MongoDB
MongoDB
MongoDB 是一个基于分布式文件存储的数据库。由 C++ 语言编写。旨在为 WEB 应用提供可扩展的高性能数据存储解决方案。在高负载的情况下,添加更多的节点,可以保证服务器性能。
MongoDB 是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。与RDMS最大的区别在于没有固定的行列组织数据结构。
MongoDB 将数据存储为一个文档,数据结构由键值(key=>value)对组成。MongoDB 文档类似于 JSON 对象。字段值可以包含其他文档,数组及文档数组。
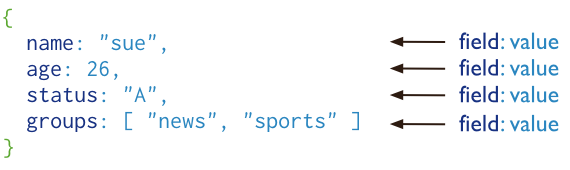
MongoDB的逻辑结构
MySQL MongoDB
库 库
表 集合
列,数据行 文档
BSON
二进制的JSON,JSON文档的二进制编码存储格式,BSON有JSON没有的Data和BinData,mongoDB中的document以BSON形式存放。
分布式系统
分布式系统(distributed system)由多台计算机和通信的软件组件通过计算机网络连接(本地网络或广域网)组成。
分布式系统是建立在网络之上的软件系统。正是因为软件的特性,所以分布式系统具有高度的内聚性和透明性。
因此,网络和分布式系统之间的区别更多的在于高层软件(特别是操作系统),而不是硬件。
分布式系统可以应用在不同的平台上如:Pc、工作站、局域网和广域网上等。
分布式计算的优点
可靠性(容错) :
分布式计算系统中的一个重要的优点是可靠性。一台服务器的系统崩溃并不影响到其余的服务器。
可扩展性:
在分布式计算系统可以根据需要增加更多的机器。
资源共享:
共享数据是必不可少的应用,如银行,预订系统。
灵活性:
由于该系统是非常灵活的,它很容易安装,实施和调试新的服务。
更快的速度:
分布式计算系统可以有多台计算机的计算能力,使得它比其他系统有更快的处理速度。
开放系统:
由于它是开放的系统,本地或者远程都可以访问到该服务。
更高的性能:
相较于集中式计算机网络集群可以提供更高的性能(及更好的性价比)。
分布式计算的缺点
故障排除:
故障排除和诊断问题。
软件:
更少的软件支持是分布式计算系统的主要缺点。
网络:
网络基础设施的问题,包括:传输问题,高负载,信息丢失等。
安全性:
开放系统的特性让分布式计算系统存在着数据的安全性和共享的风险等问题。
MongoDB试用场景
网站数据,缓存,大尺寸低价值的数据,高伸缩性的场景,用于对象及JSON数据的存储
linux下载安装启动


1、上传软件 mkdir /data cd /data 使用xshell上传软件 2、解压软件 tar xf mongodb-linux-x86_64-rhel62-3.2.10.tgz mv mongodb-linux-x86_64-rhel62-3.2.10 mongodb 3、创建mongodb管理用户 useradd mongod passwd mongod 4、修改目录授权 chown -R mongod.mongod /data/mongodb 5、切换或登录mongod用户 su - mongod 6、创建mongod的关键目录 mkdir -p /data/data/mongodb/data /data/data/mongodb/log /data/data/mongodb/conf cd /data/mongodb ls -l 7、修改环境变量 vim ~/.bash_profile 添加一行: export PATH=/data/data/mongodb/bin:$PATH 配置生效一下: source ~/.bash_profile 8、启动mongodb mongod --logpath=/data/data/mongodb/log/mongodb.log --dbpath=/data/data/mongodb/data/ --fork 9、登录mongodb测试 mongo
按照上面的配置启动后,每次启动mongodb都会有报错信息,但是不会影响操作,也可以通过下面的配置来去除报错
root用户下 vim /etc/rc.local 最后添加如下代码: if test -f /sys/kernel/mm/transparent_hugepage/enabled; then echo never > /sys/kernel/mm/transparent_hugepage/enabled fi if test -f /sys/kernel/mm/transparent_hugepage/defrag; then echo never > /sys/kernel/mm/transparent_hugepage/defrag fi vim /etc/security/limits.conf 删掉以下内容行 * - nofile 65535 都修改完成后 重启虚拟机 reboot
配置文件使用
vim /data/mongodb/conf/mongo.conf systemLog: destination: file path: "/data/mongodb/log/mongodb.log" logAppend: true storage: journal: enabled: true dbPath: "/data/mongodb/data/" processManagement: fork: true net: port: 27017 11、mongodb的关闭 mongod -f /data/mongodb/conf/mongo.conf --shutdown 启动: mongod -f /data/mongodb/conf/mongo.conf
用户管理
MongoDB数据库默认是没有用户名以及密码的,即无权限访问限制,为了数据库的管理和安全,需要创建数据库用户。
MongoDB默认端口号是27017
{ user: "<name>", pwd: "<cleartext password>", customData: { <any information> }, roles: [ { role: "<role>", db: "<database>" } | "<role>", ... ] } 基本语法说明: user:用户名 pwd:密码 roles: role:角色 ------->权限的组 db:对象 role:root,readWrite,read
验证数据库
你在哪个库下面创建的用户,该用户在登陆时在登陆末尾必须加上“/库名”,否则登陆进去也无法进行任何操作
开发用户
use test db.createUser( { user: "test", pwd: "123", roles: [ { role: "readWrite", db: "oldboy" } ] } )
管理员
use admin db.createUser( { user: "root", pwd: "root123", roles: [ { role: "root", db: "admin" } ] } )
配置文件生效限制
vim /data/data/mongodb/conf/mongo.conf 添加两行信息: security: authorization: enabled 重启mongodb mongod -f /data/mongodb/conf/mongo.conf --shutdown mongod -f /data/mongodb/conf/mongo.conf
登录验证
开发用户登录:
mongo -utest -p123 10.0.0.200(默认就是test开发库)
管理员用户:
mongo -uroot -proot123 10.0.0.200/admin
或者
mongo
use admin
db.auth('root','root123')
查询用户信息
db.system.users.find().pretty()
删除用户
root身份登录,use到验证库(创建你想删除的用户的库的库)
db.dropUser('用户名')
MongoDB数据操作语言CRUD(增删改查)
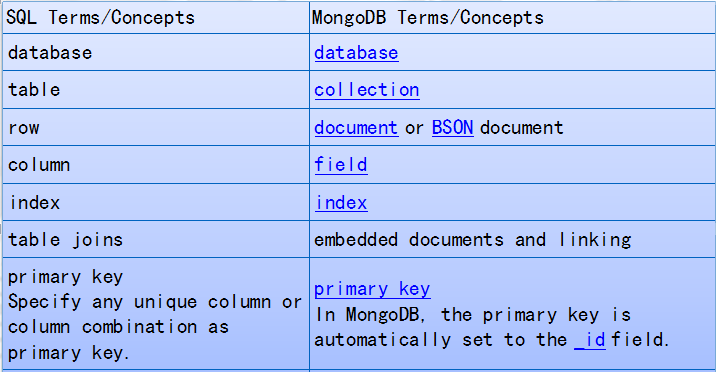

ALTER TABLE users ADD join_date DATETIME
在Collection 级没有数据结构概念。然而在 document级,可以通过$set在update操作添加列到文档中。 db.users.update( { }, { $set: { join_date: new Date() } }, { multi: true } )
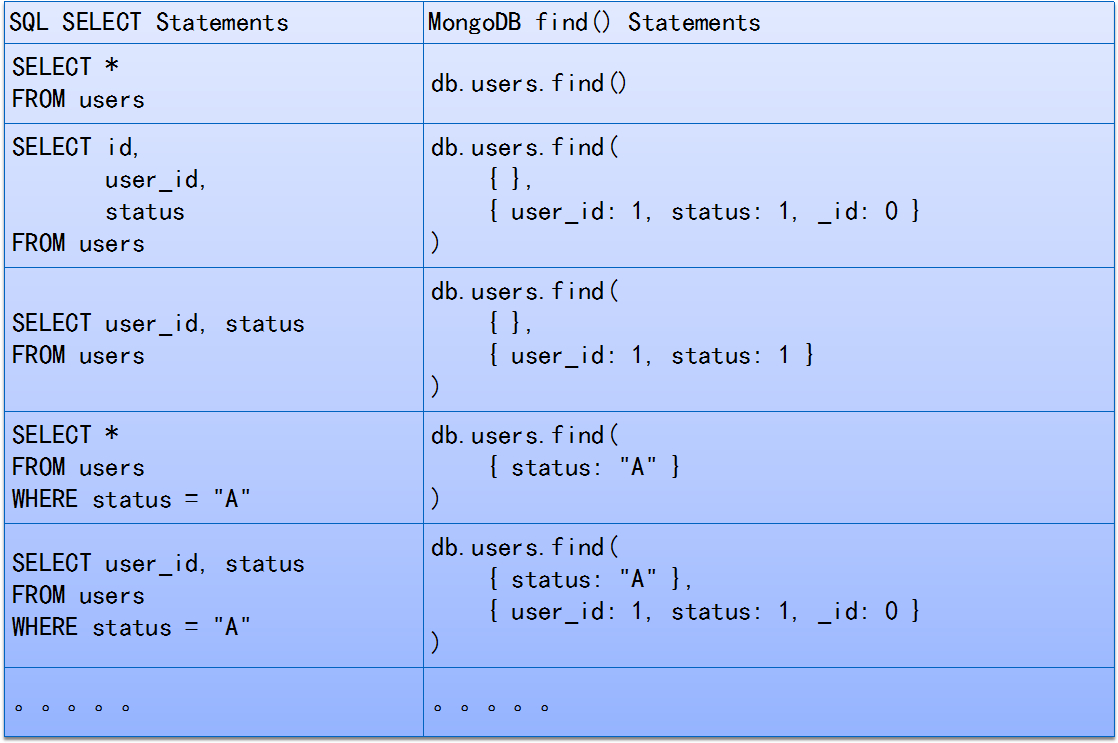
DELETE FROM users WHERE status = "D"
db.users.remove( { status: "D" } )
DELETE FROM users
db.users.remove({})
MongoDB复制集RS
基本原理
一组Mongodb复制集,就是一组mongod进程,这些进程维护同一个数据集合。复制集提供了数据冗余和高等级的可靠性,这是生产部署的基础。
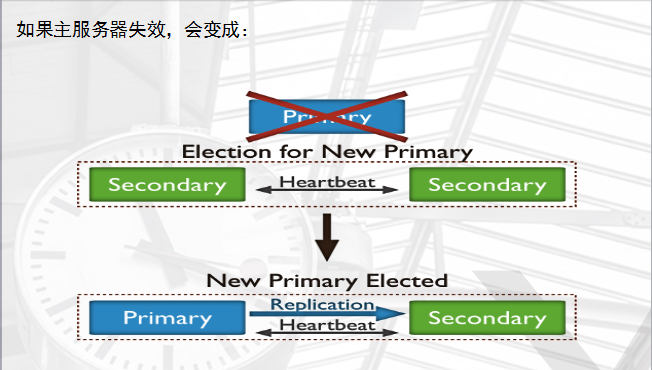
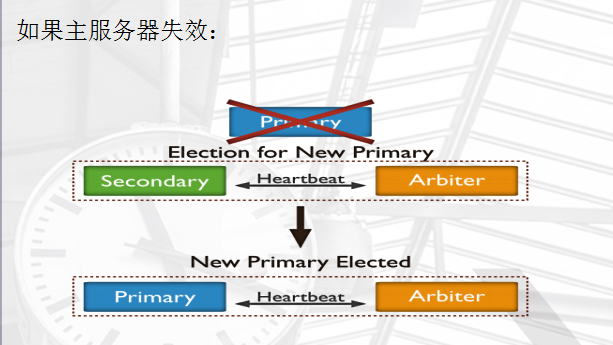
保证数据在生产部署时的冗余和可靠性,通过在不同的机器上保存副本来保证数据的不会因为单点损坏而丢失。能够随时应对数据丢失、机器损坏带来的风险,牛逼到不行。 换一句话来说,还能提高读取能力,用户的读取服务器和写入服务器在不同的地方,而且,由不同的服务器为不同的用户提供服务,提高整个系统的负载,简直就是云存储的翻版... 一组复制集就是一组mongod实例掌管同一个数据集,实例可以在不同的机器上面。实例中包含一个主导,接受客户端所有的写入操作,其他都是副本实例,从主服务器上获得数据并保持同步。 主服务器很重要,包含了所有的改变操作(写)的日志。但是副本服务器集群包含有所有的主服务器数据,因此当主服务器挂掉了,就会在副本服务器上重新选取一个成为主服务器。 每个复制集还有一个仲裁者,仲裁者不存储数据,只是负责通过心跳包来确认集群中集合的数量,并在主服务器选举的时候作为仲裁决定结果。
复制的基本架构
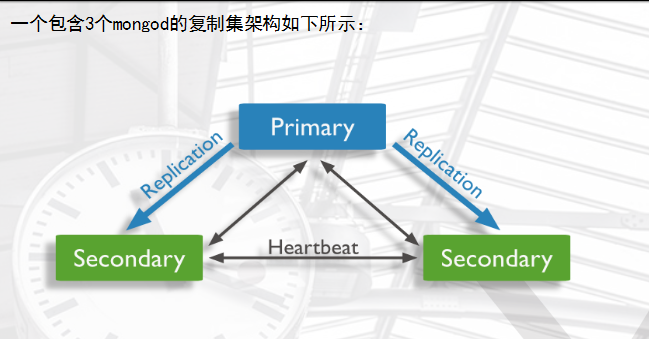
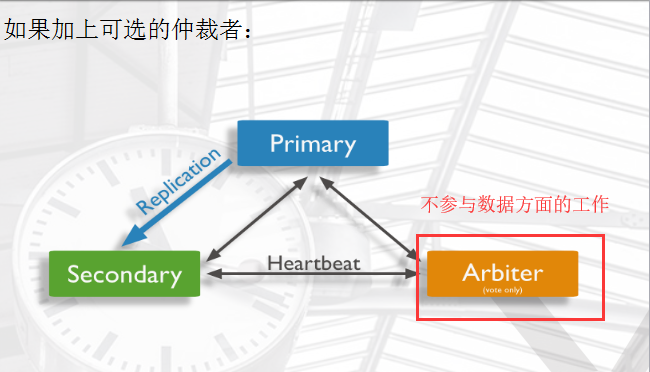
arbiter仲裁者
arbiter节点:主要负责选主过程中的投票,但是不存储任何数据,也不提供任何服务
其他节点
除了仲裁者节点外,还有隐藏节点,延时节点
隐藏节点:不参与选主,也不对外提供服务。
延时节点:数据落后于主库一段时间,因为数据是延时的,也不应该提供服务或参与选主,所以通常会配合hidden(隐藏),主要用来数据回滚,
延时节点的数据集是延时的,因此它可以帮助我们在人为误操作或是其他意外情况下恢复数据。举个例子,当应用升级失败,或是误操作删除了表和数据库时,我们可以通过延时节点进行数据恢复。
搭建三节点MongoDB复制集
Replcation Set配置过程详解 1、规划 三个以上的mongodb节点(或多实例) 多实例: (1)多个端口:28017、28018、28019、28020 (2)多套目录: mkdir -p /data/mongodb/28017/conf /data/mongodb/28017/data /data/mongodb/28017/log mkdir -p /data/mongodb/28018/conf /data/mongodb/28018/data /data/mongodb/28018/log mkdir -p /data/mongodb/28019/conf /data/mongodb/28019/data /data/mongodb/28019/log mkdir -p /data/mongodb/28020/conf /data/mongodb/28020/data /data/mongodb/28020/log (3) 多套配置文件 /data/mongodb/28017/conf/mongod.conf /data/mongodb/28018/conf/mongod.conf /data/mongodb/28019/conf/mongod.conf /data/mongodb/28020/conf/mongod.conf (4)配置文件内容 vim /data/mongodb/28017/conf/mongod.conf systemLog: destination: file path: /data/mongodb/28017/log/mongodb.log logAppend: true storage: journal: enabled: true dbPath: /data/mongodb/28017/data directoryPerDB: true #engine: wiredTiger wiredTiger: engineConfig: cacheSizeGB: 1 directoryForIndexes: true collectionConfig: blockCompressor: zlib indexConfig: prefixCompression: true processManagement: fork: true net: port: 28017 replication: oplogSizeMB: 2048 replSetName: my_repl cp /data/mongodb/28017/conf/mongod.conf /data/mongodb/28018/conf/ cp /data/mongodb/28017/conf/mongod.conf /data/mongodb/28019/conf/ cp /data/mongodb/28017/conf/mongod.conf /data/mongodb/28020/conf/ sed 's#28017#28018#g' /data/mongodb/28018/conf/mongod.conf -i sed 's#28017#28019#g' /data/mongodb/28019/conf/mongod.conf -i sed 's#28017#28020#g' /data/mongodb/28020/conf/mongod.conf -i ------------------------------------------------------------ (5)启动多个实例备用 mongod -f /data/mongodb/28017/conf/mongod.conf mongod -f /data/mongodb/28018/conf/mongod.conf mongod -f /data/mongodb/28019/conf/mongod.conf mongod -f /data/mongodb/28020/conf/mongod.conf netstat -lnp|grep 280 2、配置复制集: (1)1主2从,从库普通从库 mongo --port 28017 admin config = {_id: 'my_repl', members: [ {_id: 0, host: '10.0.0.200:28017'}, {_id: 1, host: '10.0.0.200:28018'}, {_id: 2, host: '10.0.0.200:28019'}] } rs.initiate(config) 3、复制集管理操作: (1)查看复制集状态: rs.status(); //查看整体复制集状态 rs.isMaster(); // 查看当前是否是主节点 (2)添加删除节点 rs.add("ip:port"); // 新增从节点 rs.remove("ip:port"); // 删除一个节点 rs.addArb("ip:port"); // 新增仲裁节点 -------------------------------- 添加 arbiter节点 1、连接到主节点 [mongod@db03 ~]$ mongo --port 28017 admin 2、添加仲裁节点 my_repl:PRIMARY> rs.addArb("10.0.0.200:28020") 3、查看节点状态 my_repl:PRIMARY> rs.isMaster() { "hosts" : [ "10.0.0.200:28017", "10.0.0.200:28018", "10.0.0.200:28019" ], "arbiters" : [ "10.0.0.200:28020" ], ------------------------------- rs.remove("ip:port"); // 删除一个节点 例子: my_repl:PRIMARY> rs.remove("10.0.0.200:28019"); { "ok" : 1 } my_repl:PRIMARY> rs.isMaster() rs.add("ip:port"); // 新增从节点 例子: my_repl:PRIMARY> rs.add("10.0.0.200:28019") { "ok" : 1 } my_repl:PRIMARY> rs.isMaster() --------------------------- 注: 添加特殊节点时, 1>可以在搭建过程中设置特殊节点 2>可以通过修改配置的方式将普通从节点设置为特殊节点 /*找到需要改为延迟性同步的数组号*/; 特殊节点: arbiter节点:主要负责选主过程中的投票,但是不存储任何数据,也不提供任何服务 hidden节点:隐藏节点,不参与选主,也不对外提供服务。 delay节点:延时节点,数据落后于主库一段时间,因为数据是延时的,也不应该提供服务或参与选主, 所以通常会配合hidden(隐藏) 一般情况下会将delay+hidden一起配置使用 (3)配置延时节点(一般延时节点也配置成hidden) cfg=rs.conf() cfg.members[1].priority=0 cfg.members[1].hidden=true cfg.members[1].slaveDelay=120 rs.reconfig(cfg) ------------目前状态------------------- 我的需求是:把28019设置为hidden和delay my_repl:PRIMARY> rs.status() { "members" : [ { "_id" : 0, "name" : "10.0.0.200:28017", }, { "_id" : 1, "name" : "10.0.0.200:28018", }, { "_id" : 3, "name" : "10.0.0.200:28020", }, { "_id" : 4, "name" : "10.0.0.200:28019", } cfg=rs.conf() cfg.members[3].priority=0 cfg.members[3].hidden=true cfg.members[3].slaveDelay=120 rs.reconfig(cfg) --------------------------- 取消以上配置 cfg=rs.conf() cfg.members[3].priority=1 cfg.members[3].hidden=false cfg.members[3].slaveDelay=0 rs.reconfig(cfg) -------------------------------- 配置成功后,通过以下命令查询配置后的属性 rs.conf();
MongoDB分片(Sharding)技术简介
高数据量和吞吐量的数据库应用会对单机的性能造成较大压力,大的查询量会将单机的CPU耗尽,大的数据量对单机的存储压力较大,最终会耗尽系统的内存而将压力转移到磁盘IO上。 为了解决这些问题,有两个基本的方法: 垂直扩展和水平扩展。 垂直扩展:增加更多的CPU和存储资源来扩展容量。 水平扩展:将数据集分布在多个服务器上。水平扩展即分片。
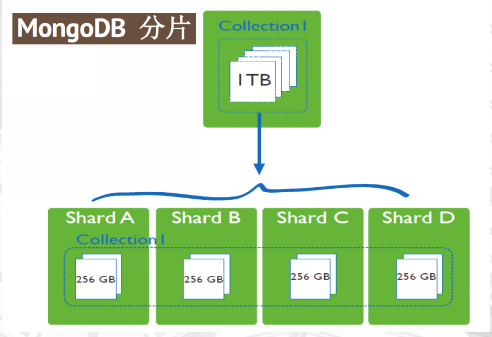
分布式集群架构
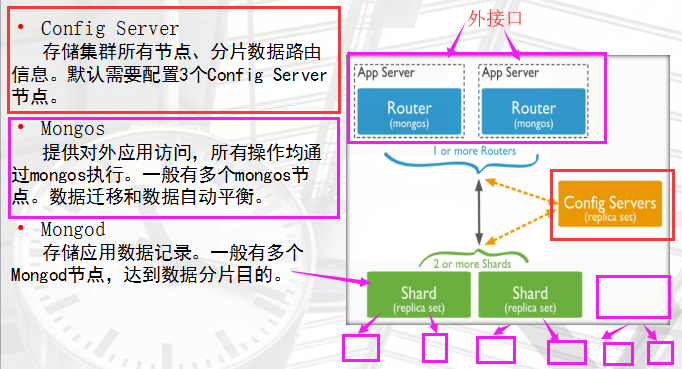
数据分布
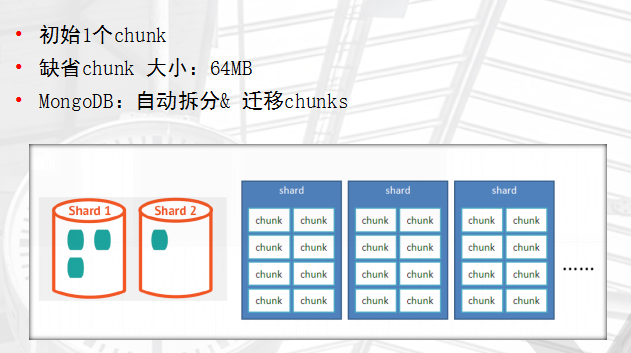
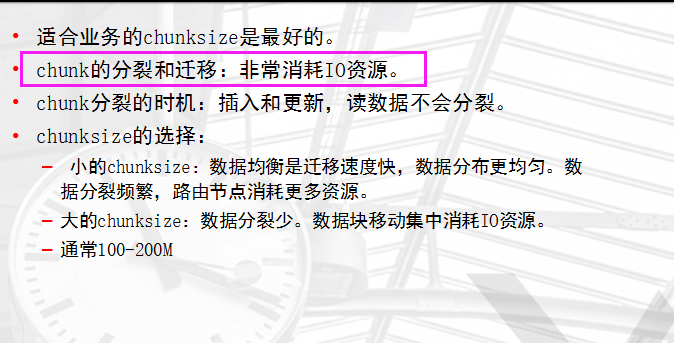
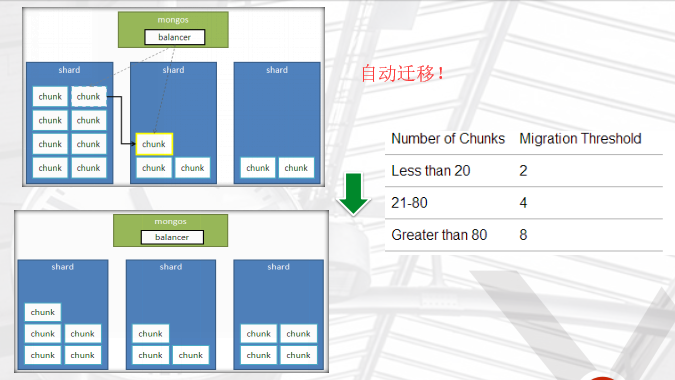
随着数据的增长,其中的数据大小超过了配置的chunk size,默认是64M,则这个chunk就会分裂成两个。数据的增长会让chunk分裂得越来越多。这时候,各个shard 上的chunk数量就会不平衡。这时候,mongos中的一个组件balancer就会执行自动平衡。把chunk从chunk数量最多的shard节点挪动到数量最少的节点。
mongos的路由功能

分片
分片键shard key
必须为分片collection 定义分片键。 基于一个或多个列(类似一个索引)。 分片键定义数据空间。 想象key space 类似一条线上一个点数据。 一个key range 是一条线上一段数据。 我们可以按照分片键进行Range和Hash分片
范围(RANGE)分片
Sharded Cluster支持将单个集合的数据分散存储在多shard上,用户可以指定根据集合内文档的某个字段即shard key来进行范围分片(range sharding)
Hash分片
Hash分片与范围分片互补,能将文档随机的分散到各个chunk,充分的扩展写能力,弥补了范围分片的不足,但不能高效的服务范围查询,所有的范围查询要分发到后端所有的Shard才能找出满足条件的文档。
分片注意事项
分片键是不可变。 分片键必须有索引。 分片键大小限制512bytes。 分片键用于路由查询。 MongoDB不接受已进行collection级分片的collection上插入无分片键的文档(也不支持空值插入)
分片键选择建议
递增的sharding key 数据文件挪动小。(优势) 因为数据文件递增,所以会把insert的写IO永久放在最后一片上,造成最后一片的写热点。 同时,随着最后一片的数据量增大,将不断的发生迁移至之前的片上。 随机的sharding key 数据分布均匀,insert的写IO均匀分布在多个片上。(优势) 大量的随机IO,磁盘不堪重荷。 混合型key 大方向随机递增。 小范围随机分布。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号