

Scrapy详解
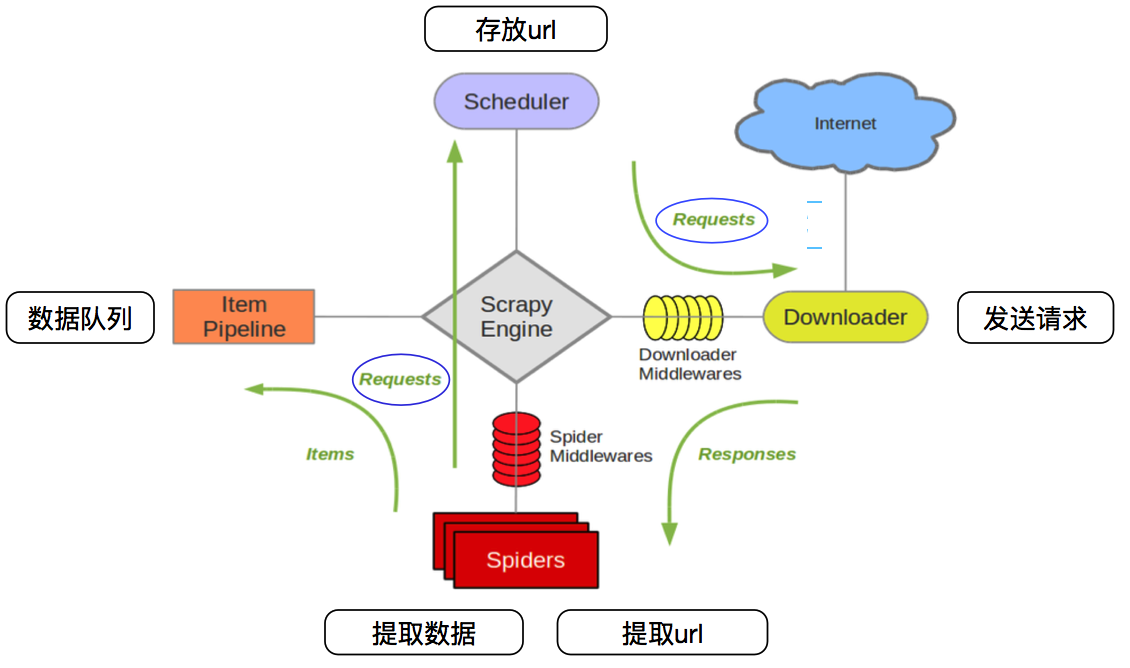
一、爬虫生态框架
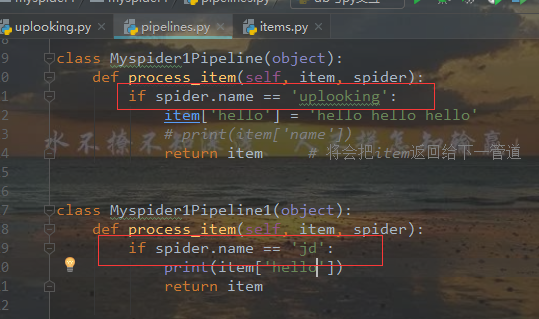
在管道传数据只能传字典和items类型。
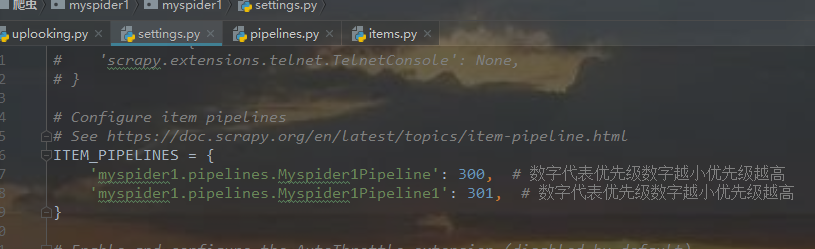

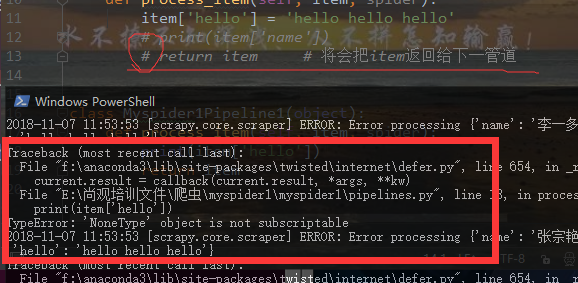
将 上一return语句注释则会报错 如:

如上图,爬虫文件中有一个name属性,如果多个爬虫可以通过这个属性在管道控制分析的是哪个爬虫的数据
日志文件

添加红框里面的一条代码,让打印结果只显示warning级别及以上的警告
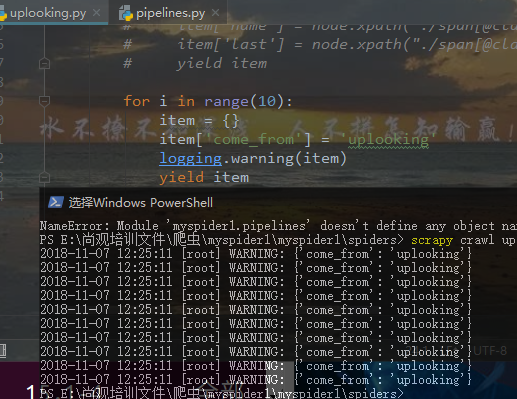
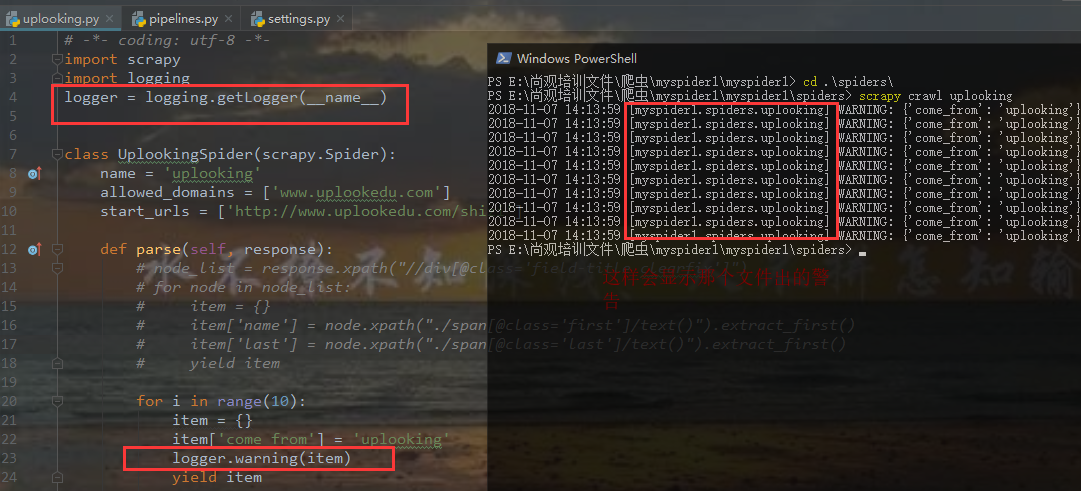
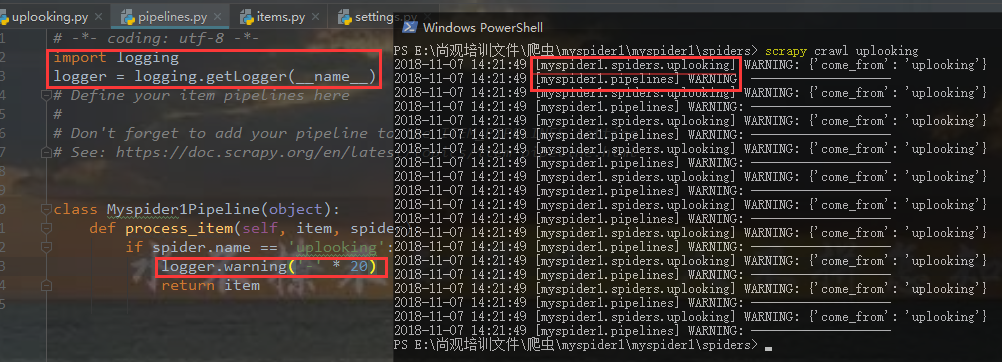
如何保存日志信息
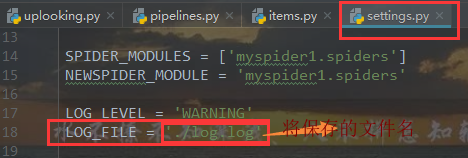
发现运行后没有任何输出

项目中多了log.log日志文件
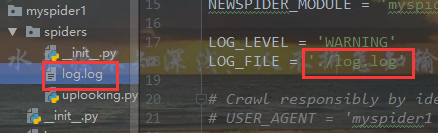
打开log.log日志文件即日志信息

items类型对象
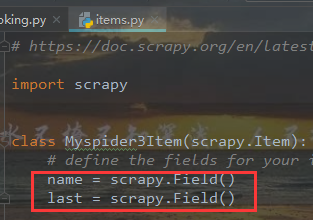
在items文件中声明了name、last的键在爬虫文件中声明即可用

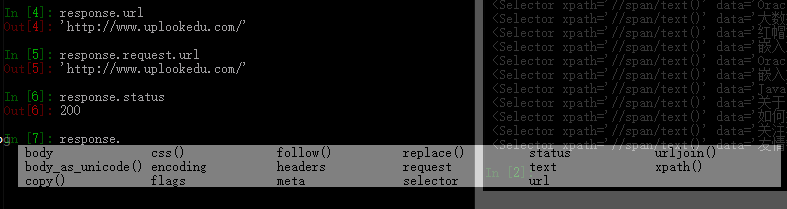
scrapy shell 用法
scrapy shell + 网址 会进入一个ipython可以测试response 如:

模仿浏览器
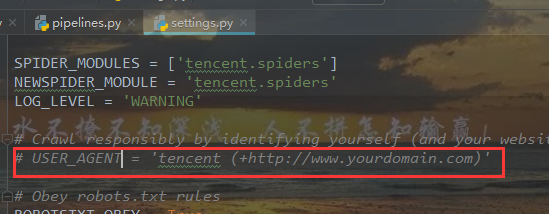
改为自己浏览器的user_agent信息

更改遵守robots规则
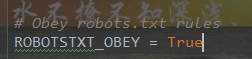
将True改为False
提取下一页url: scrapy.Request(url, callback)用来获取网页里的地址
callback:指定由那个函数去处理
分布式爬虫:
1.多台机器爬到的数据不能重复
2.多台机器爬到的数据不能丢失
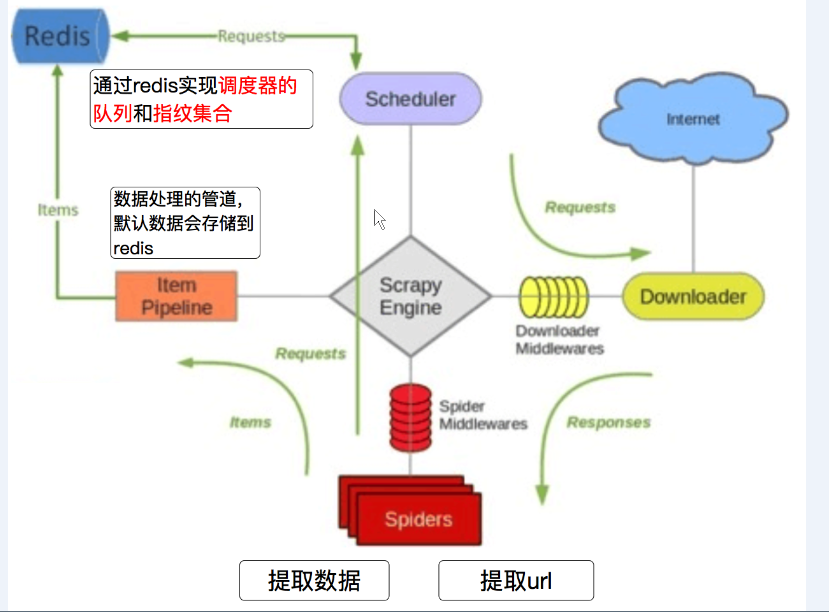
1.redis是什么?
Redis是一个开源的、内存数据库,他可以用作数据库、缓存、消息中间件。它支持多种数据类型的数据结构,如字符串、哈希、列表、集合、有序集合(可能存在数据丢失)
redis安装 Ubuntu: sudo apt-get install redis-server Centos:sudo yum install redis-server
检测redis状态
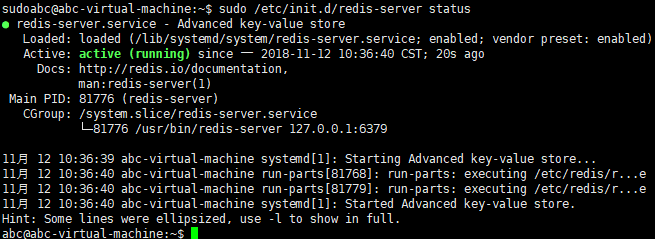
redis服务的开启:sudo /etc/init.d/redis-server start
重启:sudo /etc/init.d/redis-server restart
关闭:sudo /etc/init.d/redis-server stop
redis连接客户端:redis-cli
redis远程连接客户端:redis-cli -h<hostname> -p <port>(默认6379)
redis常用命令:
选择数据库:select 1 (第一个数据库为0 ,默认16个数据库,可修改配置文件修改数据库个数且个数没有上限)

查看数据库里的内容:keys *
向数据库加列表:lpush mylist a b c d (数据可重复)
查看列表数据:lrange mylist 0 -1

查看列表元素个数:llen mylist
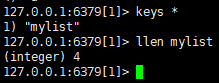
向set中加数据:sadd myset a b c d(不能重复,无序)
查看set中的数据:smembers myset

查看set中的元素个数:scard myset

向有序zset中添加数据:zadd myzset 1 a 2 b 3 c 4 d

查看zset编号和数据:zrange myzset 0 -1 withscores
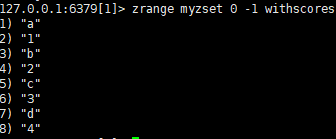
查看zset数据
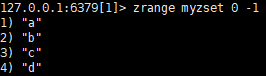
改变编号 如改变a的编号:

统计zset元素的个数zcard myzset

删除当前数据库:flushdb
清楚所有数据库:flushall
安装scrapy-redis
sudo pip install scrapy_redis
下载scrapy-redis例子:git clone https://github.com/rolando/scrapy-redis.git
setting.py中:
# 去重
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# 调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 调度器内容持久化
SCHEDULER_PERSIST = True
ITEM_PIPELINES = {
'example.pipelines.ExamplePipeline': 300,
# 负责把数据存储到redis数据库里
'scrapy_redis.pipelines.RedisPipeline': 400,
}
最后需把redis加上

序列化:把一个类的对象变成字符串最后保存到文件
反序列化:保存到文件的对象是字符串格式 --> 读取字符串 --> 对象
注:后台打印的数据较杂乱,我只想要自己爬到的东西怎么办?
第一步:
setting.py中加 LOG_LEVEL = 'WARNING'
这句代码会将不必要的数据屏蔽,屏蔽的数据如下:
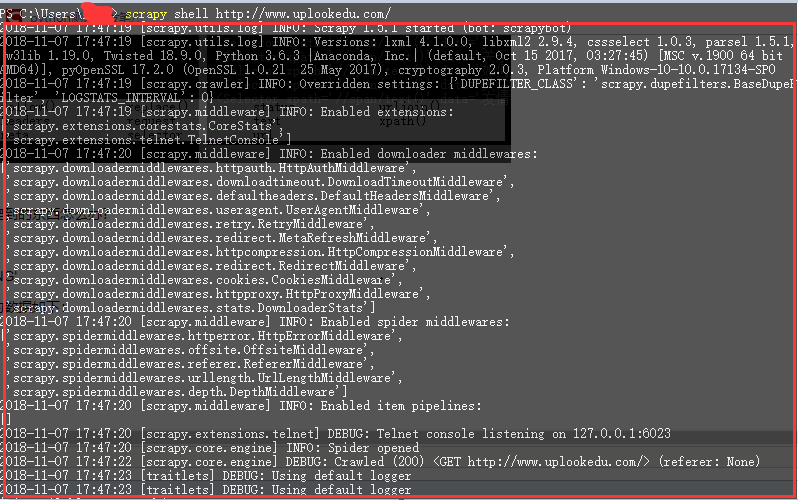
第二步:
然而现在还不是最简洁的,还有杂项。这样做,将response.xpath('*********')变成response.xpath('*********').extract()
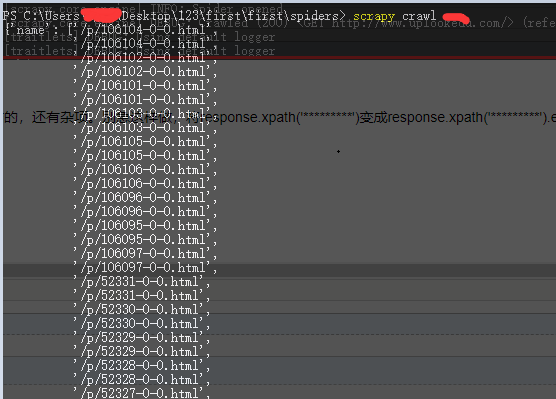
怎么样是不是你想要的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号