

爬取全部的校园新闻
作业来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3002
1.从新闻url获取新闻详情: 字典,anews
import requests from bs4 import BeautifulSoup from datetime import datetime import re def click(url): id=re.findall('(\d{1,5})',url)[-1] clickUrl='http://oa.gzcc.cn/api.php?op=count&id={}&modelid=80'.format(id) resClick=requests.get(clickUrl) newsClick=int(resClick.text.split('.html')[-1].lstrip("('").rstrip("');")) return newsClick def newsdt(showinfo): newsDate=showinfo.split()[0].split(":")[1] newsTime=showinfo.split()[1] newsDT=newsDate+' '+newsTime dt=datetime.strptime(newsDT,'%Y-%m-%d %H:%M:%S') return dt def anewsDate(url): newsDetail={} res=requests.get(url) res.encoding='utf-8' soup=BeautifulSoup(res.text,'html.parser') newsDetail['nenewsTitle']=soup.select('.show-title')[0].text showinfo=soup.select('.show-info')[0].text newsDetail['newsDT']=newsdt(showinfo) newsDetail['newsClick']=click(newsUrl) return newsDetail newsUrl='http://news.gzcc.cn/html/2005/xiaoyuanxinwen_0710/4.html' anewsDate(newsUrl) res = requests.get('http://news.gzcc.cn/html/xiaoyuanxinwen/') res.encoding='utf-8' soup = BeautifulSoup(res.text,'html.parser') for news in soup.select('li'): if len(news.select('.news-list-title'))>0: newsUrl=news.select('a')[0]['href'] print(anews(newUrl))

2.从列表页的url获取新闻url:列表append(字典) alist
listUrl='http://news.gzcc.cn/html/xiaoyuanxinwen/'
res = requests.get(listUrl)
res.encoding='utf-8'
soup = BeautifulSoup(res.text,'html.parser')
newsList=[]
for news in soup.select('li'):
if len(news.select('.news-list-title'))>0:
newsUrl=news.select('a')[0]['href']
newsDesc=news.select('.news-list-description')[0].text
newsDict=anews(newsUrl)
newsDict['description']=newsDesc
newsList.append(newsDict)
print(newsList)
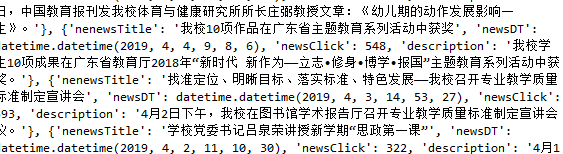
3.生成所页列表页的url并获取全部新闻 :列表extend(列表) allnews
def alist(url): res=requests.get(listUrl) res.encoding='utf-8' soup = BeautifulSoup(res.text,'html.parser') newsList=[] for news in soup.select('li'): if len(news.select('.news-list-title'))>0: newsURL=news.select('a')[0]['href'] newsDesc=news.select('.news-list-description')[0].text newsDict=anews(newsURL) newsDict['description']=newsDesc newsList.append(newsDict) return newsList listUrl='http://news.gzcc.cn/html/xiaoyuanxinwen/' alist(listUrl) allnews=[] for i in range(77,87): listUrl='http://news.gzcc.cn/html/xiaoyuanxinwen/{}.html'.format(i) allnews.extend(alist(listUrl)) len(allnews) print(allnews)

4.设置合理的爬取间隔
import time import random allnews=[] for h in range(30,40): a='http://news.gzcc.cn/html/xiaoyuanxinwen/{}.html'.format(h) alist=newsinfo(a) time.sleep(random.random()*3) allnews.extend(alist)
5.用pandas做简单的数据处理并保存
保存到csv或excel文件


