个屁啊!")
1 for index,item in enumerate(["你","今","天","真","二"]): # index,是下标哦,item是列表中的每一个元素 2 print(index,item)
本节结束,再次谢谢大家
一.3.跟着我左手右手一个慢动作,右手左手慢动作重播 之 while
1 while True : #如果 while 条件 为真时,继续执行之后的代码 2 print("Are you OK?")
1 for item in "123456789": 2 if item == "5": 3 print("确认过眼神,我遇到对的5") 4 continue # 遇到continue 之后的代码就不在继续了 5 print(item)
1 for item in "123456789": 2 if item == "5": 3 print("又是熟悉的5") 4 break # 遇到break 直接结束循环 5 6 print(item)
本节以及本章~结束,Thank you !!!! Are you ok??? Hello Thank you ,Thank you very much !
是的,所谓流程控制就是这些小东西
二.函数
二.1.你那么聪明根本都不需要看这个章节 之 def args kwargs
1 def func(参数1,参数2): # def 用来定义函数及函数名,参数1和参数2就是定义时的形参,也就是将来调用函数时必须要传入的参数 2 变量1 = 参数1+参数2 3 return 变量1
1 #我们定义参数的时候,无法确定函数中会有多少参数时,需要可变长参数,也就是动态参数的参与处理 这里我们的*args 和 **kwargs 就起了作用 2 3 *args 就是 将未定义且多余的 位置参数记录在内,偷偷的告诉你,args是个元祖,里面记录着你个函数传递的多余位置参数 4 5 **kwargs 就是 将多余的关键字参数记录在内,我用嘹亮且带有磁性的声音,偷偷告诉你,kwargs 其实是个dict哦,里面大概就是{"name":"Dragon","age":1+1+1+1+1+1+18}
1 def args_func(a,b,*args): # args 里面保存着除了ab之外的所有多余参数 2 print(args) # 这回知道是元祖了吧 3 for i in args: 4 print(i) 5 6 args_func(1,2,3,4,5,6) # 这里调用的时候1,2分别传递给a,b,那么3456就会保存在args里面哦
1 def kwargs_func(a, b, **kwargs): # kwargs 里面保存着除了ab之外其他关键字传入参的参数 2 print(kwargs) # 这回知道是字典了吧 3 for k, v in kwargs: 4 print(k, v) 5 6 7 kwargs_func(1, 2, c=3, d=4, e=5) # 这里调用的时候,12分别传递给a,b 那么c=3,d=4,e=5 就会保存在**kwargs里面哦
1 def args_kwargs_func(*args, **kwargs): # 这里一定要注意*args 要在 **kwargs之前 2 print(args) 3 print(kwargs) 4 5 6 args_kwargs_func(1, 2, a=1, b=2) # 12存入args a=1,b=2 存入kwargs,这里要注意的是关键字传参之后,不可以在位置传参了
本节结束,忘记它吧
二.2.你可以开启一个while "我没学懂" 模式 之 闭包函数
1 def close_func(a): # 外部函数 2 3 def inner(): # 内部函数 4 b = a + 1 # 这里的a 是外部函数的参数 , 也就是说内部函数引用 外部函数的参数 就是闭包函数 5 return b 6 7 return inner() # 注意啊,这里要返回内部函数的实行结果,也就是说,在外部函数中执行内部函数 就是闭包函数
1 def close_func(a): # 外部函数 2 def inner(): # 内部函数 3 b = a + 1 # 这里的a 是外部函数的参数 , 也就是说内部函数引用 外部函数的参数 就是闭包函数 4 return b 5 6 if isinstance(a, int): 7 res = inner() 8 else: 9 res = "请输入一个int类型" 10 return res # 注意啊,这里要返回内部函数的实行结果,也就是说,在外部函数中执行内部函数 就是闭包函数 11 12 print(close_func("123"))
本节结束,趁着热乎劲儿,赶紧往下看,算我求求你
二.3.break 上面的 再次 while "我没学会" 模式 之 装饰器 (while true : 这里是重点,这里是重点,这里是重点)
概念:装饰器是什么
装饰器 就是 不改变函数的调用方式,为函数添加功能
1 # 现在我们有一个函数,返回当前系统时间 2 import datetime 3 4 def see_time(): 5 return datetime.datetime.now() 6 7 print(see_time()) 8 9 # 2018-05-31 18:48:34.151397 10 11 #那么问题来了,我想看到的结果是 "当前系统时间为:2018-05-31 18:48:34.151397" 但是函数已经写定了,我们又没有权限修改怎么办?
为了能够的到"当前系统时间为:2018-05-31 18:52:11.550643" 并且不能更改函数本身,怎么办呢?
装饰器这个时候就起到作用了,已知: see_time 会返回 "2018-05-31 18:52:11.550643"系统时间 ,在它之间 加上 "当前系统时间为:" 就可以了对吧
我们用装饰器来试一下,顺便讲解一下装饰器:
1 def os_time(func): # 2.那么现在的func 就是 see_time 了 如果func加了()的话是不是就运行了呀,所以func现在是一个等待被运行的函数 2 def add_str(): # 5.如果上面你都看明白了,这里你就根本不会发愁了.add_str+()运行 3 time_str = func() # 6. 这里就是我们刚才传入的函数 see_time 记不记得? 不一样的是这里加了()运行了函数,time_str 的结果就是当前的系统时间 4 time_str = "当前系统时间为:" + str(time_str)# 7. 在系统时间的前面加上字符串 5 6 return time_str # 8. 返回拼接好的字符串 OK 搞定了 7 8 return add_str # 3. 哎?为什么不运行我们的func(see_time)呢,却返回了一个内部函数,寻找4来获得答案吧 9 10 import datetime 11 12 @os_time # 1.这里相当有意思,@os_time 相当于 os_time(see_time) , 函数see_time 被当成参数传递给了os_time 13 def see_time(): 14 return datetime.datetime.now() 15 16 print(see_time()) # 4.这里我们运行的时候实际上是 os_time(see_time) 的返回结果:add_str这个函数,没明白的话,从1开始循环再看一次 17 18 # 当前系统时间为:2018-05-31 18:56:59.871307 19 #成功了
装饰器部分是有那么一点儿不好理解,但是它在日后工作中是很重要的,即使你不日,那也很重要
本节结束,重点之一,请务必搞懂
二.4.其实就是一大堆东西一个一个往出拿 之 迭代器
说到迭代器 捎带手 提一嘴 可迭代对象: str list tuple dict set
什么是可迭代对象呢,就是可以被 for item in xx 这个xx 就是可迭代对象 怎么来判断是不是可以被 xx 呢, 不是,可以迭代迭代呢,__iter__方法,只要有,就是可迭代对象,给我记住
迭代器与可迭代对象的区别在于 迭代器有一个 __next__() 方法
可迭代对象,通过调用__iter__()方法,得到一个迭代器,迭代器里面的元素,拿出来一次就没了,生成器也是一样哦
1 l = [1,2,3,4,5] 2 t = (1,2,3) 3 4 print(l,l.__iter__()) 5 print(t,t.__iter__()) 6 7 #[1, 2, 3, 4, 5] <list_iterator object at 0x037BDBB0> 8 #(1, 2, 3) <tuple_iterator object at 0x037BD190>
二.5.其实就是一大堆东西一个一个往出拿 之 生成器
生成器 我们可以理解为 自己写的迭代器
所谓生成器 就是 一个函数 里面 有一个 关键字 yield
我们来看一段代码:
1 def gener(): #这就是我们的生成器 2 print("第一次") 3 yield 1 4 print("第二次") 5 yield 2 6 print("第三次") 7 yield 3 8 9 g = gener() # 生成器加括号得到我们的生成器对象 <generator object gener at 0x0545B390> 10 print(g) 11 12 for i in range(3): # 我分别从g这个生成器对象中,__next__()了三次,每一次,都是yield 的结果 13 print(g.__next__())
1 def gener(): #这就是我们的生成器 2 print("第一次") 3 yield 1 4 print("第二次") 5 yield 2 6 print("第三次") 7 yield 3 8 9 g = gener()# 生成器加括号得到我们的生成器对象 <generator object gener at 0x0545B390> 10 print(g) 11 12 for i in g: 13 print(i) 14 15 #由此见得,生成器其实也是一个可迭代对象吧
1 def gener(): 2 for i in range(3): 3 a = yield i # yield 神奇的地方来了, 它悄悄的返回了 i 并且等待着接收一个值传递给 a 4 print(a) 5 if a == "ok": 6 return 7 8 g = gener() 9 10 # for i in g: 11 # print(i) # 0 1 2 12 13 g.__next__() # 如果第一次使用send的时候一定要传递一个None 否则会出错的,因为代码还没有走到yield 所以没有容器等你传值 14 #使用next方法,可以让代码停留在yield上面 15 # g.send("第一次send") 16 g.send("ok") # StopIteration 停止迭代 因为遇到了 return 17 g.send("第二次send")
yield关键字,很关键,很多开源的大项目解决并发问题,用的都是yield
本节结束,想赚更多的工资 12K 以上的话,yield 一定要弄明白哦
二.6.推导而不是推倒 之 推导式
推导式举两个怀柔大板栗:
列表推导式:很(yao)重(xue)要(hui)
1 li = [i for i in range(10)] # 简单的列表推导式,就是在列表内写一个for循环对吧 2 print(li) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] 3 4 lis = [i for i in range(10) if i % 2 == 0] # 这是带if 条件的列表推导式 5 print(lis) # [0, 2, 4, 6, 8]
生成器推导式 : 也(te)很(bie)重要
1 gener = (i for i in range(10)) # 简单的生成器推导式,就是在元组内写一个for循环对吧 2 print(gener) # <generator object <genexpr> at 0x04F9B3C0> 3 4 geners = (i for i in range(10) if i % 2 == 0) # 这是带if 条件的生成器推导式 5 print(geners) # <generator object <genexpr> at 0x04F9B3F0>
从上述来看,列表推导式和生成器推导式只是[] 与 () 的区别
但是实际上,生成器推导式的效率非常高,但可控性很差,比如不直观,用一次就没了
相对而言列表推导式的效率比较低,但是可控性强,可以反复利用,而且数据显示很直观
本节及本章结束,内容较多,希望大家,都(bi)能(xu)学会
三.模块
三.1.任何项目,任何,注意任何项目都得用 之 logging 模块
刚刚接触logging模块的你,你说啥?哦,啊?
就让我来重新给你引入一次logging模块的应用吧,没时间解释了, Fuck Car !!!
1 import logging # 导入我们的logging模块 2 3 # 我们写一条日志进去,其实里面有好多好多好多好多东西,比如写日志的时间,哪个函数写的日志,哪个级别的日志,当然还有我们的message信息 4 # 一大堆东西一起装进去,才算是一条日志哦 5 6 my_log = logging.getLogger("my_log") # 创建一个我们log容器 名字叫my_log 7 my_log.setLevel(logging.DEBUG) # 我们这个my_log容器 可以存放DEBUG及其以下界别的日志 8 9 # 容器已经有了,但是我们还没有显示信息的地方(比如在控制台,比如在文件),那么我们就来建立一个显示信息的地方 10 sh = logging.StreamHandler() # StreamHandler 这就是流处理器,也就是咱们的控制台, sh 等于 我们实例化了一个控制台 11 sh.setLevel(logging.DEBUG) # 这个sh控制台 只能显示Debug及其以下级别的日志信息 12 13 # OK我们得到了 控制台打印 信息了 , 但是 日志里面那么多信息,要拿出来什么呢? 14 # 就拿这些好了,时间+日志级别+message,用 时间 - 日志级别 : message 这种格式输出 15 my_log_fmt = logging.Formatter("%(asctime)s - %(levelname)s : %(message)s") # 格式化 打印字符串 16 #如果不进行格式化处理的话,你直接输出日志的话,只能获得日志的message信息 17 18 # 只有在sh 这个控制台上输出的时候 使用 my_log_fmt 这种样式 19 sh.setFormatter(my_log_fmt) 20 21 # 让我们的my_log 通过sh 进行日志输出处理 22 my_log.addHandler(sh) 23 24 #debug输出 25 my_log.debug("我来啦") 26 #error输出 27 my_log.error("我来啦") 28 #info输出 29 my_log.info("我来啦") 30 #warning输出 31 my_log.warning("我来啦")
1 import logging # 导入我们的logging模块 2 3 # 我们写一条日志进去,其实里面有好多好多好多好多东西,比如写日志的时间,哪个函数写的日志,哪个级别的日志,当然还有我们的message信息 4 # 一大堆东西一起装进去,才算是一条日志哦 5 6 my_log = logging.getLogger("my_log") # 创建一个我们log容器 名字叫my_log 7 my_log.setLevel(logging.DEBUG) # 我们这个my_log容器 可以存放DEBUG及其以下界别的日志 8 9 # 容器已经有了,但是我们还没有显示信息的地方(比如在控制台,比如在文件),那么我们就来建立一个显示信息的地方 10 sh = logging.StreamHandler() # StreamHandler 这就是流处理器,也就是咱们的控制台, sh 等于 我们实例化了一个控制台 11 sh.setLevel(logging.DEBUG) # 这个sh控制台 只能显示Debug及其以下级别的日志信息 12 13 fh = logging.FileHandler("mylog.log") # 这里我们建立一个文件处理日志的地方 14 fh.setLevel(logging.DEBUG) # fh 的日志输出级别 15 16 17 # OK我们得到了 控制台打印 信息了 , 但是 日志里面那么多信息,要拿出来什么呢? 18 # 就拿这些好了,时间+日志级别+message,用 时间 - 日志级别 : message 这种格式输出 19 my_log_fmt = logging.Formatter("%(asctime)s - %(levelname)s : %(message)s") # 格式化 打印字符串 20 #如果不进行格式化处理的话,你直接输出日志的话,只能获得日志的message信息 21 22 # 只有在sh 这个控制台上输出的时候 使用 my_log_fmt 这种样式 23 sh.setFormatter(my_log_fmt) 24 25 # 只有在fh 这个文件上输出的时候 使用my_log_fmt 这种样式 样式可以在定制一个新的,这里我们就用同一个了 26 fh.setFormatter(my_log_fmt) 27 28 # 让我们的my_log 通过sh 控制台进行日志输出处理 29 my_log.addHandler(sh) 30 31 # 让我们的my_log 通过fh 文件进行日志输出处理 32 my_log.addHandler(fh) 33 34 35 #debug输出 36 my_log.debug("我来啦") 37 #error输出 38 my_log.error("我来啦") 39 #info输出 40 my_log.info("我来啦") 41 #warning输出 42 my_log.warning("我来啦")
本节结束,关于logging的打印问题,是初学者最头疼的,想学如果为一个项目导入日志模块的留言或者举手,或者大声的喊:"我要!"
三.2.锻炼逻辑思维弄得自己脑瓜子爆炸 之 re 模块
看到 re 我就脑瓜发热 对 re的汉语拼音 就是 热
re是正则匹配模块,根据你的条件要求,一点一点儿的将你的字符串匹配出来
记住两个常用的方法就好了
findall
1 import re 2 # 正则表达式 + 字符串 3 print(re.findall('\w','hello python 123')) 4 #['h', 'e', 'l', 'l', 'o', 'p', 'y', 't', 'h', 'o', 'n', '1', '2', '3'] 5 print(re.findall('\w+','hello python 123')) 6 #['hello', 'python', '123'] 7 print(re.findall('\d',"hello python 123")) 8 # ['1', '2', '3'] 9 print(re.findall('\d+',"hello python 123")) 10 #["123"]
search
1 import re 2 print(re.search("<(?P<tag_name>\w+)>\w+</(?P=tag_name)>","<h1>hello</h1>").group()) 3 4 #<h1>hello</h1>
正则:

大家如果觉得re模块很难的话,尽可能去掌握吧,因为对文件字符串筛选的话,只有re模块了
如果做爬虫的re模块也要会的,不过到时候你们学到爬虫的时候,需要不需要用re就不知道了,我只能帮你到这里了
本节结束,对不起大家,re 模块太头(e)疼(xin)了
三.3.除非你不是人类 之 time 模块
其实我就是告诉大家这个模块很常用,记住里面的几个方法就好
1 import time 2 3 print(time.time()) # 显示当前时间戳 4 time.sleep(1) # 当前进程停顿 1 秒 5 print(time.ctime(1527774418.3636074)) # 时间戳转日期 6 7 #其他的方法大家可以试试,已经不是很重要了
这里给大家补充一个模块
1 import datetime 2 print(datetime.datetime.now()) # 这个就是拿到一个你能看得懂的时间字符串
三.4.不停的猜 猜 猜 又卜了一卦 之 random 模块
random 是随机模块,这里面的随机性太大了,老狠了
1 import random 2 3 # random 4 print(random.random()) # 0-1之间的小数 5 # randint 6 print(random.randint(0, 100)) # 0-100之间的整数 7 # choice 8 print(random.choice([1, 2, 3, 4, 5, 6])) # 从可迭代对象中随机抽取一个 9 # sample 10 print(random.sample([1, 2, 3, 4, 5, 6], 3)) # 从可迭代对象中随机抽取3个
三.5.兄弟就靠你了 之 os 模块
os 模块其实是集成了很多操作系统的方法,比如创建文件夹,拼接路径,删除文件,创建文件等等
1 import os 2 os.path.join("a","b") # 组合路径 a/b 3 os.system("ls") # 执行系统命令 4 os.sep() # 获取当前操作系统的路径分隔符 5 os.path.dirname(__file__) # 获取当前文件的所在目录
三.6.只能前进不能后退的不归路 之 hashlib 模块
乖,我咱们就说一个md5,其他的使用方法都一样啦
1 import hashlib 2 str = "abc".encode("utf8") 3 md = hashlib.md5(str) # 实例化一个MD5的摘要对象,并且给他一个utf8编码的bytes 4 print(md.hexdigest()) # 900150983cd24fb0d6963f7d28e17f72
需要带一嘴,md5只是单向的算法,一旦加密则不可逆
三.7.字符串字符串字符串 之 json 模块
只要你是个说得上名的数据类型,我全给你弄成字符串,就问你服不服
1 import json 2 3 # 我们做一个字典 4 dic = { 5 "name": "Dragon", 6 "age": 20, 7 "hobby": ["摩托车", "骑车"], 8 "other": { 9 "say": "hello", 10 "see": "beautiful girl", 11 } 12 } 13 json_dic = json.dumps(dic) # json序列化 14 15 print(type(json_dic), json_dic) 16 17 # <class 'str'> {"name": "Dragon", "age": 20, "hobby": ["\u6469\u6258\u8f66", "\u9a91\u8f66"], "other": {"say": "hello", "see": "beautiful girl"}} 18 19 loads_dic = json.loads(json_dic) # json 反序列化 20 21 print(type(loads_dic), loads_dic) 22 23 # <class 'dict'> {'name': 'Dragon', 'age': 20, 'hobby': ['摩托车', '骑车'], 'other': {'say': 'hello', 'see': 'beautiful girl'}}
json 用于数据传输上,非常的爽
四.面向对象
1.面向对象的小概念
什么是面向对象,其实就是把某物抽象出来,再实例化的过程就叫面向对象
举个小例子,桌子是木头那么桌子可以归为木头类,板凳是木头可以归为木头类,那么生活中有无数的木头类的东西,都可以使用木头类
木头类中有什么属性呢?怕火,漂浮,可塑性等等
那么用木头做的桌子板凳是不是也可以漂浮啊,是不是也怕火啊,是不是也能把桌子凳子重新改良塑性啊
桌子用来摆放物品,凳子用来坐人,桌子也可以坐人但是不稳,凳子也可以摆放物品但是不稳
笼统的说,大家其实都知道这个概念,但是怎么用呢?
2.Class 与 def func 与 属性
类有属性,比如说木头怕火,就是木头的属性
1 class wool: 2 fire = "燃烧了" 3 water = "漂浮了" 4 5 6 zhuozi = wool() # 实例化了一个桌子 7 8 print(zhuozi.fire) # 看看桌子遇到火会怎么样 9 print(zhuozi.water) # 看看桌子遇到水会怎么样
用木头做了一张桌子,桌子可以摆放物品.摆放物品就是方法
木头是不能摆放物品的,但是桌子可以,桌子是木头实例化出来的对象,并且还有了自己的方法
3.继承 派生 继承顺序 重载
继承 派生
1 class wool: 2 fire = "燃烧了" 3 water = "漂浮了" 4 5 class diske(wool): # diske 继承了wool ,那么diske就是 wool的派生类,也就是所谓的子类,wool就是diske的父类也叫超类 6 name = "桌子" 7 def baifang(self,obj): 8 return f"{self.name}摆放了{obj}" 9 10 zhuozi = diske() # 实例化diske 11 12 print(zhuozi.name) 13 print(zhuozi.fire) # diske 是 wool 的子类 也同样继承了wool 中的fire属性 14 print(zhuozi.water) #diske 是 wool 的子类 也同样继承了wool 中的water属性 15 16 zhuozi.name = "Dragon的桌子" # 为diske中独有的属性name赋值 17 print(zhuozi.baifang("杯子")) # 执行摆放的方法
继承顺序
在Python中的面向对象很特殊,它有一个新玩儿法,就是多重继承,我一个类可以继承很多很多的类,换言之,一个儿子有一群爸爸(他的妈妈真的太幸福了)
1 class Wool: 2 fire = "燃烧了" 3 water = "漂浮了" 4 5 class Tools: # 我们有创建了一个工具类 6 fire = "灭火" # 工具类遇到了火就要给他灭了 7 def user(self): 8 return "工具开始使用了" 9 10 11 class Diske(Tools,Wool,): # diske 既是Tools的子类也是Wool的子类,可以调用两个类里面的属性和方法 12 name = "桌子" 13 def baifang(self,obj): 14 return f"{self.name}摆放了{obj}" 15 16 zhuozi = Diske() # 实例化diske 17 18 print(zhuozi.name) 19 print(zhuozi.fire) # 这里的fire的属性决定权在与谁是Diske的第一个含有fire属性的父类 20 print(zhuozi.water) 21 22 zhuozi.name = "Dragon的桌子" # 为diske中独有的属性name赋值 23 print(zhuozi.baifang("杯子")) # 执行摆放的方法
4.多态(pep8,)
一个事物的多种形态
我们做个糖炒栗子
1 class Animal: 2 def talk(self): 3 return ".........." 4 5 6 class Dog(Animal): 7 def talk(self): 8 return "汪汪汪" 9 10 11 class People(Animal): 12 def talk(self): 13 return "Hello" 14 15 16 class TuBoShu(Animal): 17 def talk(self): 18 return "啊~!!!!!!!!!!" 19 20 21 class WuGui(Animal): 22 pass 23 24 25 wu_pei_qi = People() 26 dog = Dog() 27 tu_bo_shu = TuBoShu() 28 wu_gui = WuGui() 29 30 print(wu_pei_qi.talk()) 31 print(dog.talk()) 32 print(tu_bo_shu.talk()) 33 print(wu_gui.talk()) 34 35 36 #看起来像,那么就是的概念
5.封装 __a
__变量 这样的话无法直接调用
def __方法名 这样的话,只能在对象内部调用无法通过实例化的对象调用
1 class MyFlies: 2 __file_name = "mylog.log" 3 def __open_file(self): 4 with open(self.__file_name,"rb") as f: 5 return f.read() 6 7 def look_file(self): 8 return self.__open_file() 9 10 11 new_file = MyFlies() 12 13 print(new_file.look_file())
6.classmethod staticmethod
classmethod 类调用
staticmethod 只是定义在类里面的一个方法,类对象都可调用
1 class MyFlies: 2 3 __file_name="mylog.log" 4 5 @classmethod 6 def open_file(cls,filename): 7 print(cls.__file_name) 8 with open(filename,"rb") as f: 9 return f.read() 10 11 @staticmethod 12 def look_file(filename): 13 print("根本不知道__file_name的存在") 14 with open(filename,"rb") as f: 15 return f.read() 16 17 def self_open_file(self,filename): 18 print(self.__file_name) 19 with open(filename, "rb") as f: 20 return f.read() 21 22 23 new_file = MyFlies() 24 25 26 print(new_file.look_file("mylog.log")) 27 print(new_file.open_file("mylog.log")) 28 print(new_file.self_open_file("mylog.log")) 29 print(MyFlies.open_file("mylog.log")) 30 print(MyFlies.look_file("mylog.log"))
7.反射 hashattr getattr setattr delattr
1 class DragonFire: 2 name="123" 3 age = 20 4 5 def tall(self): 6 return "aaaaaaa" 7 8 def walk(self): 9 return "wwwwww" 10 11 12 df = DragonFire() 13 14 print(hasattr(df,"tall")) 15 print(hasattr(df,"say")) 16 17 print(getattr(df,"walk","")) 18 print(getattr(df,"say","not func")) 19 20 setattr(df,"gender","Man") 21 print(df.gender) 22 print(df.__dict__) 23 24 delattr(df,"gender") 25 print(df.__dict__)
8.__方法概念
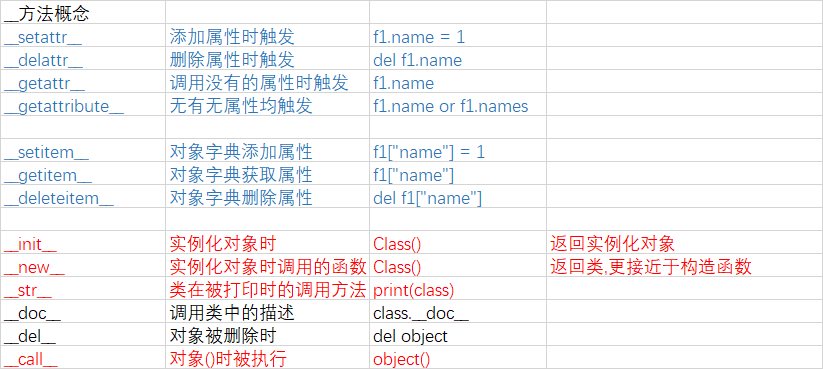
1.__setattr getattr delattr getattrbute__
2.__setitem
3.__init
4.__new
5.__str
6.__doc
7.__del
8.__call

 浙公网安备 33010602011771号
浙公网安备 33010602011771号