爬虫之Scrapy框架
Scrapy安装
windows
windows环境下执行pip3 install scrapy可能会报如下的错误
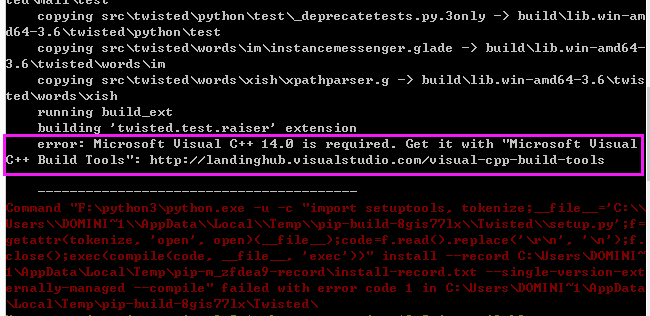
英文好点的小伙伴一眼就看出来,windows想让我们下载Visual C++ 14.0,这个时候就会聪明反被聪明误了,千万不能去下载这个东西,而是需要下载下面的几个东东

让我们的系统能够识别运行scrapy必备的配置
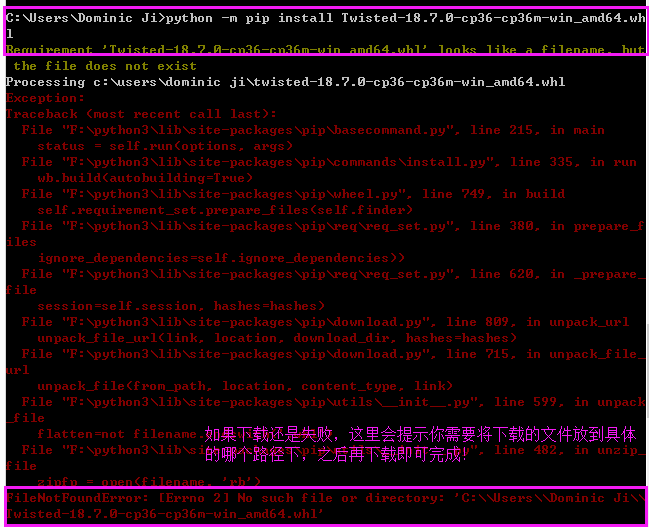
http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted去这个地址下载一个.whl结尾的配置文件(Scrapy依赖Twisted来下载获取到的页面内容,比requests在下载性能方面更高)
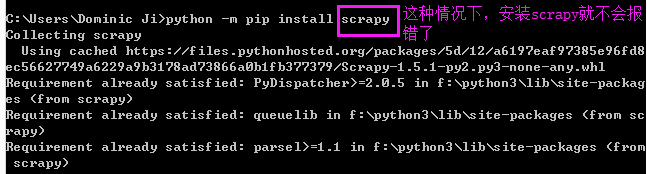
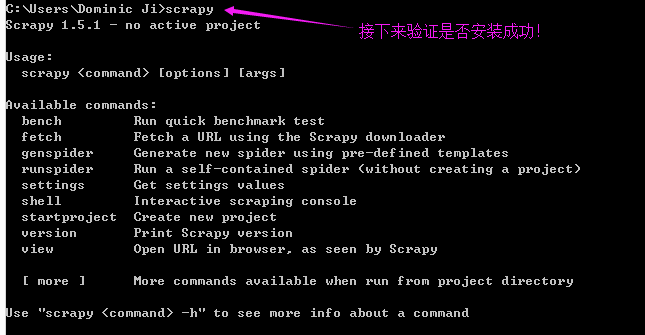
之后再执行

基本使用:
命令行创建Scrapy项目
scrapy startporject Papa
生成项目必备的文件及文件之后,创建我们自己对于的爬取某个对象网页的文件
scrapy genspider chouti chouti.com
我们要爬取抽屉新闻榜,这里命令直接是chouti了后面的chouti.com就是我们这个文件起始爬取的路径
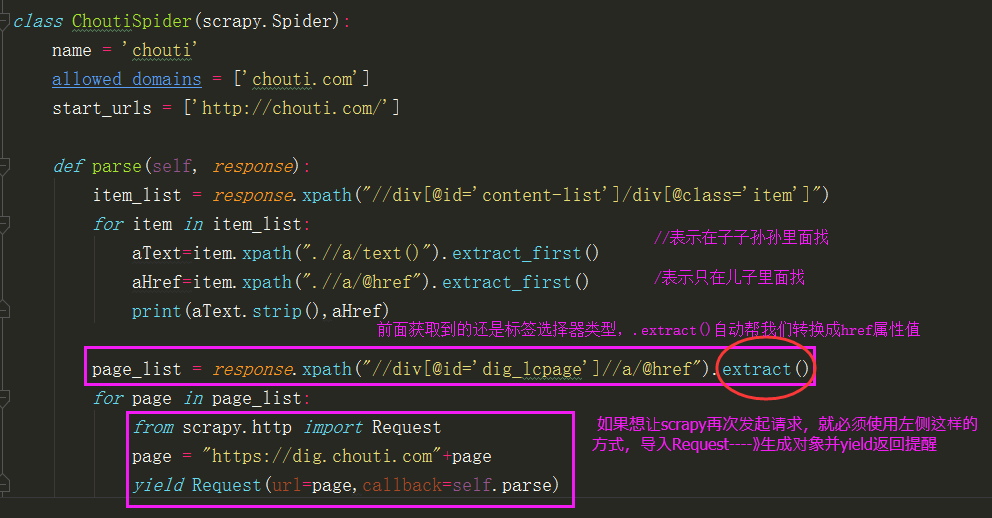
浏览器打开抽屉新闻网,可以轻松的看到,有关新闻的信息都在一个div里面
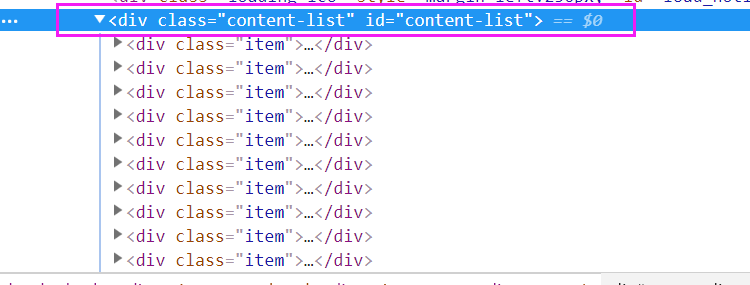
里面的每一个div都是一个个具体的新闻栏。所以我们需要定位到带有item属性的div
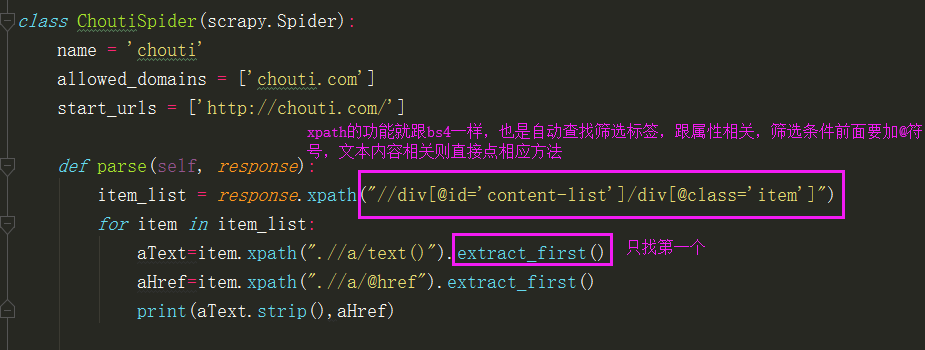
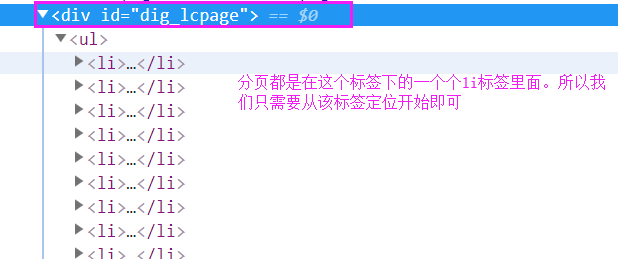
上面的代码,只能爬取到第一页的新闻文本以及对于的url,但是新闻有很多页,我们如何去爬取所有的新闻页内容呢?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号