突破单点瓶颈、挑战海量离线任务,Apache Dolphinscheduler在生鲜电商领域的落地实践
点亮 ⭐️ Star · 照亮开源之路
GitHub:https://github.com/apache/dolphinscheduler

精彩回顾
近期,食行生鲜的数据平台工程师单葛尧在社区线上 Meetup 上给大家分享了主题为《Apache Dolphinscheduler在食行生鲜的落地实践》的演讲。
随着大数据的进一步发展,不管是离线任务量还是实时任务量都变得越来越多,对调度系统的要求也越来越高,不仅要求系统稳定还要求操作简单,上手方便。
而 Apache Dolphinscheduler 就是当下非常流行且好用的一款调度系统。首先它是分布式运行且是去中心化的,其次有一个非常好的页面,使得调度的任务变得非常容易上手。
讲师介绍

单葛尧
食行生鲜 数据平台工程师
文章整理:硕磐科技-刘步龙
今天的演讲会围绕下面三点展开:
-
背景介绍
-
实施落地
-
元数据系统 Datahub 与 Dolphinscheduler 集成
背景介绍
我司食行生鲜是一家采用“预订制”模式,通过全程冷链配送和社区智能冷柜自提方式,为用户提供优质生鲜服务的新零售企业。
随着业务发展,大量的离线同步及计算任务开始对我们的数据架构的易用性与稳定性带来了挑战。
01 数据架构
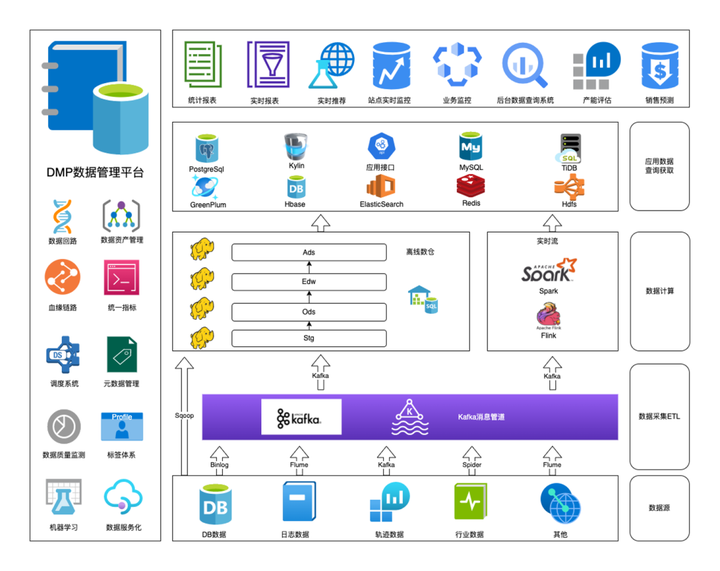
上图是我们目前的基础架构体系,主要是批处理和流处理。批处理主要是以 Hive 和 Spark 为主的的全量数仓的分级计算。流处理以 Flink 为主,主要用于用户轨迹实时 ETL 和实时业务监控,目前采用美柚开源的巨鲸平台,后续会陆续迁移 Apache 新晋项目 StreamPark 中,它支持多个版本的 Flink,提供一系列开箱即用的连接器,大大减轻了开发部署实时任务的复杂度。
我们的数据来源有 MySQL、PostgreSQL、物流供应链端的 SQLServer 数据、同行的数据及风控类的数据。相对应的日志类数据非常多且复杂,故数据类型也多种多样。
我们的业务主体有两种:业务产生的数据,比如说用户去下单,用户的各种余额,积分优惠券;**埋点系统的轨迹数据,**比如说用户的点击、下单、进入商品详情等行为轨迹类操作;
一般来说,T+1的数据采用离线计算,轨迹数据用的是实时计算。
抽数工具是以 Sqoop 为主,其次是 binlog 消费,对于部分不支持的数据源,就用了 Apache SeaTunnel。
经过数仓的复杂计算之后,我们的下游数据的 OLAP 场景主要以 TiDB 和GreenPlum 为主。
TiDB 运用于业务的查询,比如查询近7日某商品的购买量;
GreenPlum 主要以内部的看板为主。比如集团核心的财务指标,运营部门的运营成果及绩效指标; 另外会用 HBase 存储一些维度数, ElasticSearch 存储一些算法模型训练出的画像结果。
**Kylin 用于指标体系。**它服务于我们内部的指标计算。比如站点状态的监控,展现业务成果的各维度。比如今天的实时订单情况,是否需要向供应链增派人力,最近下单的数据流向是否有猛增等现象,以此来调整销售策略。
02 DMP的能力与组成
任务数量随着业务发展日益增长,数据资产的管理、数据质量的监控等问题愈发严峻,DMP(Data Management Platform)的需求应运而生。
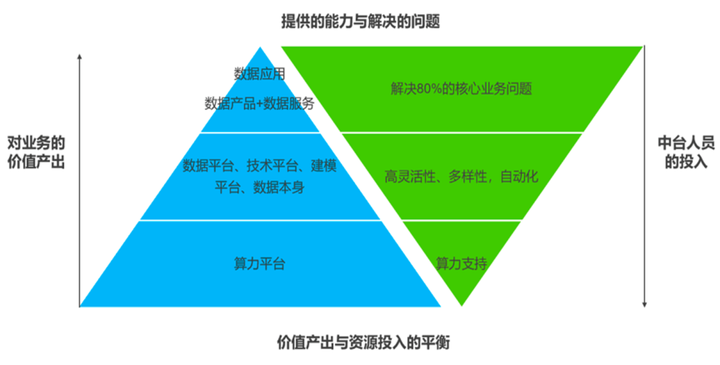
一般而言,DMP 衍生出数据应用,数据应用包括以下能力:
**决策支持类:**主题报表(月度/季度/年度/专题)、舆情监控、热点发现、大屏数据可视化展示等;
**数据分析类:**交互式商业智能、OLAP分析、数据挖掘、数据驱动的机器学习等;
**数据检索类:**全文检索、日志分析、数据血缘分析、数据地图等;
**用户相关:**用户画像服务、用户成长/流失分析及预测、点击率预测、智能推荐等;
**市场相关:**数据服务于搜索引擎、数据服务于推荐引擎、热点发现、舆情监控等;
**制造生产相关:**预测性维护、生产过程实时数据监控、数字孪生等;
实施落地
日益增长的业务系统数据催生了对调度系统的高可用要求,原有自研的单节点调度系统不再适合我们当前的业务体量。
我们开始在市面上调研新的调度工具,然而我们不仅需要调度系统是分布式高可用,还能简单易用,对无编程经验的分析师们提供友好的交互体验,对开发人员也可以支持高扩展性,便于后期可以随着业务增长良好的扩展其可支持的任务类型及集群规模。
01 选择Apache DolphinScheduler
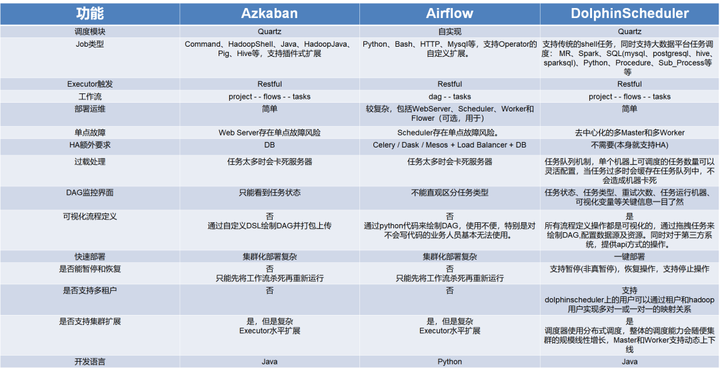
最终我们选择了海豚调度,然而对于我司调度系统的发展经历了几个工具的迁移。
最开始用的是 Azkaban ,因为一些历史原因,后续弃用了 Azkaban ;随后自研了一套调度系统,而随着业务数据的激增,自研系统存在的一个致命问题:该系统为单点式,没有办法扩展资源,只能单机运行;
去年六月份,我们对 AirFlow 和 Dolphinscheduler 做了一个调研。面对业务场景,我们希望以 SQL 的形式去定义 flow ;希望系统以分布式的形式运行,而不是单机,以此来解决单机的瓶颈问题;
AirFlow 的技术栈是 Python,而公司主要是以 Java 为主;
经过比较,我们最终选择了 Dolphinscheduler 。
02 实施落地
去年6月,首次在生产环境接入了 DolphinScheduler 的1.3.6版本,经过业务的锤炼与社区的共建,现已成功更新至3.0.0,至今服务于我司一年有余,平均每日稳定运行6000+任务。
03 任务执行
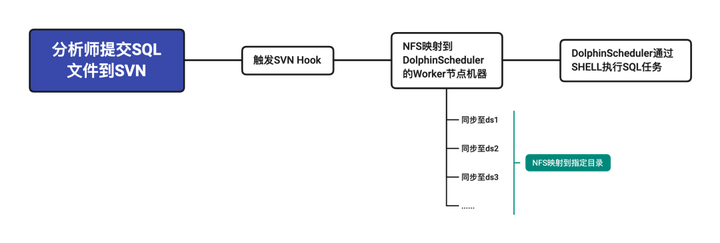
我们在使用 DolphinScheduler 时,主要使用其 Shell 组件,内部封装了 Hadoop 相关 Tools ,用来通过 Shell 提交相关 SQL ,并指定任务提交的 Yarn 资源队列。
我们根据 DolphinScheduler 内部的五个优先级 HIGHEST、HIGH、MEDIUM、LOW、LOWEST 也分别创建了五个对应的 Yarn 资源队列,便于根据流程的优先级提交到指定的优先级队列,更好的去利用并分配资源。
在原有的 Worker 线程池的等待队列中,把从原有的 LinkedBlockingQueue 转换 PriorityBlockingQueue ,以实现超 Worker 其 exec-threads 时可以依照其设定的优先级重新排序,实现高优先级任务在出现异常时,可以在资源较满的情况下实现“插队”效果。
04 告警策略
DolphinScheduler 提供了开箱即用的多种告警组件。
-
Email 电子邮件告警通知
-
DingTalk 钉钉群聊机器人告警,相关参数配置可以参考钉钉机器人文档。
-
EnterpriseWeChat 企业微信告警通知相关参数配置可以参考企业微信机器人文档。
-
Script 我们实现了 Shell 脚本告警,会将相关告警参数透传给脚本,在 Shell 中实现相关告警逻辑,如果需要对接内部告警应用,这是一种不错的方法。
-
FeiShu 飞书告警通知
-
Slack Slack告警通知
-
PagerDuty PagerDuty告警通知
-
WebexTeams WebexTeams告警通知 相关参数配置可以参考WebexTeams文档。
-
Telegram Telegram告警通知 相关参数配置可以参考Telegram文档。
-
HTTP Http告警,调用大部分的告警插件最终都是Http请求。 根据 Alert SPI 的设计,为其扩展了两个插件:内部OA通知+阿里云电话告警,以保证服务的可用性及数据产出的及时性。 DolphinScheduler 的 Alert SPI 设计的相当优秀,我们在新增插件时,只需关注扩展 org.apache.dolphinscheduler.alert.api.AlertChannelFactory 即可。 另外,DolphinScheduler 的告警覆盖场景也相当广泛,可以根据工作流及任务的平时的完成时间来设置超时时间,与新出的数据质量模块相结合,可以较好的保证数据的及时性与准确性。
元数据系统 Datahub与 Dolphinscheduler 集成
Datahub由 LinkedIn 开源,原来叫做 WhereHows 。经过一段时间的发展 Datahub 于2020年2月在 Github 开源,首先简单介绍一下 Datahub 这个系统。
01 总体架构
DataHub 是一个现代数据目录,旨在实现端到端的数据发现、数据可观察性和数据治理。
这个可扩展的元数据平台是为开发人员构建的,以应对其快速发展的数据生态系统的复杂性,并让数据从业者在其组织内充分利用数据的价值。
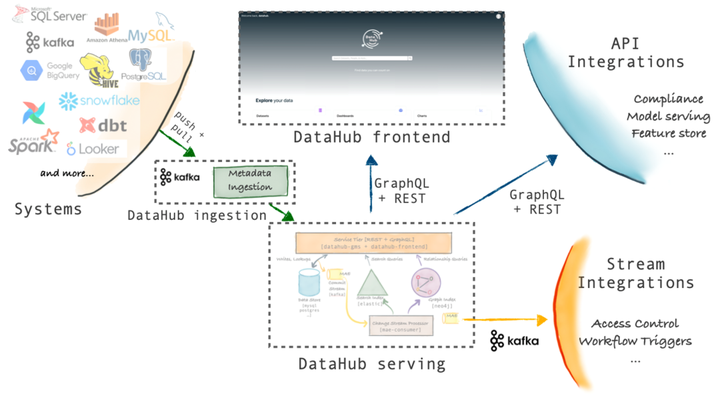
02 搜索元数据
DataHub 的统—搜索支持跨数据库、数据湖、BI平台、ML功能存储、编排工具等显示结果。
支持的 Source 相当丰富,目前截止v0.8.45已有
Airflow、Spark、Great Expectations、Protobuf Schemas、Athena、Azure AD、BigQuery、Business Glossary.ClickHouse.csv、dbt、Delta Lake、Druid、ElasticSearch.Feast、FileBased Lineage、File、Glue.SAP HANA、Hive、lceberg.Kafka Connect、Kafka、LDAP、Looker、MariaDB、Metabase、Mode、MongoDB、MicrosoftsQLServer、MySQL、Nifi、Okta、OpenAPI、Oracle,Postgres、PowerBl、Presto onHive、Pulsar、Redash.Redshift、S3 Data Lake.SageMaker、Salesforce、Snowflake、Other SQLAlchemydatabases、Superset.Tableau、Trino、Vertica等。
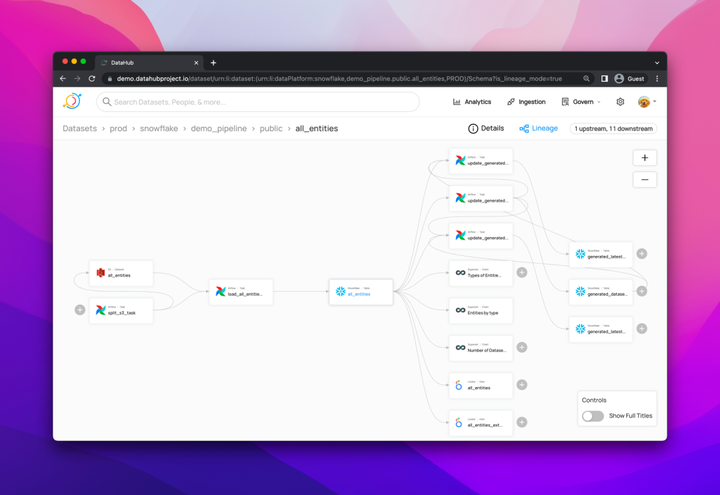
03 血缘支持
可通过跨平台、数据集、ETL/ELT管道、图表、仪表板等跟踪血缘,快速了解数据的端到端的流向。
与市面上其他元数据系统不—样的是,Datahub 一直支持从数据集到B看板的整个流向的追踪,已经为我们提供了如 Redash、SuperSet 之类开源看板的元数据接入。
04 元数据的抽取步骤
**第一步:**开启元数据采集和创建密钥的权限;
**第二步:**选择所摄取血缘的数据源(除了当前所支持的外,也支持自定义);

**第三步:**配置采集血缘的表以及下游走向;
**第四步:**设置时区与定时,元数据采集就会像我们的调度系统一样,定时调取完成采集。
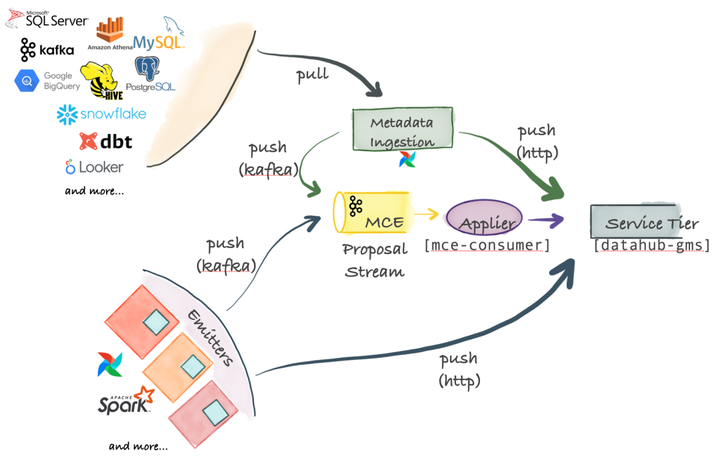
05 Metadata Ingestion架构
Pull-based lntegration
DataHub 附带一个基于 Python 的元数据摄取系统,该系统可以连接到不同的源以从中提取元数据。然后,此元数据通过 Kafka 或 HTTP 推送到 DataHub 存储层。元数据摄取管道可以与 Airflow 集成,以设置计划摄取或捕获血缘。
Push-based Integration
只要您可以向 Kafka 发出元数据更改建议(MCP)事件或通过 HTTP 进行 REST 调用,您就可以将任何系统与 DataHub 集成。
为方便起见,DataHub 还提供简单的 Python 发射器供您集成到系统中,以在源点发出元数据更改(MCP-s)。
06 Datahub与Dolphinscheduler集成
方案一 通过 Kafka 作为 MetadataChangeEvent 发出简单的 dataset 到 dataset 的血缘
import datahub.emitter.mce_builder as builder
from datahub.emitter.kafka_emitter import DatahubKafkaEmitter, KafkaEmitterConfig
# Construct a lineage object.
lineage_mce = builder.make_lineage_mce(
[
builder.make_dataset_urn("bigquery", "upstream1"),
builder.make_dataset_urn("bigquery", "upstream2"),
],
builder.make_dataset_urn("bigquery", "downstream"),
)
# Create an emitter to DataHub's Kafka broker.
emitter = DatahubKafkaEmitter(
KafkaEmitterConfig.parse_obj(
# This is the same config format as the standard Kafka sink's YAML.
{
"connection": {
"bootstrap": "broker:9092",
"producer_config": {},
"schema_registry_url": "http://schema-registry:8081",
}
}
)
)
# Emit metadata!
def callback(err, msg):
if err:
# Handle the metadata emission error.
print("error:", err)
emitter.emit_mce_async(lineage_mce, callback)
emitter.flush()
方案二:通过Rest去emit血缘关系。
import datahub.emitter.mce_builder as builder
from datahub.emitter.rest_emitter import DatahubRestEmitter
# Construct a lineage object.
lineage_mce = builder.make_lineage_mce(
[
builder.make_dataset_urn("bigquery", "upstream1"),
builder.make_dataset_urn("bigquery", "upstream2"),
],
builder.make_dataset_urn("bigquery", "downstream"),
)
# Create an emitter to the GMS REST API.
emitter = DatahubRestEmitter("http://localhost:8080")
# Emit metadata!
emitter.emit_mce(lineage_mce)
上述形式适用于所有 dataset 到 dataset 的血缘关系构建,可以在任何数据集处理下使用。
后续在社区的贡献计划
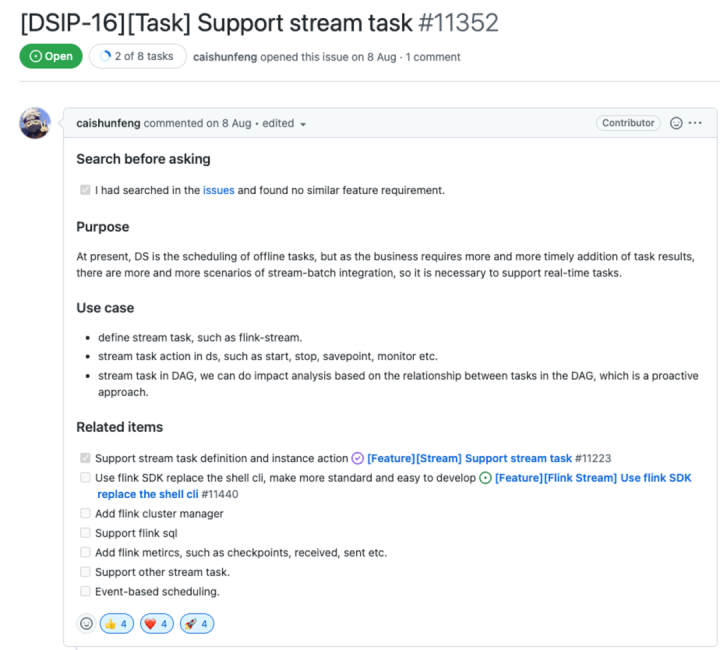
01 对流处理的支持(flink stream与debezium)
在社区PMC蔡顺峰的帮助下,**现在已经完成了对流任务的初步集成,**可以通过 Flink sdk 去提交任务到 Yarn ,可视化的启动、停止、Savepoint,直观的在列表里看到任务的 Yarn Application ID 和 Job ID 等信息。
接下来的TODO LIST顺峰已经写在 related items 里
-
flink 集群管理
-
支持 flink sql
-
增加 flink 的metric
-
支持其他流任务(如 kafka connector)
-
事件驱动调度(最终目标)
02 与版本管理工具的集成(GIT与SVN)
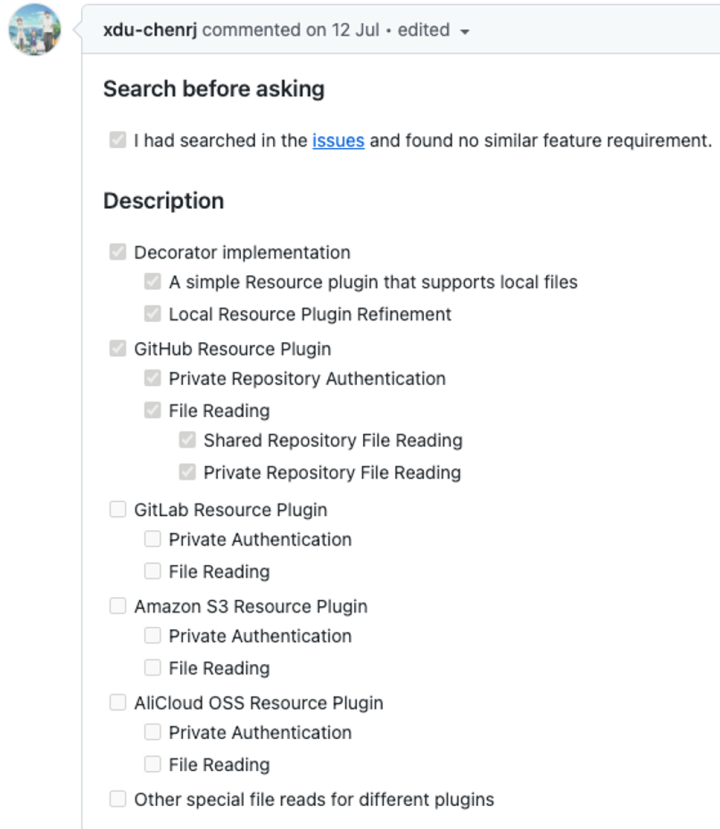
社区确实是能人辈出,我们准备的这个 RoadMap ,我不仅在 DSIP 里找到了提案,而且提案还提到了以下几个资源插件:
-
GitHub
-
GitLab
-
Amazon S3
-
AliCloud OSS
当然,基于底层 Decorator implementation 的存在,该 Resource Plugin 会非常的易于扩展。
当时在准备 Data Quality 相关开发时,就惊喜的发现社区提供了相关的提案,我们仅是在3.0.0上稍作改动,就投入了生产环境的使用,提供了我们数据准确性、及时性等多重保障。
我们后期准备在该基础上扩展社区的 HiveCli 插件,并把我们目前的工程逐步从 SVN 迁移到 Git 上,以摆脱目前纯 Shell 使用,让分析师们更关注于业务。
03 更好的与yarn集群及队列的管理与使用
我司目前的所有资源调度都是基于 Yarn 的,包括所有的 MapReduce、Spark及Flink 任务,统一都由 Yarn 来管理。
由于历史遗留原因及测试生产环境的隔离等因素,目前集群存在多套 Yarn 环境,每个 Yarn 的资源总量及策略配置各不相同,导致管理困难。
再者,基于 DolphinScheduler 设计来看,Yarn 队列与执行的用户绑定,用户来定义默认的租户及提交队列。这个设计不太符合生产环境的要求,租户来定义数据的权限,队列来定义任务的资源,后面我们会把队列单独作为一个配置或是直接把提交队列和任务的优先级绑定。
Yarn 环境的多套集群管理,可以后期远程提交任务到指定集群,来替换掉目前的方案,后期可以在调度里可以直接监控调度系统里的任务在 Yarn 的一些运行状态。
04 更好的与DataHub的集成

给大家提供一个好用的Python插件,SqlLineage,可解析SQL语句中的信息。
给定一个 sql 语句,sqllineage 将告诉您源表和目标表。如果您想要血缘结果的图形可视化,可以切换它的切换图形可视化选项,此时就会启动一个 web ,在浏览器中显示血缘结果的 DAG 图,目前我司基于此组件解析了我们版本管理工具下的所有 sql ,在此基础上构建了我们的上下游血缘。
后期我们将会依照 Datahub 的 Airflow 组件功能,扩展开发 Datahub 的 Dolphinscheduler 元数据组件。
[lineage]
backend = datahub_provider.lineage.datahub.DatahubLineageBackend
datahub_kwargs = {
"datahub_conn_id": "datahub_rest_default",
"cluster": "prod",
"capture_ownership_info": true,
"capture_tags_info": true,
"graceful_exceptions": true }
Datahub 的 Airflow 血缘配置如上所示,可以发现 Datahub 为 Airflow 提供了开箱即用的 acryl-datahub[airflow] 插件,提供以下功能:
-
Airflow Pipeline (DAG) metadata
-
DAG and Task run information
-
Lineage information when present
我们会扩展 Dolphinscheduler 的 Python Gateway 能力,后续将会回馈到社区,希望可以为大家提供更好的元数据系统集成体验。
参与贡献
随着国内开源的迅猛崛起,Apache DolphinScheduler 社区迎来蓬勃发展,为了做更好用、易用的调度,真诚欢迎热爱开源的伙伴加入到开源社区中来,为中国开源崛起献上一份自己的力量,让本土开源走向全球。
参与 DolphinScheduler 社区有非常多的参与贡献的方式,包括:
贡献第一个PR(文档、代码) 我们也希望是简单的,第一个PR用于熟悉提交的流程和社区协作以及感受社区的友好度。
社区汇总了以下适合新手的问题列表:https://github.com/apache/dolphinscheduler/issues/5689
非新手问题列表:https://github.com/apache/dolphinscheduler/issues?q=is%3Aopen+is%3Aissue+label%3A"volunteer+wanted"
如何参与贡献链接:https://dolphinscheduler.apache.org/zh-cn/community/development/contribute.html
来吧,DolphinScheduler开源社区需要您的参与,为中国开源崛起添砖加瓦吧,哪怕只是小小的一块瓦,汇聚起来的力量也是巨大的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号