


使用lambda表达式分别 根据 单个字段、多个字段,分组求和
示意图:
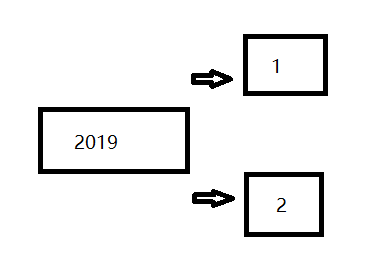
1、根据 单个字段,分组求和:根据2019这个字段,计算一个list集合里,同属于2019的某个字段累加和
2、根据 多个字段,分组求和:
(1)先根据2019这个字段,再根据1这个字段,计算一个list集合里,同属于2019和1的某个字段累加和;
(2)先根据2019这个字段,再根据2这个字段,计算一个list集合里,同属于2019和2的某个字段累加和;
代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 | import com.pojo.DataStatisticsResultMiddle;import java.util.ArrayList;import java.util.List;import java.util.LongSummaryStatistics;import java.util.Map;import java.util.stream.Collectors;public class Test { public static void main(String[] args) { List<DataStatisticsResultMiddle> li = new ArrayList<>(); DataStatisticsResultMiddle middle1 = new DataStatisticsResultMiddle(); middle1.setDatas("2019"); middle1.setCarrierid("1"); middle1.setEnusers(100L); DataStatisticsResultMiddle middle2 = new DataStatisticsResultMiddle(); middle2.setDatas("2019"); middle2.setCarrierid("1"); middle2.setEnusers(150L); DataStatisticsResultMiddle middle3 = new DataStatisticsResultMiddle(); middle3.setDatas("2019"); middle3.setCarrierid("1"); middle3.setEnusers(200L); DataStatisticsResultMiddle middle4 = new DataStatisticsResultMiddle(); middle4.setDatas("2019"); middle4.setCarrierid("2"); middle4.setEnusers(400L); DataStatisticsResultMiddle middle5 = new DataStatisticsResultMiddle(); middle5.setDatas("2019"); middle5.setCarrierid("2"); middle5.setEnusers(500L); DataStatisticsResultMiddle middle6 = new DataStatisticsResultMiddle(); middle6.setDatas("2019"); middle6.setCarrierid("2"); middle6.setEnusers(600L); li.add(middle1); li.add(middle2); li.add(middle3); li.add(middle4); li.add(middle5); li.add(middle6); //单个字段,分组求和(datas) Map<String, LongSummaryStatistics> enusersCollect1 = li.stream().collect(Collectors.groupingBy(DataStatisticsResultMiddle:: getDatas, Collectors.summarizingLong(DataStatisticsResultMiddle :: getEnusers))); LongSummaryStatistics enusers = enusersCollect1.get("2019"); System.out.println(enusers.getSum()); System.out.println("分割线***********************************"); //多个字段,分组求和(先按datas分组,再按Carrierid分组,求和) Map<String, Map<String, LongSummaryStatistics>> enusersCollect2 = li.stream().collect(Collectors.groupingBy(DataStatisticsResultMiddle:: getDatas, Collectors.groupingBy(DataStatisticsResultMiddle:: getCarrierid, Collectors.summarizingLong(DataStatisticsResultMiddle :: getEnusers)))); Map<String, LongSummaryStatistics> map = enusersCollect2.get("2019"); for(Map.Entry<String, LongSummaryStatistics> entry : map.entrySet()){ System.out.println(entry.getKey()); System.out.println(entry.getValue().getSum()); } }} |
输出结果如下:

3、List的某个字段为String,对其求和:
防止精度丢失:用BigDecimal
//字段为String类型,数字带小数,防止精度丢失:用BigDecimal String aaa = list.stream().map(i -> new BigDecimal(i.getCurrentIncome())).reduce(BigDecimal.ZERO, BigDecimal::add).toString(); System.out.println("aaa:"+ aaa); //会精度丢失 String bbb = String.valueOf(list.stream().mapToDouble(i -> Double.parseDouble(i.getCurrentIncome())).sum()); System.out.println("bbb:"+ bbb);
分类:
Java

 posted on
posted on

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了