Spark for ETL & Data Science
Spark for ETL & Data Science
重点问题
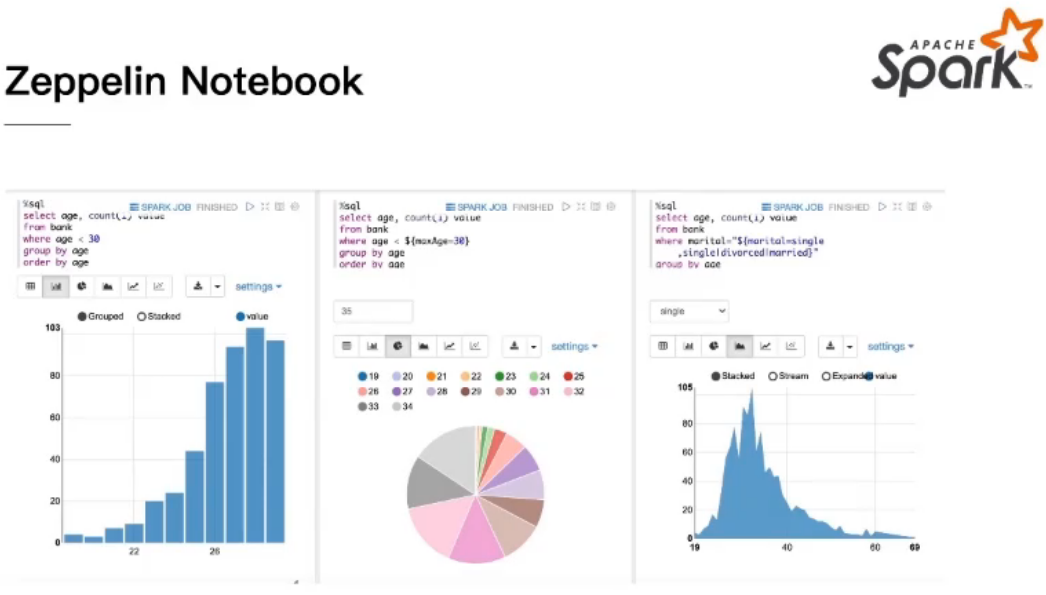
Zeppelin 支持哪些引擎
Zeppelin支持Spark的哪些运行模式
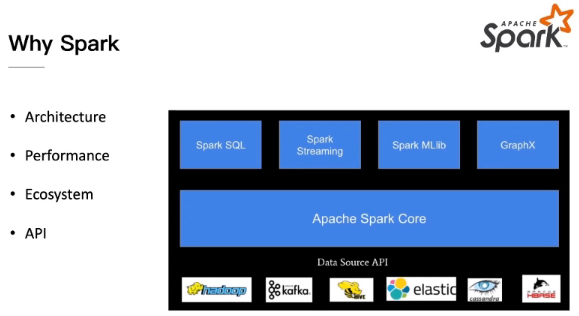
What is ETL & Data Science
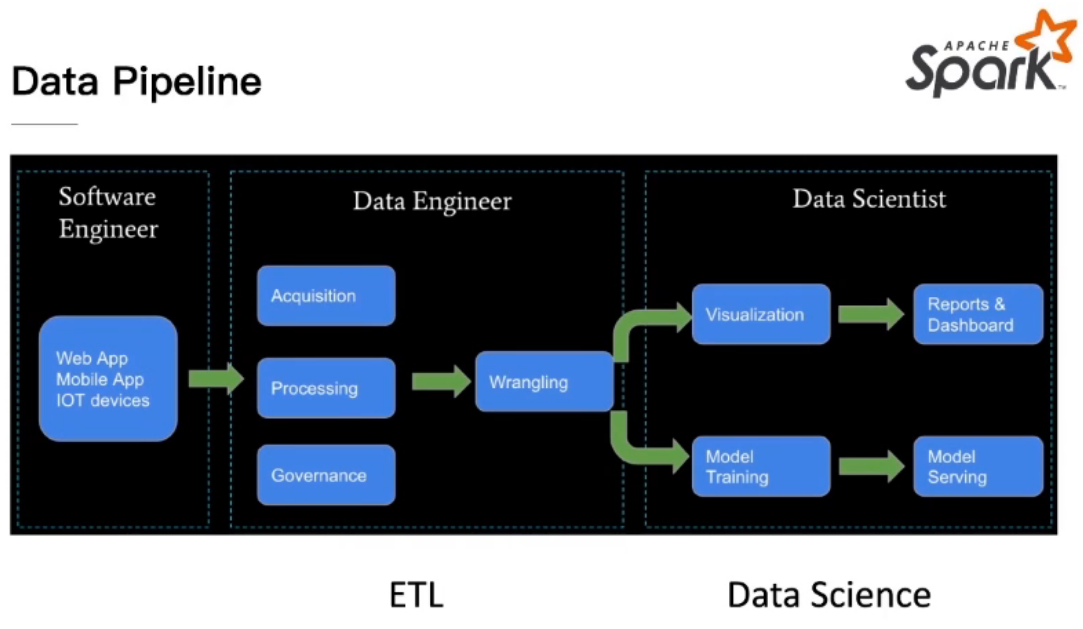
How to do ETL in Spark
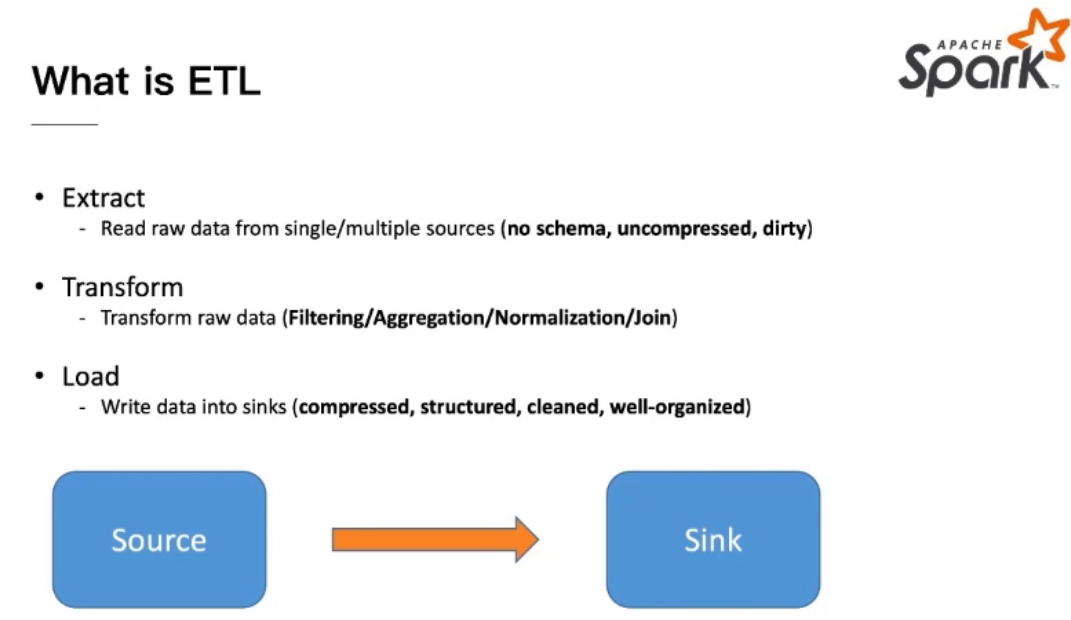
**E: Extract -> **Read raw data from single/multiple sources (no schema, uncompressed,dirty) 数据清洗 格式化
T: Transform -> Transform raw data (Filtering/Aggregation/Normalization/Join) 过滤 聚合 标准化 联立
**L: Load -> **Write data into sinks (compressed, structured,cleaned, well-organized) 加载数据至下游组件



遇到脏数据的三种模式:
permissive:把有问题的记录保存下来,存到另外一个字段去
dropmalformed:直接ignore
dailfast:出错直接fail任务

ETL时需要注意的问题,对于上游数据、硬件和网络,操作者是没有控制权的
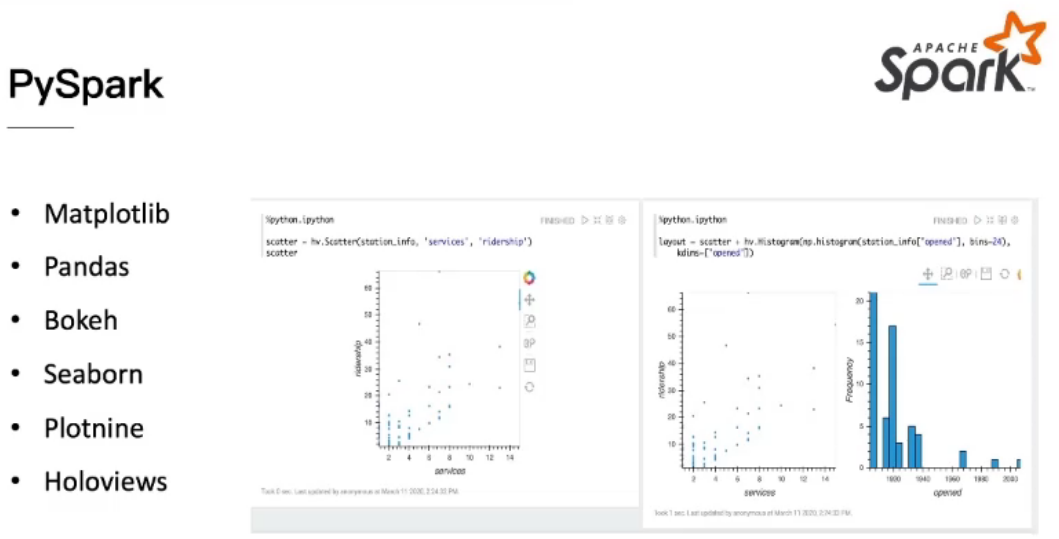
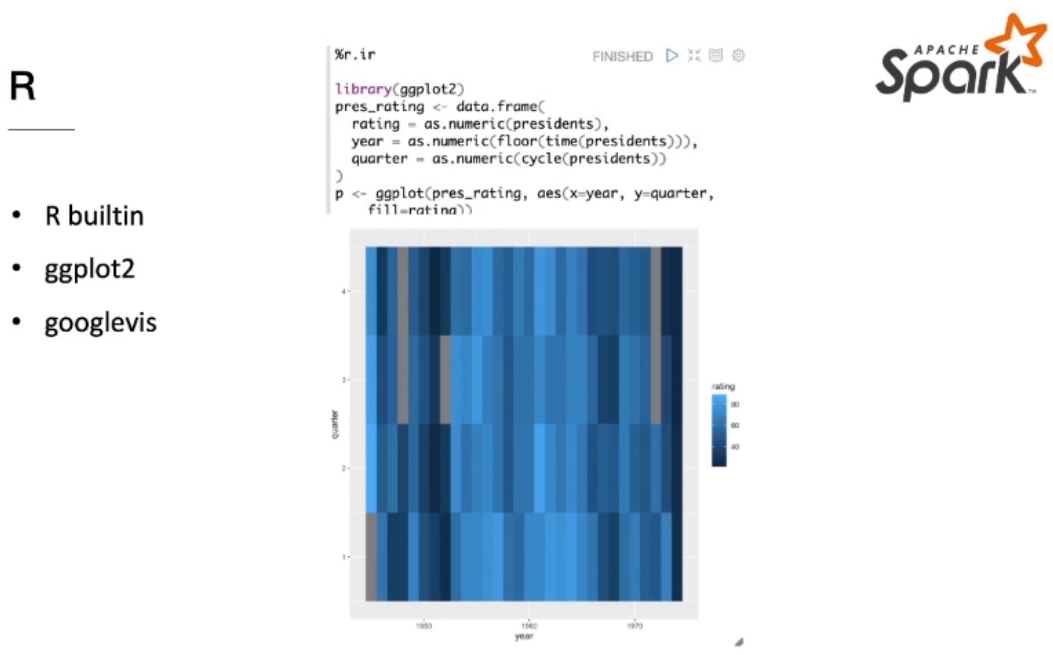
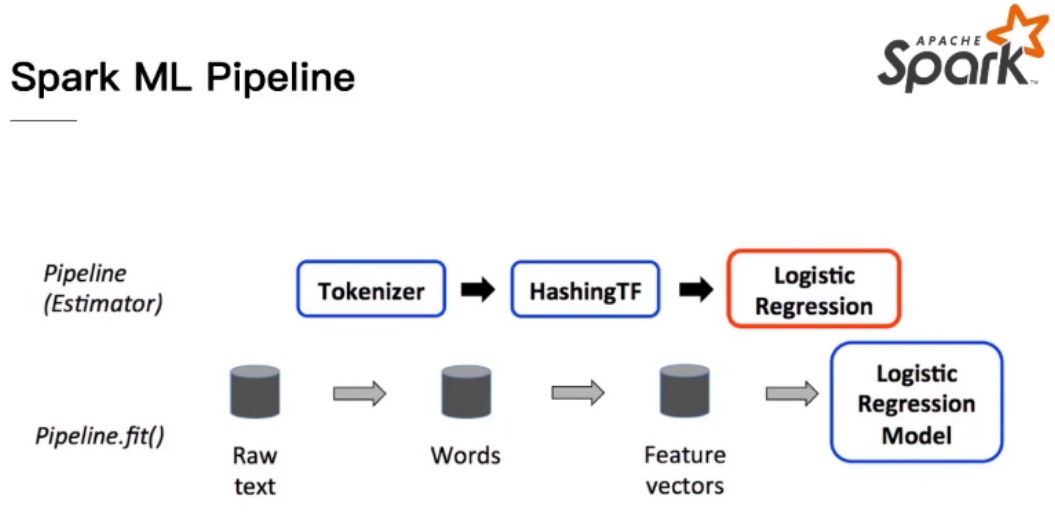
How to do Data Science in Spark
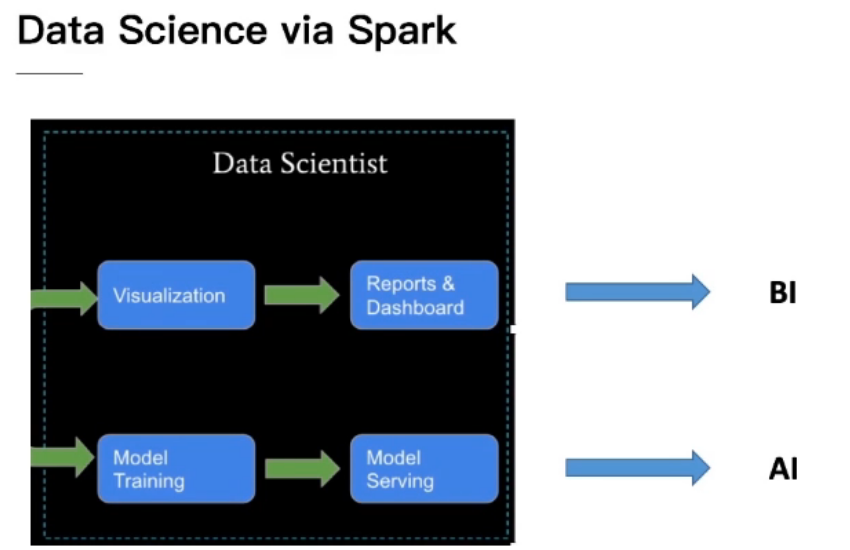
BI发现问题,AI解决问题



三种机器学习类型:
监督学习(分类、regression)
无监督学习(有数据但是没有label,例如文本聚类)
强化学习(根据外界反应不断学习迭代,例如alphago)
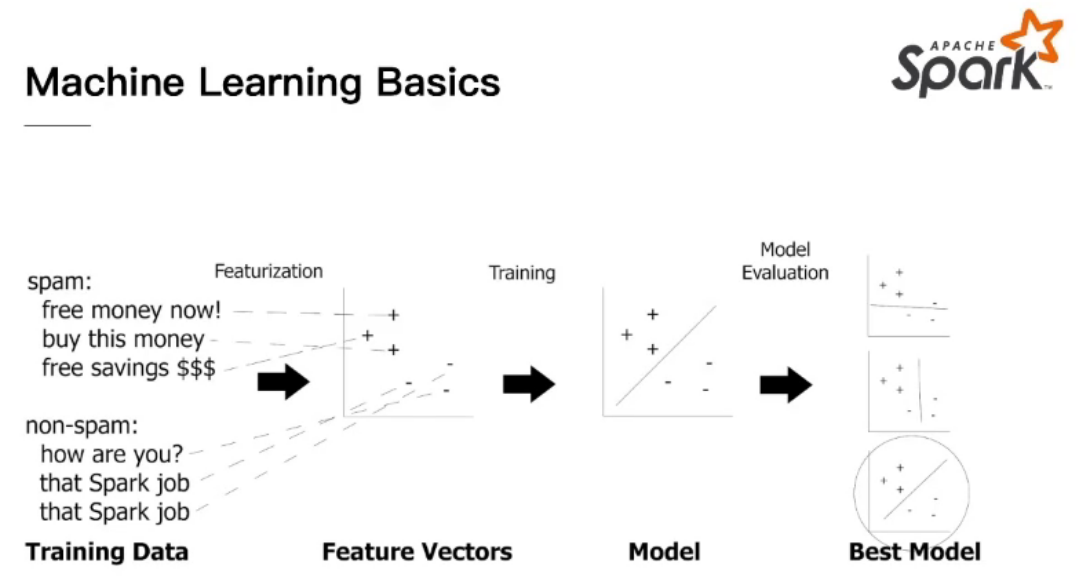
经典流程(以监督型为例):
准备train data
转化为特征向量feature vectors
训练模型
调参应用
QA
与tensorflow/pytorch等深度学习框架以及sklearn包等相比,sparkML有什么优势
Spark 是为一般的数据处理设计的,并不特定于机器学习。但是使用 MLlib for Spark,也可以在 Spark 上进行机器学习
这个zeppelin 写代码和在idea中写有什么差别,能打jar之类吗?
zepplein会帮你打jar,提交spark代码,你不用手动搞

 浙公网安备 33010602011771号
浙公网安备 33010602011771号