spark学习day2
数据处理就是这样一个特别有挑战性的任务,单台机器没有足够强大的计算能力和计算资源来执行处理这些大量的数据(或者用户没有足够耐心等待计算结束)。
一个集群或一组计算机将许多机器的资源集中在一起,使我们能够
但是如果一群机器没有协调机制,那么这些机器并不能产生强大的计算能力,你需要一个软件框架来协调他们之间的工作。Spark 就是这样一种软件框架,它管理和协调跨多台计算机的计算任务。
用来执行计算任务的若干台机器由像 Spark 的集群管理器、YARN 或Mesos 这样的集群管理器进行管理,然后我们提交 Spark 应用程序给这些集群管理器,它们将计算资源分配给应用程序,以便我们完成我们的工作
以下是关于 Spark 应用程序需要了解的几点:
-
Spark 使用一个集群管理器来跟踪可用的资源。
-
驱动器进程负责执行驱动器的命令来完成给定的任务
打开spark终端或者python终端
运行./bin/spark-shell 打开Scala 控制台来启动一个交互式会话,
你也可以使用./bin/pyspark 启动 Python控制台
scala> val myRange = spark.range(1000).toDF("number")
myRange: org.apache.spark.sql.DataFrame = [number: bigint]
这样显示就是运行成功了。
scala的知识点:range,是""不是''(''报错)
python代码:
myRange = spark.range(1000).toDF("number")
我们创建了一个 DataFrame,其中一列包含 1000行,值为 0 到 999。这些数字即是一个分布式集合,在集群上运行此命令时,这个集合的每一部分都会被分配到不同的执行器上。这个集合就是一个 Spark DataFrame。
显示:
scala> myRange.show
+------+
|number|
+------+
| 0|
| 1|
| 2|
| 3|
| 4|
| 5|
| 6|
| 7|
| 8|
| 9|
| 10|
| 11|
| 12|
| 13|
| 14|
| 15|
| 16|
| 17|
| 18|
| 19|
+------+
only showing top 20 rows
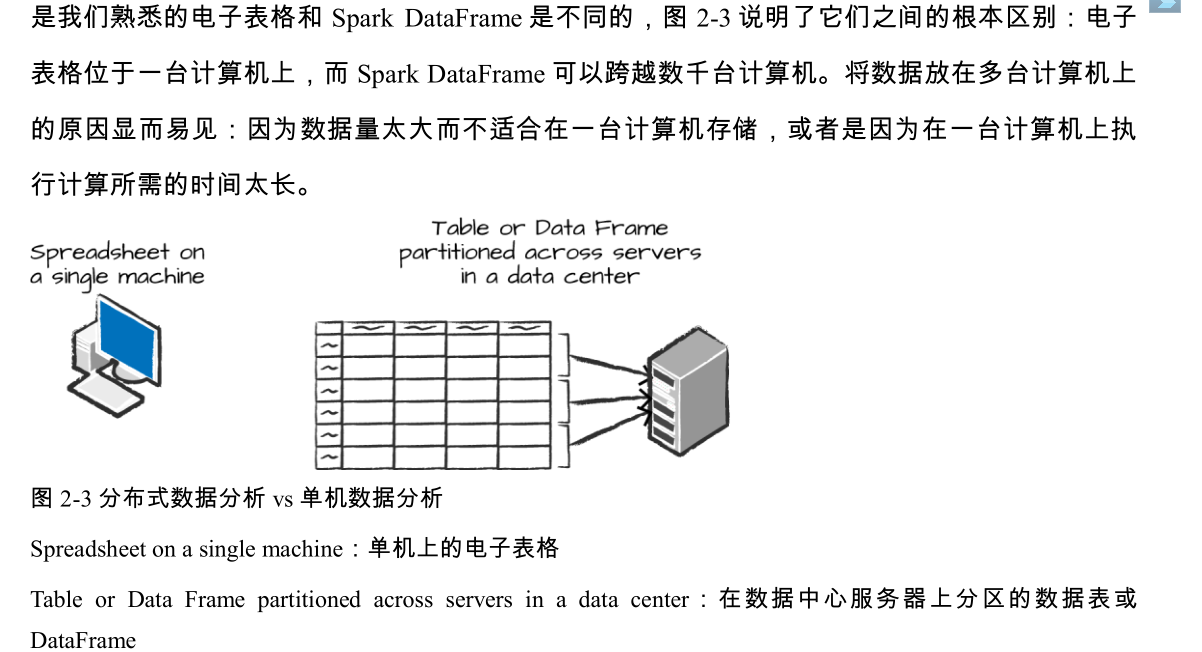
DataFrame和电子表格和 pandas DataFrame的区别
DataFrame 是最常见的结构化 API,简单来说它是包含行和列的数据表。说明这些列和列类型的一些规则被称为模式(schema)。你可以将 DataFrame 想象为具有多个命名列的电子表格。
spark的厉害之处。👆
由于 Spark 具有适用于 Python 和 R 的语言接口,因此可以非常容易地将 Pandas(Python)DataFrame 转换为 Spark DataFrame
几个核心抽象
Spark 有几个核心抽象:Dataset,DataFrame,SQL 表和弹性分布式数据集(RDD)
数据分析
为了让多个执行器并行地工作,Spark 将数据分解成多个数据块,每个数据块叫做一个分区。 分区是位于集群中的一台物理机上的多行数据的集合,DataFrame 的分区也说明了在执行过程中,数据在集群中的物理分布。
值得注意的是,当使用 DataFrame 时,(大部分时候)你不需要人工手动操作分区,你只需指定数据的高级转换操作,然后 Spark 决定此工作将如何在集群上执行(厉害啊)。较低级别的 API(通过RDD 接口)也是存在的,我们将在第三部分详细介绍。
转换操作
Spark 的核心数据结构在计算过程中是 保持不变 的,这意味着它们在创建之后无法更改。这听起来很奇怪:如果不能改变它,应该如何使用它呢?
要“更改”DataFrame,你需要告诉 Spark 如何修改它以执行你想要的操作,这个过程被称为转换(transformation)。下面执行一个简单的 转换来查找当前 DataFrame 中的所有偶数:
我输代码的时候,m然后tab,之后,这样了。

可以查看函数。(补充)
// in Scala
val divisBy2 = myRange.where("number % 2 = 0")
# in Python
divisBy2 = myRange.where("number % 2 = 0")
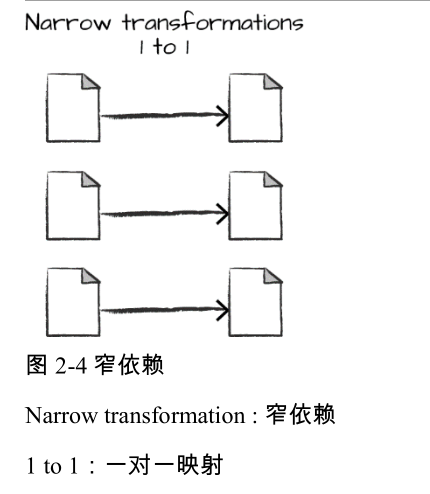
注意这些转换并没有实际输出,这是因为我们仅指定了一个抽象转换。在我们调用一个动作操作(我们将在后面详细介绍动作)之前,Spark 不会真的执行转换操作。转换操作是使用 Spark表达业务逻辑的核心,有两类转换操作:第一类是那些指定 窄依赖 关系的转换操作,第二类是那些指定 宽依赖 关系的转换操作。
具有窄依赖关系(narrow dependency)的转换操作(我们称之为窄转换)是每个输入分区仅决定一个输出分区的转换。
在前面的代码片段中,where 语句指定了一个窄依赖关系,其中一个 分区最多只会对一个输出分区有影响,如图 2-4 所示。
具有宽依赖关系(wide dependency)的转换(或宽转换)是每个输入分区决定了多个输出分区。这种宽依赖关系的转换经常被叫做 洗牌 (shuffle)操作,它会在整个集群中执行互相交换分区数据的功能。 如果是窄转换,Spark 将自动执行 流水线处理 (pipelining),这意味着如果我们在 DataFrame 上指定了多个过滤操作,它们将全部在内存中执行。而属于宽转换的 shuffle操作不是这样,当我们执行shuffle 操作时,Spark 将结果写入磁盘。图 2-5 中说明了宽转换操 作
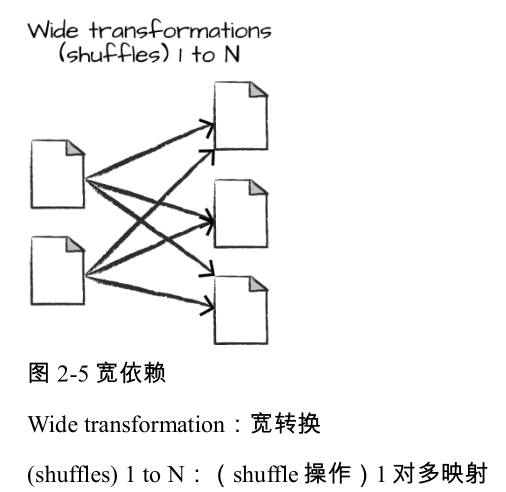
你可能会看到很多关于优化 shuffle 操作的讨论,因为它非常重要。但现在你只需要了解有这两种转换形式,而它们两者的简单的区别在于执行不同的数据操作方式?,这引出了下面这个称为 惰性评估的主题。
惰性评估
惰性评估(lazy evaluation)的意思就是等到绝对需要时才执行计算。在 Spark 中,当用户表达一些对数据的操作时,不是立即修改数据,而是建立一个作用到原始数据的转换计划。Spark会首先将这个计划编译为可以在集群中高效运行的流水线式的物理执行计划,然后等待,直到最后时刻才开始执行代码。这会带来很多好处,因为 Spark 可以优化整个从输入端到输出端的数据流。一个很好的例子就是 DataFrame 的 谓词下推( predicate pushdown ) ,假设我们构建一个含有多个转换操作的 Spark 作业,并在最后指定了一个过滤操作,假设这个过滤操作只需要数据源(输入数据)中的某一行数据,则最有效的方法就是在最开始就仅访问我们需要的这单个记录,Spark 会通过自动下推这个过滤操作来优化整个物理执行计划。(一句话,直接执行需要的操作)
动作操作
转换操作使我们能够建立逻辑转换计划。为了触发计算,我们需要运行一个 动作 操作 (action)。一个动作指示 Spark 在一系列转换操作后计算一个结果。最简单的动作操作是count,它计算一个 DataFrame 中的记录总数:
scala>divisBy2.count()
res3: Long = 500
上面代码的输出应该是 500。当然,count 并不是唯一的动作,有三类动作: 在控制台中查看数据的动作 在某个语言中将数据汇集为原生对象(native object)的动作 写入输出数据源的动作
下面介绍一个指定动作操作的例子,我们启动一个 Spark 作业,首先执行过滤转换(一个窄转换),然后执行一个聚合操作(一个宽转换),再在每个分区上执行计数 count 操作,然后通过 collect 操作将所有分区的结果汇集到一起,生成某个语言的一个原生对象。你可以通过Spark UI 来看到所有这些操作,Spark UI 是一个包含在 Spark 软件包中的工具,你可以使用它监视 Spark 集群上运行的 Spark 作业。
Spark用户接口
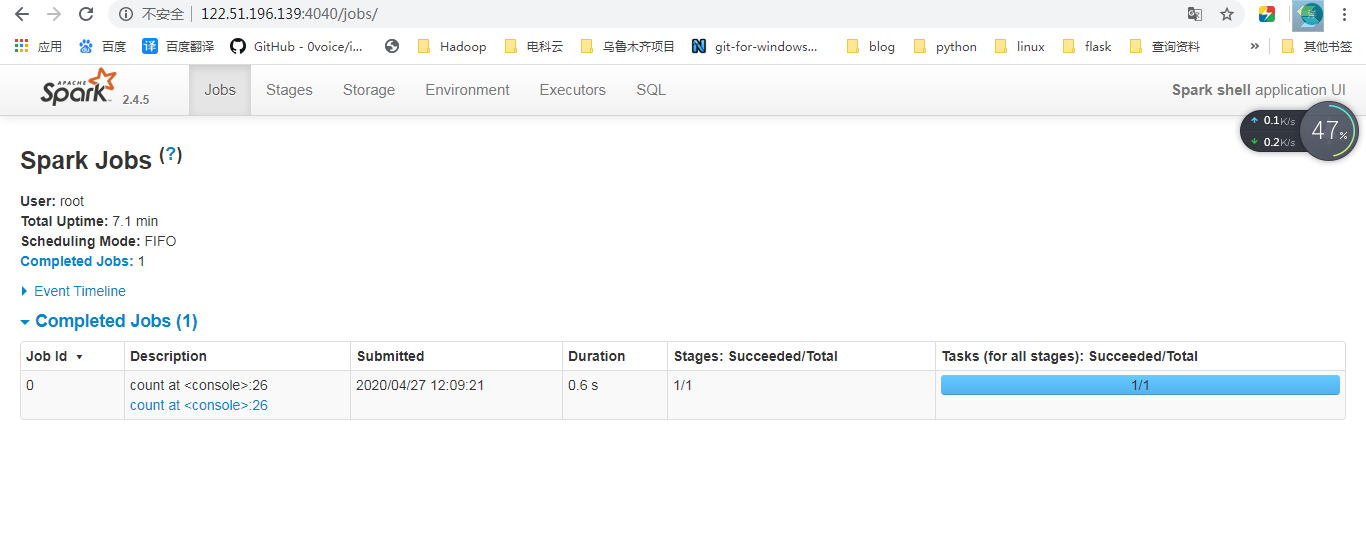
你可以通过 Spark 的 Web UI 监控一个作业的进度,Spark UI 占用驱动器节点的 4040 端口。如果你在本地模式下运行,你可以通过 http://localhost:4040 访问 Spark Web UI。Spark UI 上显示了Spark 作业的运行状态、执行环境和群集状态等信息,这些信息非常有用,可用于性能调优和代码调试。图 2-6 展示了一个 Spark 作业状态的 UI 示例,其中显示了 Spark 作业包含了两个运行阶段的九个任务执行情况。
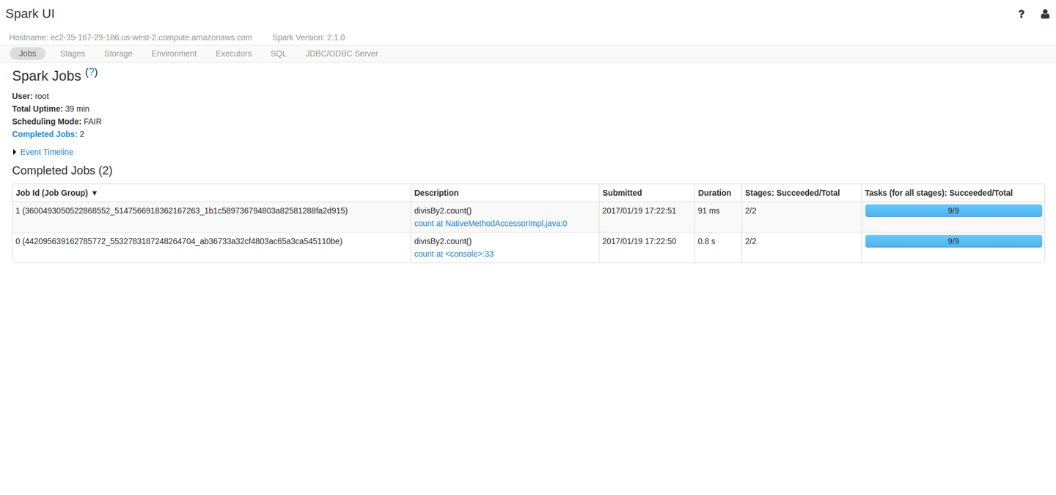
图 2-6 Spark UI 示例 本章不会详细介绍 Spark 作业执行和 Spark UI,而将在第 18 章介绍。你在这里只需知道,一个Spark 作业包含一系列转换操作并由一个动作操作触发,并可以通过 Spark UI 监视该作业。
我的页面。
一个完整的页面
在前面的例子中,我们创建了一个包含某数字范围的 DataFrame,其实处理的并不是典型的大数据。在本节中,我们将通过一个更实际的例子来来强化先前所学的内容,并解释每一步的操作要点。我们将使用 Spark 分析美国交通局统计的一些航班数据。
在 CSV 文件夹内有许多文件,当然也有一些包含其他文件格式的文件夹,我们将在第 9 章讨论,现在我们首先来关注 CSV 文件。
CSV 是一种半结构化的数据格式,每个 CSV 文件包含许多行,每一行对应着以后我们建立的DataFrame 中的一行: $ head /opt/Spark-The-Definitive-Guide-master/data/flight-data/csv/2015-summary.csv(cat head默认看前几行,竟然可以看csv linux太帅了) DEST_COUNTRY_NAME,ORIGIN_COUNTRY_NAME,count United States,Romania,15 United States,Croatia,1 United States,Ireland,344
Spark 可以从大量数据源读取数据或写入数据,为了读取这些数据,需要用到与我们创建的 SparkSession 所关联的 DataFrameReader,还需要指定文件格式及设置其他选项。在这个例子中,我们将要执行一种被称作 模式推理 (schema inference)的操作,即让 Spark 猜测 DataFrame的模式,我们还将指定文件的第一行是文件头,这些也可以通过设置选项来指定。
为了获取模式信息,Spark 会从文件中读取一些数据,然后根据 Spark 支持的类型尝试解析读取到的这些行中的数据类型。当然你也可以在你读取数据时选择严格指定模式(我们建议在实际生产应用中严格指定模式):
// in Scala //这样是一句话
val flightData2015 = spark.read.option("inferSchema", "true").option("header", "true").csv("/opt/Spark-The-Definitive-Guide-master/data/flight-data/csv/2015-summary.csv")
// in Scala //这样好看点,但是无法执行,要写成上面那种格式,或者和py有\换行
val flightData2015 = spark
.read
.option("inferSchema", "true")
.option("header", "true")
.csv("/opt/Spark-The-Definitive-Guide-master/data/flight-data/csv/2015-summary.csv")
# in Python
flightData2015 = spark\
.read\
.option("inferSchema", "true")\
.option("header", "true")\
.csv("/opt/Spark-The-Definitive-Guide-master/data/flight-data/csv\
/2015-summary.csv")
scala

pyspark
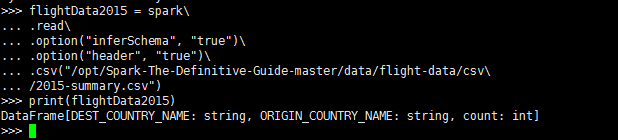
这些(在 Scala 和 Python 中的)每个 DataFrame 都有一些列,但是行数没有指定。行数未指定的原因是因为读取数据是一种转换操作,所以也是一种惰性操作。Spark 只偷看了几行数据后,试图猜测每列应该是什么类型。图 2-7 展示了 CSV 文件被读到一个 DataFrame 里后,又被转换为一个本地数组或行列表的过程。
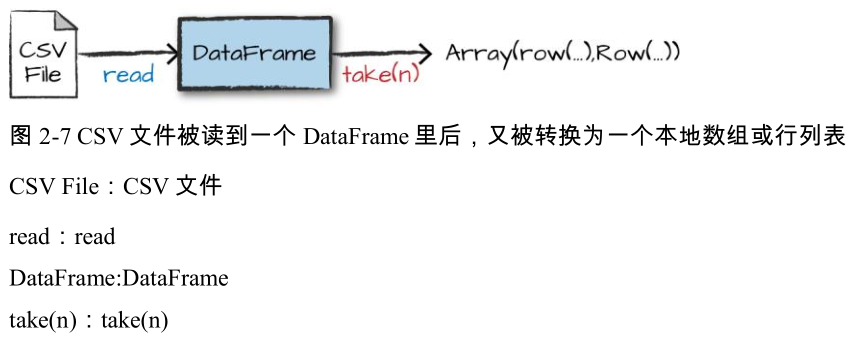
如果我们在 DataFrame 上执行 take 操作,我们将看到下面的结果: flightData2015.take(3) Array([United States,Romania,15], [United States,Croatia...
 我们还可以指定更多的转换!让我们根据 count 列的值(这是一个整数类型)排序,图 2-8 展示了这个过程。
我们还可以指定更多的转换!让我们根据 count 列的值(这是一个整数类型)排序,图 2-8 展示了这个过程。
请注意,sort 操作不会修改 DataFrame,因为 sort 是一个转换,它通过转换以前的 DataFrame 来返回新的 DataFrame。我们来看看当在结果 DataFrame 上执行 take 操作 时发生了什么(图 2-8)。
explain函数
当我们调用 sort 时,什么也不会发生,因为这只是一个转换操作。但是可以通过调用 explain 函数观察到 Spark 正在创建一个执行计划,并且可以看到这个计划将会怎样在集群上执行,调用某个 DataFrame 的 explain 操作会显示 DataFrame 的血统(lineage,即 Spark 是如何执行查询操作的):
scala> flightData2015.sort("count").explain()
== Physical Plan ==
*(2) Sort [count#12 ASC NULLS FIRST], true, 0
+- Exchange rangepartitioning(count#12 ASC NULLS FIRST, 200)
+- *(1) FileScan csv [DEST_COUNTRY_NAME#10,ORIGIN_COUNTRY_NAME#11,count#12] Batched: false, Format: CSV, Location: InMemoryFileIndex[file:/opt/Spark-The-Definitive-Guide-master/data/flight-data/csv/2015-summary.csv], PartitionFilters: [], PushedFilters: [], ReadSchema: struct<DEST_COUNTRY_NAME:string,ORIGIN_COUNTRY_NAME:string,count:int>
恭喜,你刚刚阅读了你的第一个解释计划!解释计划有点神秘,但通过一些实践你就会熟悉 它。你可以以从上到下的方式阅读解释计划,上面是最终结果,下面是数据源。在这种情况下,如果查看每行的第一个关键字,你将看到排序、交换和 FileScan。这是因为排序其实是是一个宽转换,行需要相互比较和交换。不必过分担心如何理解关于解释计划的所有内容,使用 Spark 时,解释计划可以作为调试和帮助理解的的有效工具。
现在,我们需要指定一个动作来触发这个计划的执行。在做之前,我们首先完成一个配置。默认情况下,shuffle 操作会输出 200 个 shuffle 分区,我们将此值设置为 5 以减少 shuffle 输出分区的数量:
scala> spark.conf.set("spark.sql.shuffle.partitions", "5")
scala> flightData2015.sort("count").take(2)
res10: Array[org.apache.spark.sql.Row] = Array([United States,Singapore,1], [Moldova,United States,1])
图 2-9 说明了这一操作。请注意,除了逻辑转换外,这里还给出了物理分区的数量。
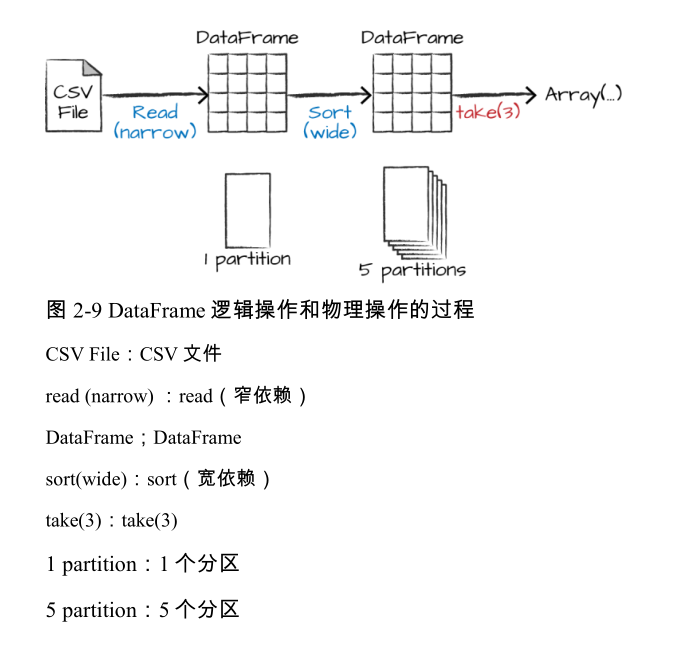
我们构建的转换逻辑计划定义了 DataFrame 的血统,这样在任何给定的时间点,Spark 知道如何通过对输入数据执行之前的操作来重新计算任何分区,这就是 Spark 编程模型的核心——函数式编程,当数据转换保持不变时,相同的输入始终导致相同的输出。我们不能操纵物理数据,但是我们可以配置参数来指定物理执行的特性.比如我们刚刚设置的 shuffle 分区参数,程序最终输出了 5 个分区,因为我们指定了 shuffle 分区参数为 5。你可以更改此设置以改变 Spark 作业的物理执行特性,尝试使用不同的值,并自己查看分区的数量,你将会看到不同设置下会需要不同的时间。别忘了,你可以通过在 4040 端口上的 Spark UI 来监控作业进度,并查看作业的物理和逻辑执行的情况。

DataFrame和 SQL
在前面的例子中介绍了一个简单的转换工作,现在让我们通过一个更复杂的转换,继续介绍如何使用 DataFrame 和 SQL。不管使用什么语言,Spark 以完全相同的方式执行转换操作,你可以使用 SQL或 DataFrame(基于 R,Python,Scala 或 Java 语言)表达业务逻辑,并且在实际执行代码之前,Spark 会将该逻辑编译到底层执行计划(可以在解释计划中看到)。使用 SparkSQL,你可以将任何 DataFrame 注册为数据表或视图(临时表),并使用纯 SQL 对它进行查询。编写 SQL 查询或编写 DataFrame 代码并不会造成性能差异,它们都会被“编译”成相同的底层执行计划。
你可以使用一个简单的方法将任何 DataFrame 放入数据表或视图中:
flightData2015.createOrReplaceTempView("flight_data_2015")
现在我们可以在 SQL 中查询数据,我们将使用 spark.sql 函数(别忘了 spark 是我们的 SparkSession 变量),它可方便地返回新的 DataFrame。尽管这在逻辑上会有种绕圈的感觉,即对 DataFrame 的 SQL 查询返回另一个 DataFrame,但它实际上非常有用。这使得你可以在任何给定的时间点以最方便的方式指定转换操作,而不会牺牲效率!为了理解这种情况,我们来看看下面两个解释计划:
// in Scala
val sqlWay = spark.sql("""
SELECT DEST_COUNTRY_NAME, count(1)
FROM flight_data_2015
GROUP BY DEST_COUNTRY_NAME
""")
val dataFrameWay = flightData2015
.groupBy('DEST_COUNTRY_NAME)
.count()
sqlWay.explain
dataFrameWay.explain
# in Python
sqlWay = spark.sql("""
SELECT DEST_COUNTRY_NAME, count(1)
FROM flight_data_2015
GROUP BY DEST_COUNTRY_NAME
""")
dataFrameWay = flightData2015\
.groupBy("DEST_COUNTRY_NAME")\
.count()
sqlWay.explain()
dataFrameWay.explain()
scala> sqlWay.explain
== Physical Plan ==
*(2) HashAggregate(keys=[DEST_COUNTRY_NAME#10], functions=[count(1)])
+- Exchange hashpartitioning(DEST_COUNTRY_NAME#10, 50)
+- *(1) HashAggregate(keys=[DEST_COUNTRY_NAME#10], functions=[partial_count(1)])
+- *(1) FileScan csv [DEST_COUNTRY_NAME#10] Batched: false, Format: CSV, Location: InMemoryFileIndex[file:/opt/Spark-The-Definitive-Guide-master/data/flight-data/csv/2015-summary.csv], PartitionFilters: [], PushedFilters: [], ReadSchema: struct<DEST_COUNTRY_NAME:string>
scala> dataFrameWay.explain
== Physical Plan ==
*(1) FileScan csv [DEST_COUNTRY_NAME#10,ORIGIN_COUNTRY_NAME#11,count#12] Batched: false, Format: CSV, Location: InMemoryFileIndex[file:/opt/Spark-The-Definitive-Guide-master/data/flight-data/csv/2015-summary.csv], PartitionFilters: [], PushedFilters: [], ReadSchema: struct<DEST_COUNTRY_NAME:string,ORIGIN_COUNTRY_NAME:string,count:int>
注意:执行的时候突然ctrl+c.推出了。然后之前的变量都没了。。。(有什么好办法?)
请注意,这些计划编译后是完全相同的物理执行计划! 让我们从数据中提取一些有趣的统计结果。有一点要声明的是,Spark 中的 DataFrame(和 SQL)已经有了大量的可用操作,有数百种函数可供你使用和导入,以帮助你更快地解决大数据问题。我们将使用 max 函数来统计往返任何特定位置的航班最大数量,这要扫描 DataFrame中相关列中的每个值,并检查它是否大于先前看到的值。这是一个转换,因为我们不断过滤最后仅得到一行。下面我们来看看如何编写 Spark 程序:
spark.sql("SELECT max(count) from flight_data_2015").take(1)
// in Scala
import org.apache.spark.sql.functions.max
flightData2015.select(max("count")).take(1)
# in Python
from pyspark.sql.functions import max
flightData2015.select(max("count")).take(1)
scala> spark.sql("SELECT max(count) from flight_data_2015").take(1)
res15: Array[org.apache.spark.sql.Row] = Array([370002])
scala> import org.apache.spark.sql.functions.max
import org.apache.spark.sql.functions.max
scala> flightData2015.select(max("count")).take(1)
res16: Array[org.apache.spark.sql.Row] = Array([370002])
这是一个简单的例子,结果为 370,002。我们来执行一些更复杂的操作,在数据中找到前五个目标国家,这是我们的第一个多转换查询,所以我们将一步一步地介绍。让我们从一个相当简单的 SQL 聚合开始:
// in Scala
val maxSql = spark.sql("""
SELECT DEST_COUNTRY_NAME, sum(count) as destination_total
FROM flight_data_2015
GROUP BY DEST_COUNTRY_NAME
ORDER BY sum(count) DESC
LIMIT 5
""")
maxSql.show()
# in Python
maxSql = spark.sql("""
SELECT DEST_COUNTRY_NAME, sum(count) as destination_total
FROM flight_data_2015
GROUP BY DEST_COUNTRY_NAME
ORDER BY sum(count) DESC
LIMIT 5
""")
maxSql.show()
+-----------------+-----------------+ |DEST_COUNTRY_NAME|destination_total| +-----------------+-----------------+ | United States| 411352| | Canada| 8399| | Mexico| 7140| | United Kingdom| 2025| | Japan| 1548| +-----------------+-----------------+
现在让我们看看 DataFrame 语法上,它的语义和 SQL 相似但实现略有不同。但是,正如我们所提到的,两者的物理执行计划是相同的。接下来,让我们运行查询并观察现象。
// in Scala
import org.apache.spark.sql.functions.desc
flightData2015
.groupBy("DEST_COUNTRY_NAME")
.sum("count")
.withColumnRenamed("sum(count)", "destination_total")
.sort(desc("destination_total"))
.limit(5)
.show()
//
flightData2015.groupBy("DEST_COUNTRY_NAME").sum("count").withColumnRenamed("sum(count)", "destination_total").sort(desc("destination_total")).limit(5).show()
//
# in Python
from pyspark.sql.functions import desc
flightData2015\
.groupBy("DEST_COUNTRY_NAME")\
.sum("count")\
.withColumnRenamed("sum(count)", "destination_total")\
.sort(desc("destination_total"))\
.limit(5)\
.show()
+-----------------+-----------------+ |DEST_COUNTRY_NAME|destination_total| +-----------------+-----------------+ | United States| 411352| | Canada| 8399| | Mexico| 7140| | United Kingdom| 2025| | Japan| 1548| +-----------------+-----------------+
从输入数据开始我们需要七个步骤,这可以在DataFrame的解释计划中看到这一点。图2-10显示我们在“代码”中执行的一系列步骤。由于Spark会针对物理执行计划做一系列优化,所以真正的执行计划(调用explain函数返回的执行计划)将不同于图2-10所示的执行计划。这个执行计划是一个有向无环图(DAG)的转换,每个转换产生一个新的不可变的DataFrame,我们可以在这个DataFrame上调用一个动作来产生一个结果。?
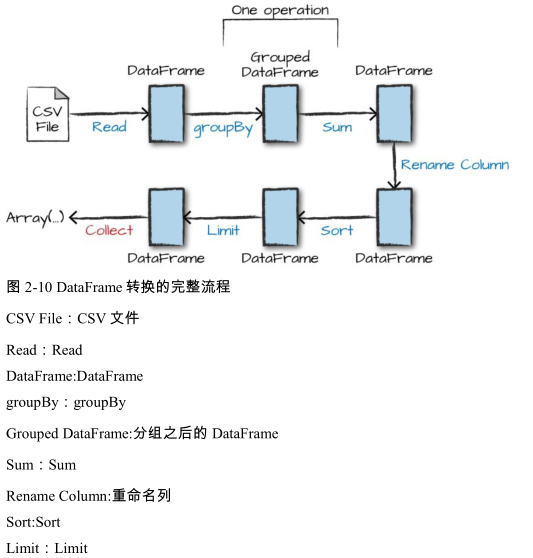

第一步是读取数据。我们之前定义了 DataFrame,但是 Spark 实际上并没有真正读取它,直到在DataFrame 上调用动作操作后才会真正读取它。(懒) 第二步是分组。当我们调用 groupBy 时,我们最终得到了一个 RelationalGroupedDataset 对象,它是一个 DataFrame 对象,它具有指定的分组,但需要用户指定聚合操作然后才能进一步查询。我们按键(或键集合)分组,然后再对每个键对应分组进行聚合操作。 第三步是指定聚合操作。我们使用 sum 聚合操作,这需要输入一个列表达式,或者简单的一个列名称。sum 方法调用的结果是产生一个新的 DataFrame,它有一个新的表结构,它也知道每个列的类型。再次强调,到这里还是没有执行计算,这只是我们表达的另一种转换操作,而Spark 能够通过这些转换操作跟踪我们的类型信息。 第四步是简单的重命名。我们使用带有两个参数的 withColumnRenamed 方法,即原始列名称和新列名称。当然,这还不会执行计算,这也只是一种转换! 第五步对数据进行排序。如果我们要所有行按照 destination_total 列的大小排序,获得该DataFrame 中 destination_total 值较大的一些行作为结果你可能注意到我们必须导入一个函数来执行此操作,即 desc 函数。你可能也注意到,desc 函数不是返回一个字符串,而是一个 Column。通常来说,许多 DataFrame 方法将接受字符串(作为列名称)、Column 类型、或表达式,列和表达式实际上是完全相同的东西。 倒数第二步,我们指定了一个限制。这只是说明我们只想返回最终 DataFrame 中的前五个值而不是所有数据。 最后一步是我们要执行的动作!现在我们才实际上开始收集DataFrame的结果,Spark将返回一个我们所使用语言的数组或列表。为了更好的理解这些,我们来看看前面查询的解释计划:
// in Scala
flightData2015
.groupBy("DEST_COUNTRY_NAME")
.sum("count")
.withColumnRenamed("sum(count)", "destination_total")
.sort(desc("destination_total"))
.limit(5)
.explain()
//
flightData2015.groupBy("DEST_COUNTRY_NAME").sum("count").withColumnRenamed("sum(count)", "destination_total").sort(desc("destination_total")).limit(5).explain()
# in Python
flightData2015\
.groupBy("DEST_COUNTRY_NAME")\
.sum("count")\
.withColumnRenamed("sum(count)", "destination_total")\
.sort(desc("destination_total"))\
.limit(5)\
.explain()
== Physical Plan ==
TakeOrderedAndProject(limit=5, orderBy=[destination_total#114L DESC NULLS LAST], output=[DEST_COUNTRY_NAME#10,destination_total#114L])
+- *(2) HashAggregate(keys=[DEST_COUNTRY_NAME#10], functions=[sum(cast(count#12 as bigint))])
+- Exchange hashpartitioning(DEST_COUNTRY_NAME#10, 5)
+- *(1) HashAggregate(keys=[DEST_COUNTRY_NAME#10], functions=[partial_sum(cast(count#12 as bigint))])
+- *(1) FileScan csv [DEST_COUNTRY_NAME#10,count#12] Batched: false, Format: CSV, Location: InMemoryFileIndex[file:/opt/Spark-The-Definitive-Guide-master/data/flight-data/csv/2015-summary.csv], PartitionFilters: [], PushedFilters: [], ReadSchema: struct<DEST_COUNTRY_NAME:string,count:int>
虽然这个解释计划与我们确切的“概念计划”不符,但所有步骤都在那里,你可以看到 limit 语句以及 orderBy(在第一行),你也可以看到我们的聚合操作是如何在 partial_sum 调用中的两个阶段发生的,这是因为数字的 sum 操作是可交换的,并且 Spark 可以在每个分区单独执行 sum操作。当然,我们也可以看到我们如何在 DataFrame 中读取数据。
当然,我们并不总是需要收集数据。我们也可以将它写出到 Spark 支持的任何数据源。例如,假设我们想要将信息存储在像 PostgreSQL 这样的数据库中,或者将它们写入到另一个文件。
总结
本章介绍了 Apache Spark 的基础知识。我们讨论了转换和动作,以及 Spark 如何惰性执行转换操作的 DAG 图以优化 DataFrame 上的物理执行计划。我们还讨论了如何将数据组织到分区中,并为处理更复杂的转换设定多个阶段。在第三章中我们将介绍庞大的 Spark 生态系统,并了解Spark 中 提 供 的 包 括 流 数 据 处 理 和 机 器 学 习

 浙公网安备 33010602011771号
浙公网安备 33010602011771号