【机器学习】机器学习入门05 - 梯度下降法
1. 梯度下降法介绍
1.1 梯度
在多元函数微分学中,我们都接触过梯度(Gradient)的概念。
回顾一下,什么是梯度?
梯度的本意是一个向量(矢量),表示某一函数在该点处的方向导数沿着该方向取得最大值,即函数在该点处沿着该方向(此梯度的方向)变化最快,变化率最大(为该梯度的模)。
这是百度百科给出的解释。
事实上,梯度的定义,就是多元函数的偏导数组成的向量。以二元函数 f(x,y) 为例。fx, fy 分别表示 f 对x,y的偏导数。则 f 在(x, y)处的梯度grad f = ( fx(x,y), fy(x, y))
那么,梯度的概念,和机器学习有什么关系呢?
不难理解,对于损失函数,其梯度的方向指向误差增加最快的方向,大小为该点误差的增加率。因此,要找到损失最小的点,也就是找到梯度为0(或最接近0)的点。这就是梯度的概念对于机器学习的意义。而刚刚描述的思想,就是梯度下降法的雏形。
1.2 梯度下降法
梯度下降法实际上是一种迭代的算法。即从任意一点出发,每次向梯度方向移动微小距离,直到梯度等于0为止。
类似于迭代法解线性系统,从任意向量出发,利用迭代公式进行迭代,直到两次迭代结果足够接近。
以单变量的二次函数为例,其梯度下降法的迭代过程其实就是如图所示从θ0开始不断接近最低点的过程。
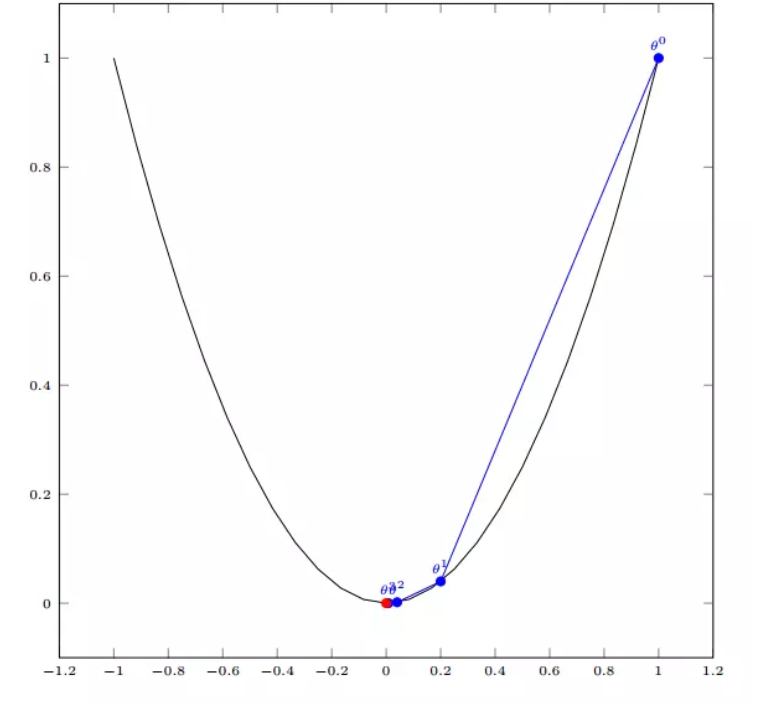
下面以线性回归为例,解释梯度下降法的流程。

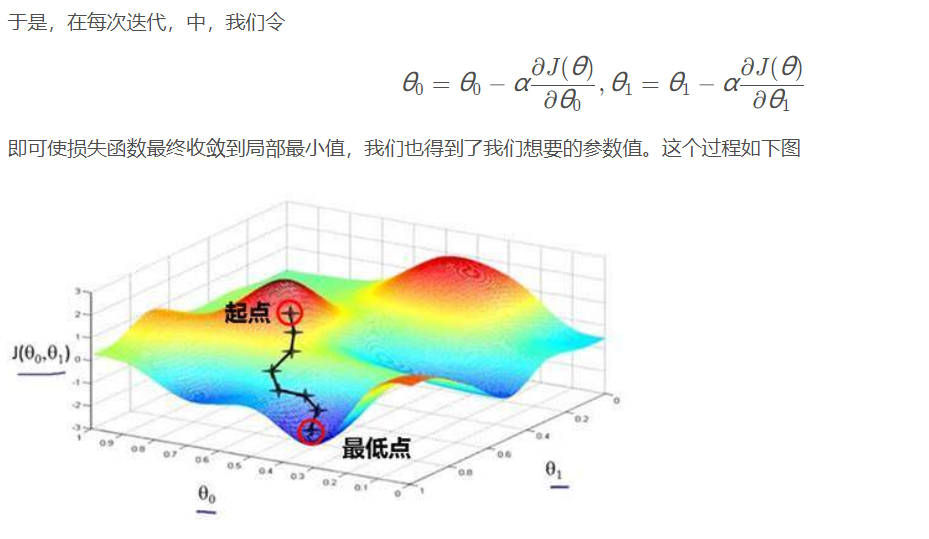
(以上摘自https://blog.csdn.net/neuf_soleil/article/details/82285497)
除此之外,以下几篇博文也值得参考:
https://www.jianshu.com/p/424b7b70df7b
https://blog.csdn.net/walilk/article/details/50978864
https://blog.csdn.net/pengchengliu/article/details/80932232
以及这篇知乎问答
https://www.zhihu.com/question/305638940
2. 梯度下降法实现
说完了复杂的数学推导,还是来看一下我们直接用得上的,梯度下降法的代码实现。
2.1 Python中的导数运算
python中有两种常见求导的方法,一种是使用Scipy库中的derivative方法,另一种就Sympy库中的diff方法。
1. Scipy
scipy.misc.derivative(func, x0, dx=1.0, n=1, args=(), order=3)[source]在一个点上找到函数的第n个导数。即给定一个函数,请使用间距为dx的中心差分公式来计算x0处的第n个导数。
参数:
func:需要求导的函数,只写参数名即可,不要写括号,否则会报错
x0:要求导的那个点,float类型
dx(可选):间距,应该是一个很小的数,float类型
n(可选):n阶导数。默认值为1,int类型
args(可选):参数元组
order(可选):使用的点数必须是奇数,int类型
def f(x):return x**3 + x**2derivative(f, 1.0, dx=1e-6)2. Sympy表达式求导
sympy是符号化运算库,能够实现表达式的求导。所谓符号化,是将数学公式以直观符号的形式输出。下面看几个例子就明白了。
from sympy import *# 符号化变量x = sy.Symbol('x')func = 1/(1+x**2)print("x:", type(x))print(func)print(diff(func, x))print(diff(func, x).subs(x, 3))print(diff(func, x).subs(x, 3).evalf())
具体可参考:https://www.cnblogs.com/zyg123/
2.2 梯度下降法的实现
首先我们需要定义一个点 作为初始值,正常应该是随机的点,但是这里先直接定为0。然后需要定义学习率 ,也就是每次下降的步长。这样的话,点 每次沿着梯度的反方向移动 距离,即 ,然后循环这一下降过程。
那么还有一个问题:如何结束循环呢?梯度下降的目的是找到一个点,使得损失函数值最小,因为梯度是不断下降的,所以新的点对应的损失函数值在不断减小,但是差值会越来越小,因此我们可以设定一个非常小的数作为阈值,如果说损失函数的差值减小到比阈值还小,我们就认为已经找到了。
1 def gradient_descent(initial_theta, eta, epsilon=1e-6): 2 theta = initial_theta 3 theta_history.append(theta) 4 while True: 5 # 每一轮循环后,要求当前这个点的梯度是多少 6 gradient = dLF(theta) 7 last_theta = theta 8 # 移动点,沿梯度的反方向移动步长eta 9 theta = theta - eta * gradient 10 theta_history.append(theta) 11 # 判断theta是否达到损失函数最小值的位置 12 if(abs(lossFunction(theta) - lossFunction(last_theta)) < epsilon): 13 break 14 15 def plot_theta_history(): 16 plt.plot(plot_x,plot_y) 17 plt.plot(np.array(theta_history), lossFunction(np.array(theta_history)), color='red', marker='o') 18 plt.show()
以上就是梯度下降法的Python实现

 浙公网安备 33010602011771号
浙公网安备 33010602011771号