spark学习day1安装
设计哲学
统一平台
Spark 通过统一计算引擎和利用一套统一的 API,支持广泛的数据分析任务,从简单的数据加载,到 SQL 查询,再到机器学习和流式计算。
这一目标背后的驱动原因是,真实世界的数据分析任务都结合了许多不同的处理类型和软件库,不论是 Jupyter Notebook
Spark 的统一 API 使得这些任务更易编写且更加高效。首先,Spark 提供了一致的、可组合的 API,你可以使用这些 API 来构建应用程序,或使用代码片段亦或是从现有的库来构建应用程序,它还允许你在上面编写自己的数据分析库。但是,可组合的 API 还不够,利用Spark 的 API,用户还可以组合不同库和函数来优化用户程序,实现高性能。例如,如果你使用 SQL 查询语句来加载数据,然后使用 Spark 的 ML 库评估其上的机器学习模型,则引擎可以将这些步骤合并为一次数据扫描。通用 API 设计和高性能执行的设计,使 Spark 成为开发交互式程序和生产应用程序的强大平台。
Spark 在定义统一平台方面与软件其他领域实现统一平台的思路相同。例如,数据科学家 在进行建模时受益于统一的软件库支持(例如 Python 或 R),Web 开发人员可从统一框架 (如 Node.js 或 Django)中受益。在 Spark 之前,没有任何开源系统试图为并行数据处理提供这种统一引擎,这意味着用户必须拼凑多套 API 和多个系统来开发应用程序。因此,Spark 迅速成为这种发展的标准,随着时间的推移,Spark 不断扩展其内置 API 以涵盖更多应用领域(和python似的?封装了很多内置库,所以方便),同时该项目的开发人员也在不断完善统一引擎。值得一提的是,本书的重点之一将是 Spark 2.0 中定义的“结构化 API”(DataFrame,Dataset 👇和 SQL),以帮助进一步优化用户应用程序。
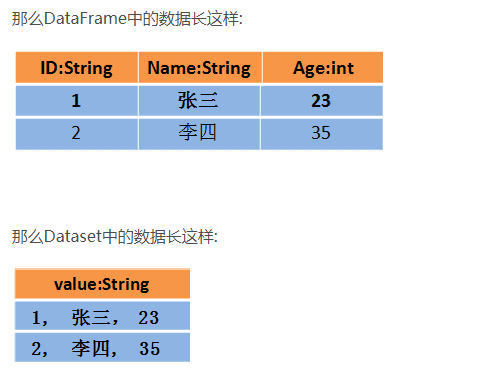
Spark中DataSet的基本使用 https://blog.csdn.net/weixin_42702831/article/details/82492421
计算引擎
在 Spark 致力于统一平台的同时,Spark 也专注于计算引擎,Spark 从存储系统加载数据并对其执行计算,加载结束时不负责永久存储。你可以将多重持久化存储系统与 Spark 结合使用,包括云存储系统(如 Azure 存储和 Amazon S3),分布式文件系统(如 Apache Hadoop),键值存储系统(如 Apache Cassandra)以及消息队列系统(如 Apache Kafka)。但是,Spark 本身既不负责持久化数据,也不是偏向于使用某一特定的存储系 统,主要原因是大多数数据已经存在于混合存储系统中,而移动这些数据的开销非常大, 因此 Spark 专注于对数据执行计算,而不考虑数据存储于何处。Spark 努力使这些存储系统让用户使用起来大致相似,这样应用程序无需担心数据存储对数据处理的影响。
Spark 对计算的关注使其不同于早期的大数据软件平台,例如 Apache Hadoop。 Hadoop 包 括一个存储系统(HDFS,专为使用普通服务器集群进行低成本存储而设计)和计算系统 (MapReduce),它们紧密集成在一起。但是,这种设计导致无法运行独立于 HDFS 的 MapReduce 系统。更重要的是,这种选择也让用户编写访问其他存储的应用程序更加困 难。尽管 Spark 在 Hadoop 存储上运行良好,但现在它也广泛用于除 Hadoop 之外的存储系统,例如公有云(可以单独租赁云存储资源)或流处理应用程序。
配套的软件库
Spark 的最后一个组件是它的软件库,这与 Spark 的设计理念一脉相承,即构建一个统一的引擎,为通用数据分析任务提供统一的 API。Spark 不仅随计算引擎提供标准库,同时也支持一系列由开源社区发布为第三方包的外部库。今天,Spark 的标准库实际上已经成为了一系列开源项目的集成:其实 Spark 核心引擎本身自第一次发布以来几乎没有什么变化,但是配套的软件库已经越来越强大,提供越来越多的功能。Spark 包括 SQL 和处理结构化数据的库(Spark SQL)、机器学习库(MLlib)、流处理库(Spark Streaming 和较新的结构化流式处理)、以及图分析(GraphX)的库。除了这些库之外,还有数百种开源外部库,从用于各种存储系统的连接器到机器学习算法。 spark-packages.org 上提供了一个外部库的索引。
背景:大数据问题
为什么我们迫切需要用于数据分析的新计算引擎和编程模型?与许多计算的新趋势一样,这是由于计算机应用和硬件技术背后的商业形势变化所导致的。在计算机发展的很长一段时间里,计算机每年都会因处理器速度的提高而变得更快:每年新处理器的运行速度可能比上一年更快。因此,在不对其代码进行任何更改的情况下,应用程序每年都会变得更快。这种趋势的持续建立起来了大型应用程序的生态系统,而其中大部分应用程序只被设计为在单个处理器上运行。随着时间的推移,这些应用程序也促使了处理器速度的提高,并要求支持更多的计算量和处理更大的数据量。 不幸的是,这种硬件发展趋势在 2005 年左右停止了:由于硬盘散热的限制,硬件开发人员放弃了制造更快单个处理器的思路,并转向为增加更多的相同计算能力的并行 CPU 计算核心。这种变化意味着需要修改应用程序以支持并行计算,以便更快运行,这促使了 Apache Spark 等新编程模型的出现。 最重要的是,虽然在 2005 年处理器性能的增速减慢了,但是数据存储和数据采集技术的发展并没有减慢。存储 1TB 数据的成本每 14 个月继续下降两次,这意味着对于各种规模的企业来说,存储大量数据的成本非常低廉。此外,许多数据采集技术(传感器、摄像头、公共数据集等)不断发展,成本持续降低或者分辨率持续提高。例如,摄像头技术每年在分辨率和每像素成本方面不断提高,达到 1200 万像素摄像头成本仅为 3 美元至 4 美元的水平;这使得收集大量视频数据的成本非常低廉,不论是来自人们实际生活中的拍摄视频或是来自自动传感器。此外,摄像头本身也是其他数据采集设备(如望远镜和基因测序仪)的关键传感器,这也促使了这些技术的成本下降。 最终的结果是我们的世界发展成了一个采集数据非常便宜的世界,但处理它需要大规模的并行计算,通常是在群集上进行。而且,在这个新的世界里,过去 50 年开发的软件无法自动扩展为并行程序,数据处理领域的传统编程模型也无法被自动的并行化,因此我们需要一种新的编程模型。Apache Spark 就是在这个新形势下应运而生的。
启动 Spark 交互式控制台
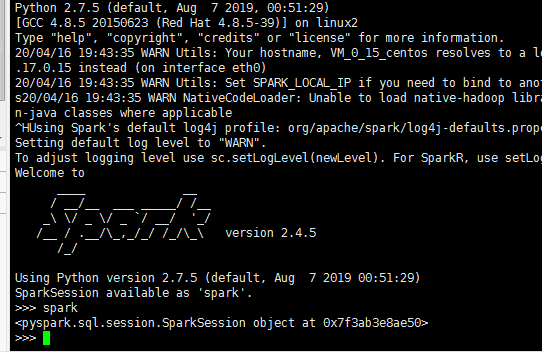
启动 Python控制台
你需要安装 Python 2 或 3 才能启动 Python 控制台。在 Spark 的主目录下运行以下代码:
./bin/pyspark
完成之后,输入“spark”并按 Enter 键,你将看到打印的 SparkSession 对象
error1:启动spark时,提示JAVA_HOME not set
https://blog.csdn.net/a904364908/article/details/81281995
排查后发现,在sbin目录下的spark-config.sh文件下未添加JAVA_HOME的索引.在该文件下添加jdk的路径,再分发到各个节点上就可以了
export JAVA_HOME = /opt/jdk1.8.0_181
export JAVA_HOME=/opt/jdk1.8.0_181
export CLASSPATH=.:$JAVA_HOME/lib
export PATH=$JAVA_HOME/bin:$PATH
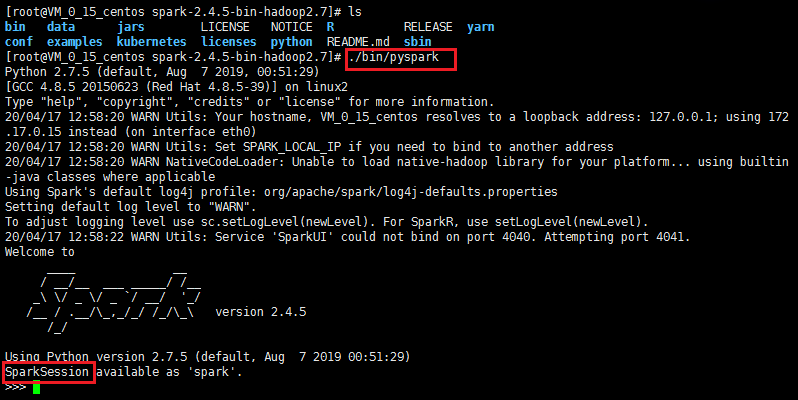
启动 Scala控制台
要启动 Scala 控制台,你需要运行以下命令:
./bin/spark-shell
完成之后,输入“spark”并按 Enter 键,就像在 Python 中一样,你会看到 SparkSession 对象
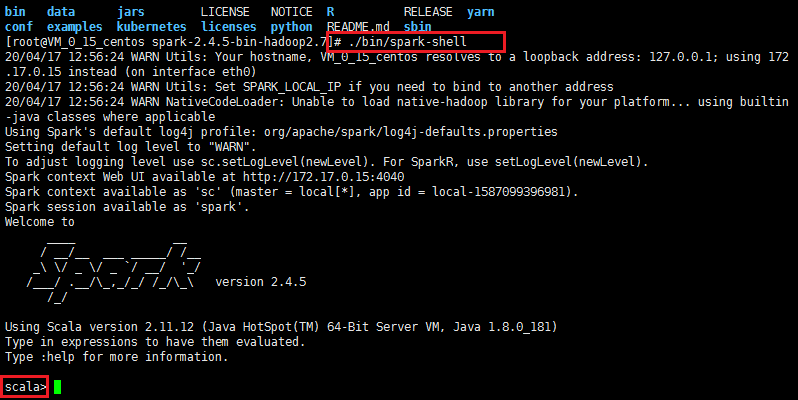
启动 SQL控制台
本书的部分内容将涉及大量的 Spark SQL,你可能想要启动 SQL 控制台,在我们接触这本书中的相关主题之后,我们将介绍更多的细节。
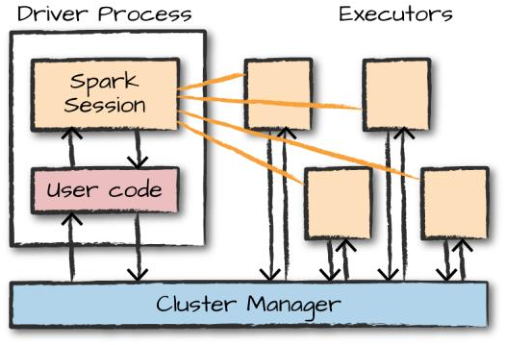
Spark的基本架构
但是如果一群机器没有协调机制,那么这些机器并不能产生强大的计算能力,你需要一个软件框架来协调他们之间的工作。Spark 就是这样一种软件框架,它管理和协调跨多台计算机的计算任务
用来执行计算任务的若干台机器由像 Spark 的集群管理器、YARN 或 Mesos 这样的集群管理器进行管理,然后我们提交 Spark 应用程序给这些集群管理器,它们将计算资源分配给应用程序,以便我们完成我们的工作
YARN:对你的代码来说是一个包管理器, 你可以通过它使用全世界开发者的代码, 或者分享自己的代码。Yarn 做这些快捷、安全、可靠,所以你不用担心什么。
Spark应用程序
由一个 驱动器 进程和一组 执行器 进程组成。
https://yarn.bootcss.com/docs/getting-started/
配置spark需要的java环境(超哥提供)
配置好了,就可以运行了。。。
java -version
vim /etc/profile
export JAVA_HOME=/opt/jdk1.8.0_181
export CLASSPATH=.:$JAVA_HOME/lib
export PATH=$JAVA_HOME/bin:$PATH
source /etc/profile
####

 浙公网安备 33010602011771号
浙公网安备 33010602011771号