
理解爬虫原理
作业要求:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/2881
1. 简单说明爬虫原理:
网络爬虫是捜索引擎抓取系统的重要组成部分。爬虫的主要目的是将互联网上的网页下载到本地形成一个或联网内容的镜像备份。这篇博客主要对爬虫以及抓取系统进行一个简单的概述。
2. 理解爬虫开发过程:
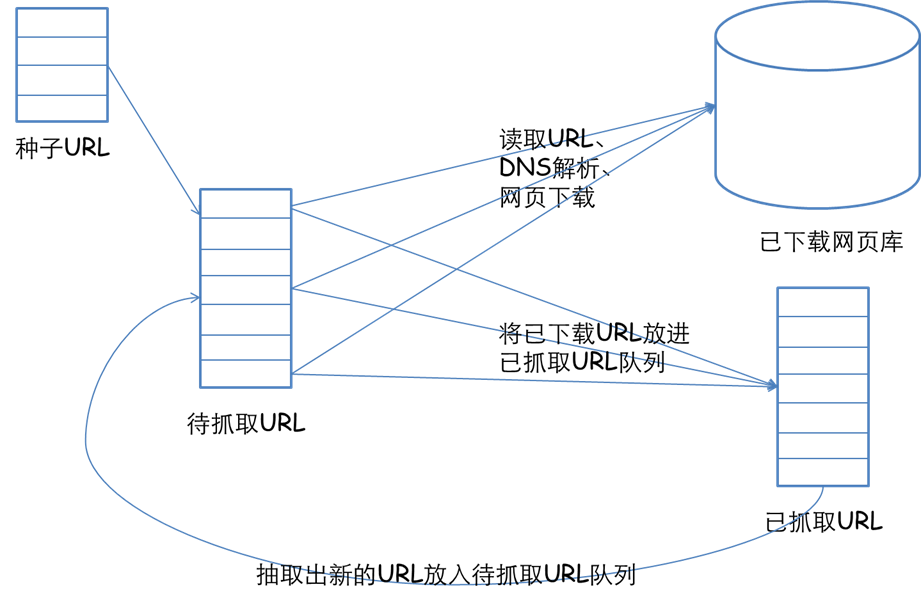
1、发起请求
使用http库向目标站点发起请求,即发送一个Request
Request包含:请求头、请求体等
Request模块缺陷:不能执行JS 和CSS 代码
2、获取响应内容
如果服务器能正常响应,则会得到一个Response
Response包含:html,json,图片,视频等
3、解析内容
解析html数据:正则表达式(RE模块),第三方解析库如Beautifulsoup,pyquery等
解析json数据:json模块
解析二进制数据:以wb的方式写入文件
4、保存数据
数据库(MySQL,Mongdb、Redis)
文件
2).使用 requests 库抓取网站数据;
requests.get(url) 获取校园新闻首页html代码
import requests url = 'http://news.gzcc.cn/html/2019/xiaoyuanxinwen_0320/11029.html' res=requests.get(url) res.encoding='UTF-8'
3).了解网页
写一个简单的html文件,包含多个标签,类,id
<!doctype html> <html class="no-js" lang=""> <head> </head> <body bgcolor="#eeeeee"> <div id="header" class=‘main_title’> <h1>Power By Urara</h1> </div> <div id="nav" class='nav_content'> <h1>live up!<h1> <li>prous!<li> <li>钉子<li> </div> <div id="mid-down" align="center" class='mid'> <a href="http://www.bing.com"><font id="font5">qop</font></a><p> <hr> </div> <div id="footer" class='footer'> live up! o1.v </div> </body> </html>
4).使用 Beautiful Soup 解析网页;
import requests from bs4 import BeautifulSoup url='http://www.bing.com' parser = 'html.parser' soup = BeautifulSoup(requests.get(url), parser) tsel1=soup.select('.show-title') tsel2=soup.select('a') tfind1=soup.find(id='main') tfind2=soup.find(id='mian').find_all('a')
3.提取一篇校园新闻的标题、发布时间、发布单位
url = 'http://news.gzcc.cn/html/2019/xiaoyuanxinwen_0320/11029.html'
import requests from bs4 import BeautifulSoup parser = 'html.parser' url = 'http://news.gzcc.cn/html/2019/xiaoyuanxinwen_0320/11029.html' res=requests.get(url) res.encoding='UTF-8' soup = BeautifulSoup(res.text, parser) for selsoup in soup.select('.show-nav'): title=soup.select('.show-title')[0].text msg=soup.select('.show-info')[0].text print('标题: '+title +' 信息:'+ msg)



