Tensorflow笔记_人工智能基础知识
1:人工智能的基础及其含义
2:神经网络基础
3:神经网络八股
1:人工智能:机器模拟人的意思跟思维
2:机器学习:实现人工智能的一种方法,是人工智能的子集
3:深度学习:是深层次的神经网络,是机器学习的一种实现的方法,是机器学习的子集
4:机器学习的定义:如果一个程序可以在人物T上,随着经验E的增加,效果P随之增加,这个程序可以从经验中学习
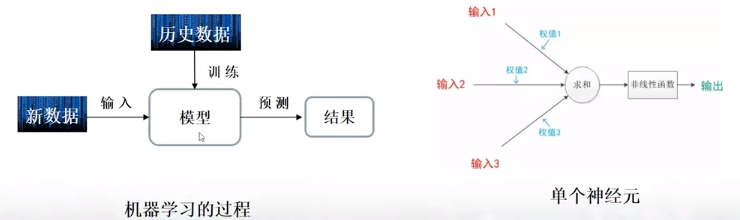
5:机器学习的过程/单个神经元
1:用 张量 表示数据
2:用 计算图 搭建神经网络
3:用 会话 执行计算图
# 1 张量( tensor )
- 多维数组(列表),用"阶"表示张量的维数,张量可以表示0阶到N阶数组
- 判断张量是几阶的:通过张量游标的方括号数,0个就是0阶,n个就是n阶
维数 阶 名字 例子 0-D 0 标量 scalar s = 123 1-D 1 向量 vector v = [1,2,3] 2-D 2 矩阵 matrix m = [[1,2,3],[4,5,6]] n-D n 张量 tensor t =[[[....]]]
# 2 计算图
- 搭建神经网络的计算过程,只搭建,不运算
- 计算图只描述运算过程,不计算运算的结果
- tf.constant 定义常数
- 在tensorflow中的数据的类型有 浮点型:tf.float32 整形:tf.int32
# 实现Tensorflow
# vim中编辑 import tensorflow as tf a = tf.constant([1.0,2.0]) # 定义一个张量a的值为常数1.0 2.0 b = tf.constant([3.0,4.0]) # 定义一个张量b的值为常数3.0 4.0 result = a + b print result # 在终端中输出结果 python tf3_1.py # 输出的结果为(显示的结果为一个张量,但没有输出运算结果) Tensor("add:0", shape=(2,), dtype=float32) # add:节点名 0:第0个输出 shape:维度 2:一维数组的长度为2 dtype=float32数据类型为浮点型# 搭建计算图
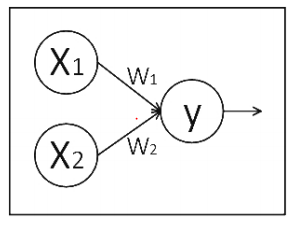
x1,x2表示输入,w1,w2分别是x1到y和x2到y的权重,y = x1 * w1 + x2 * w2
实现上方的计算图
import tensorflow as tf x = tf.constant([[1.0, 2.0]]) # 定义一个 2 阶张量等于[[1.0,2.0]] w = tf.constant([[3.0], [4.0]]) # 定义一个 2 阶张量等于[[3.0],[4.0]] y = tf.matmul(x, w) 矩阵乘法 print y
# 输出显示的结果表示y是一个张量,只搭建承载计算过程的计算图,并没有运算,可利用Session()来得到计算结果(看下方会话)# 3 会话( Session ):
会话:执行图中节点运算
import tensorflow as tf x = tf.constant([[1.0,2.0]]) w = tf.constant([3.0],[4.0]]) y = tf.matmul(x,w) # y是x和w的矩阵乘法 print y with tf.Session() as sess: print sess.run(y) # sess.run(y) 要执行计算结果 执行y运算 # 执行后的结果 # doaoao@ubuntu:~/tf$ python tf3_4.py Tensor("MatMul:0", shape=(1, 1), dtype=float32) # 表示y是一个张量 [[11.]] # 执行后的结果 # 计算过程1.0*3.0 + 2.0*4.0 = 11.0# 注:修改Tensorflow的配置文件(让Tensorflow的提示等级降低)
doaoao@ubuntu:~/tf$ vim ~/.bashrc #打开其配置文件 doaoao@ubuntu:~/tf$ source ~/.bashrc # 让所修改的配置生效 # 在配置文件中加入 export TF_CPP_MIN_LOG_LEVEL=2# 4 参数
参数:即神经元线上的权重 W ,用变量表示,随机给初始值
w = tf.Variable(tf.random_normal([2,3], stddev=2, mean=0, seed=1)) # 生成随机数 将生成的方式写在括号中 # 后三个如果没有特殊要求,可以不写 # tf.random_normal :表示生成正态分布的随机数 # [2,3] :产生2*3的矩阵 两行三列 # stddev=2 :标准差为2 # mean=0 :均值为0 # seed=1 : 随机种子(如果将随机种子去掉,每次生成的随机数将不一致) # tf.truncated_normal # 生成去掉过大偏离点的正态分布 # 如果随机出来的数,偏离平均值超过两个标准差,这个数据将重新生成 # tf.random_uniform() 生成均匀分布的随机数tf.zeros 全0的数组 tf.zeros([3,2],int32) 生成 [[0,0],[0,0],[0,0]] tf.ones 全1的数组 tf.ones([3,2],int32) 生成 [[1,1],[1,1],[1,1]] tf.fill 全定值的数组 tf.fill([3,2],6) 生成 [[6,6],[6,6],[6,6]] tf.constant 直接给出数组的值 tf.constant([3,2,1]) 生成 [3,2,1]# 5 神经网络的实现过程(前三个步骤为训练过程,第四步为使用过程)
- 准备数据集,提取特征,作为输入喂给神经网络
- 包括数据集的特征,包括数据集的标签(如零件是否合格)
- 搭建NN结构,从输入到输出(先搭建计算图,在用会话执行)
- ( NN前向传播法 -> 计算输出 )
- 大量特征数据为给NN,迭代优化参数
- ( NN 反向传播法 -> 优化参数训练模型 )
- 将大量数据喂给神经网络,得到大量输出,将每次输出与标准答案的差传给神经网络,知道模型达到要求
- 使用训练好的模型训练和分类
# 6 前向传播(搭建模型,实现推理)
前向传播就是搭建模型的计算过程,让模型具有推理能力,可以针对一组输入给出相应的输出
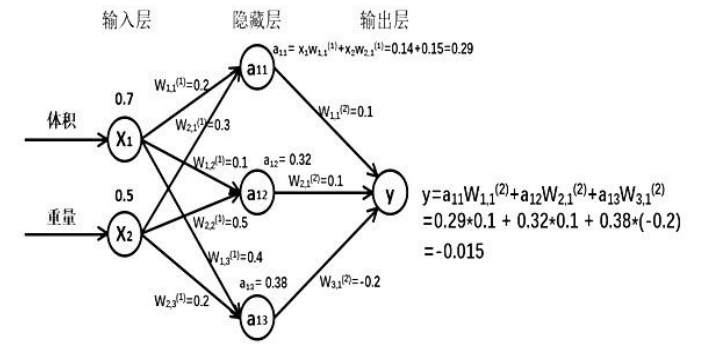
例如:生产一批零部件,将体积为x,重量为y的特征输入NN,当体积和总量通过NN后输出一个数值
由搭建的神经网络可得,隐藏层节点 a11 = x1* w11+x2*w21=0.14+0.15=0.29,也可算得节点 a12 = 0.32,a13 = 0.38,最终计算得到输出层 Y = -0.015,这便实现了 前向传播过程
# 第一层
1:用x表示输入,是一个一行两列的矩阵,表示一次输入一组特征,这组特征包含了体积和重量两个元素
2:W 前节点编号,后节点编号 (层数) 为待优化参数,第一层的w前面有两个节点(x1,x2),后面有三个节点(a11,a22,a13),w是个两行三列的矩阵,可以表示为
3:神经网络共有几层(或当前属于第几层)都是指的是计算层,输入层不算是计算层,所以a为第一层网络,a是一个一行三列的矩阵
# 第二层
1:第二层w前面有三个节点,后面有一个节点,所以W(2)是一个三行一列的矩阵,可表示为如下
1:变量的初始化,计算图节点运算都要用会话(wish结构)实现
wish tf.Session() as sess: sess.run()2:变量的初始化:在sess.run函数中用 tf.global_varlables_initiallzer() 汇总所有的变量
init_op = tf.global_varlables_initiallzer() sess.run(init_op)3:计算图节点运算:在sess.run函数中,写入待运算的节点
sess.run(y)4:先用tf.placeholder 帮输入占位,在sess.run 函数中用feed_dict 喂数据
# 喂一组数据 # 1表示喂入一组数据 2表示喂入数据的特征有几个(比如重量体积有两个特征) x = tf.placeholder(tf.float,shape=(1,2)) sess.run(y,feed_dict={x: [[0.5,0.6]]}) # 一次性喂多组数据 # None 表示先空着 x = tf.placeholder(tf.float,shape=(None,2)) sess.run(y,feed_dict={x: [[0.1,0.2],[0.3,0.4]]})# 向神经网络中国写入特定的值
#coding:utf-8 import tensorflow as tf
# 定义输入和参数 x = tf.constant([[0.7,0.5]]) # 定义体积和参数 w1 = tf.Variable(tf.random_normal([2,3],stddev=1,seed=1)) # 2行3列的正态分布随机数矩阵,标准差为1,随机种子为1 w2 = tf.Variable(tf.random_normal([3,1],stddev=1,seed=1))
# 定义前向传播的过程 a = tf.matmul(x,w1) # x与w1的矩阵乘法 y = tf.matmul(a,w2) # a与w2的矩阵乘法
# 用会话计算结果 with tf.Session() as sess: init_op = tf.global_variables_initializer() # 将初始化所有变量的函数简写为 init_op sess.run(init_op) print "y in tf3_5.py is :\n",sess.run(y)# 向神经网络中喂入一组数据(特征)
#coding:utf-8 import tensorflow as tf
# 定义输入和参数
# 用placeholder实现输入定义(喂入一组特征 shape中的第一个参数为1) x = tf.placeholder(tf.float32,shape=(1,2)) w1 = tf.Variable(tf.random_normal([2,3],stddev=1,seed=1)) w2 = tf.Variable(tf.random_normal([3,1],stddev=1,seed=1))
# 定义向前传播过程 a = tf.matmul(x,w1) y = tf.matmul(a,w2)
# 用会话计算结果 with tf.Session() as sess: init_op = tf.global_variables_initializer() sess.run(init_op) print "y in tf3_5.py is :\n",sess.run(y,feed_dict={x: [[0.7,0.5]]})# 向神经网络喂入多组数据(特征)
#coding:utf-8 import tensorflow as tf # 定义输入和参数 # 利用placeholder 定义输入 (sess.run 喂入多组数据)(因为不知道喂入多少组,所以shape中的第一个参数为None) x = tf.placeholder(tf.float32,shape=(None,2)) w1 = tf.Variable(tf.random_normal([2,3],stddev=1,seed=1)) w2 = tf.Variable(tf.random_normal([3,1],stddev=1,seed=1)) #定义向前传播的过程 a = tf.matmul(x,w1) y = tf.matmul(a,w2) # 调用会话计算结果 with tf.Session() as sess: init_op = tf.global_variables_initializer() sess.run(init_op)
# 第一组喂体积0.7重量0.5,第二组喂体积0.2重量0.3.... print "y in tf3_5.py is :\n",sess.run(y,feed_dict={x: [[0.7,0.5],[0.2,0.3],[0.3,0.4],[0.4,0.5]]}) print "w1:\n", sess.run(w1) # 可以查看随机生成的w1 print "w2:\n", sess.run(w2) # 可以查看随机生成的w2# 7 反向传播
1:反向传播:训练模型参数,在所有的参数上用梯度下降,使NN模型在训练的数据上的损失函数最小
2:反向传播的训练方法:以减小loss值为优化的目标
3:损失函数(loss):预测值(y)与已知的答案(y_)的差距
4:均方误差MSE:求向前传播计算结果与已知答案之差的平方再求平均
用tensorflow函数表示为:loss = tf.reduce_mean(tf.square(y_-y)) //已知答案减去前向传播计算出来的结果
5:反向传播的训练方法:以减小loss值为优化目标(训练时选择下方其中一个即可)
# 梯度下降
strain_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(losss)
# Momenttum优化器
strain_step = train.MomenttumOptimizer(learning_rate,momentum).minimize(loss)# Adam优化器
strain_stept = tf.train.AdamOptimizer(learning_rate).minimize(lose)
# 三种优化器的区别
1:梯度下降法,使用梯度下降法,使参数沿着梯度的反方向,即总损失减小的方向移动,实现更新参数
2:monenttum优化器,在更新参数时,利用了超参数
3:Adam优化器,利用自适应学习率的优化算法,Adam算法和随机梯度下降算法不同。
随机梯度下降算法保持单一的学习率更新所有的参数,学习率在训练过程中并不会改变。
而 Adam 算法通过计算梯度的一阶矩估计和二 阶矩估计而为不同的参数设计独立的自适应性学习率。# 上方的优化器都需要一个称为学习率的参数 learning_rate
6:学习率 learning_rate :决定参每次的更新幅度,使用时可以选择一个比较小的值填入神经网络的实现过程
(学习率过大:震荡不收敛情况 学习率过小:会出现收敛速度慢情况)
7:神经网络的实现过程
7.1:准备数据集,提取特征,作为输入喂给神经网络
7.2:搭建神经网络结构,从输入到输出(先搭建计算图,在用会话执行)(神经网络前向传播算法->计算输出
7.3:大量的数据特征喂给神经网络,迭代优化神经网络参数(神经网络反向传播->优化训练模型)
7.4:使用训练号的模型进行预测和分类
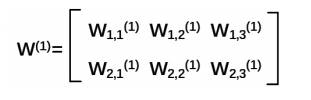
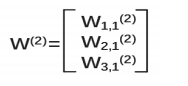
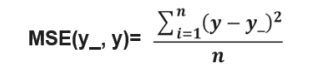
1:准备
# import相关模块 # 常量的定义 # 生成数据集
2:前向传播:定义输入 定义输出
Y = (数据集的标签)
x =(输入参数)
y_ = (标准答案)
w1 = (第一层网络的参数)
w2 = (第二层网络的参数)
a = (先用矩阵乘法求出 a)
y = (定义推理过程 用矩阵乘法求出 y)
3:反向传播:定义损失函数,反向传播的方法
loss= (定义损失函数)
train_step= (反向传播方法)
4:生成会话 训练STEPS轮
在with中完成迭代
# coding:utf-8 # 导入模块 生成模拟的数据集 import tensorflow as tf # 导入numpy模块 python的科学计算模块 import numpy as np # 一次喂入神经网络多少组数据 不能过大 BATCH_SIZE = 8 seed = 23455 # 基于seed产生的随机数 rng = np.random.RandomState(seed) # 随机数返回32行2列的矩阵 表示具有32组 具有两种特征(体积 重量) # 作为输入的数据集 X = rng.rand(32,2) # 从这个32行2列的矩阵中 取出一行 判断如果小于1 给Y赋值1 否则给Y赋值0 # Y 作为输入数据集的标签(输入数据集的正确答案) 体积 + 重量 < 1为合格(因为没有数据,所以这样标记) Y = [[int(x0 + x1 < 1)] for (x0, x1) in X] print "X:\n",X print "Y:\n",Y # 定义神经网络的 输入 参数 输出 定义向前传播的过程 x = tf.placeholder(tf.float32, shape=(None, 2)) # 正确答案的标签(每个标签只有一个元素 合格或者不合格) y_ = tf.placeholder(tf.float32, shape=(None, 1)) # w1(两行三列) 对应x w2(三行一列) 对应y w1 = tf.Variable(tf.random_normal([2, 3],stddev=1, seed=1)) w2 = tf.Variable(tf.random_normal([3, 1],stddev=1, seed=1)) # 前向传播的计算过程描述 用矩阵乘法实现 a = tf.matmul(x, w1) y = tf.matmul(a, w2) # 定义损失函数loss 及反向传播方法
# 使用均方误差计算loss
loss = tf.reduce_mean(tf.square(y-y_)) # 将其学习率设置为0.001 (下方使用的为梯度下降) train_step = tf.train.GradientDescentOptimizer(0.001).minimize(loss) # 生成回话 训练STEPS轮 with tf.Session() as sess: init_op = tf.global_variables_initializer() sess.run(init_op) # 打印优化前的参数 w1 w2 print "w1:\n",sess.run(w1) print "w2:\n",sess.run(w2) print "\n" # 训练模型 STEPS = 3000 for i in range(STEPS): start = (i*BATCH_SIZE) % 32 end = start + BATCH_SIZE # 抽取相应的数据集 从start 到 end 的特征和标签,喂入神经网络 sess.run(train_step, feed_dict={x: X[start:end],y_: Y[start:end]}) if i % 500 == 0: total_loss = sess.run(loss, feed_dict={x:X,y_:Y}) print ("After %d,%g" % ( i,total_loss)) # 输出训练后的参数值 print "\n" print "w1:\n",sess.run(w1) print "w2:\n",sess.run(w2)...
...

 浙公网安备 33010602011771号
浙公网安备 33010602011771号