kaggle-Corporación Favorita Grocery Sales Forecasting
https://blog.csdn.net/bitcs_zt/article/details/79256688
该项比赛1月15日就已经结赛了,但由于之后进入期末,备考花费了大量的时间,没来得及整理相关内容。现在终于有时间好好回顾比赛,并对这次比赛的过程进行记录。
Corporación Favorita Grocery Sales Forecasting
本次比赛是预测商品销量,给出的训练数据为<单位销量,日期,商店ID,商品ID,推销活动标签>,其中单位销量是待预测值,基本上属于回归问题。同时给出的额外数据表有:
- “商店信息表”—<商店ID,所在城市,所在州,类型,聚类簇>
- “商品表”—<商品ID,所属类别,所属子类别,易腐烂标签>
- “交易信息表”—<商店ID,日期,总交易笔数>
- “石油价格”—<日期、石油价格>
- “节假日信息”
值得注意的是,同一商品可能在不同的商店均有销售,而最后的测试数据为<日期,商店ID,商品ID,推销活动标签>,我们需要预测的是某商品在指定商店在某天的销量。训练数据给出了从2013年-2017年8月15日近一千余天的数据条目,每一天都包含各类商品在各个商店的数据条路,而很多商品只在某一些时间阶段出现过。测试数据需要预测的是2017年8月16日—31日销量情况。这就使得数据的组织十分重要。
和以前比赛一样,我还是在比赛过半左右的时间参与的比赛,这个时间参加,基本上forum已经有了解决该题的大方向,不至于跑偏。由于还要兼顾课业,从最开始慢慢实验测试是不太可能了,这也是kaggle比赛比较友好的地方,forum在比赛的各个时段都会有kaggler的集思广益,使得我们这类以学习为目的的人能用最小的成本学到最多的东西。
切入点
如上所述,如何组织数据至关重要。刚参赛时,我在做了简单的EDA后,发现数据并无特别的规律,原始训练数据如下(数据量巨大,只取了2017年的):
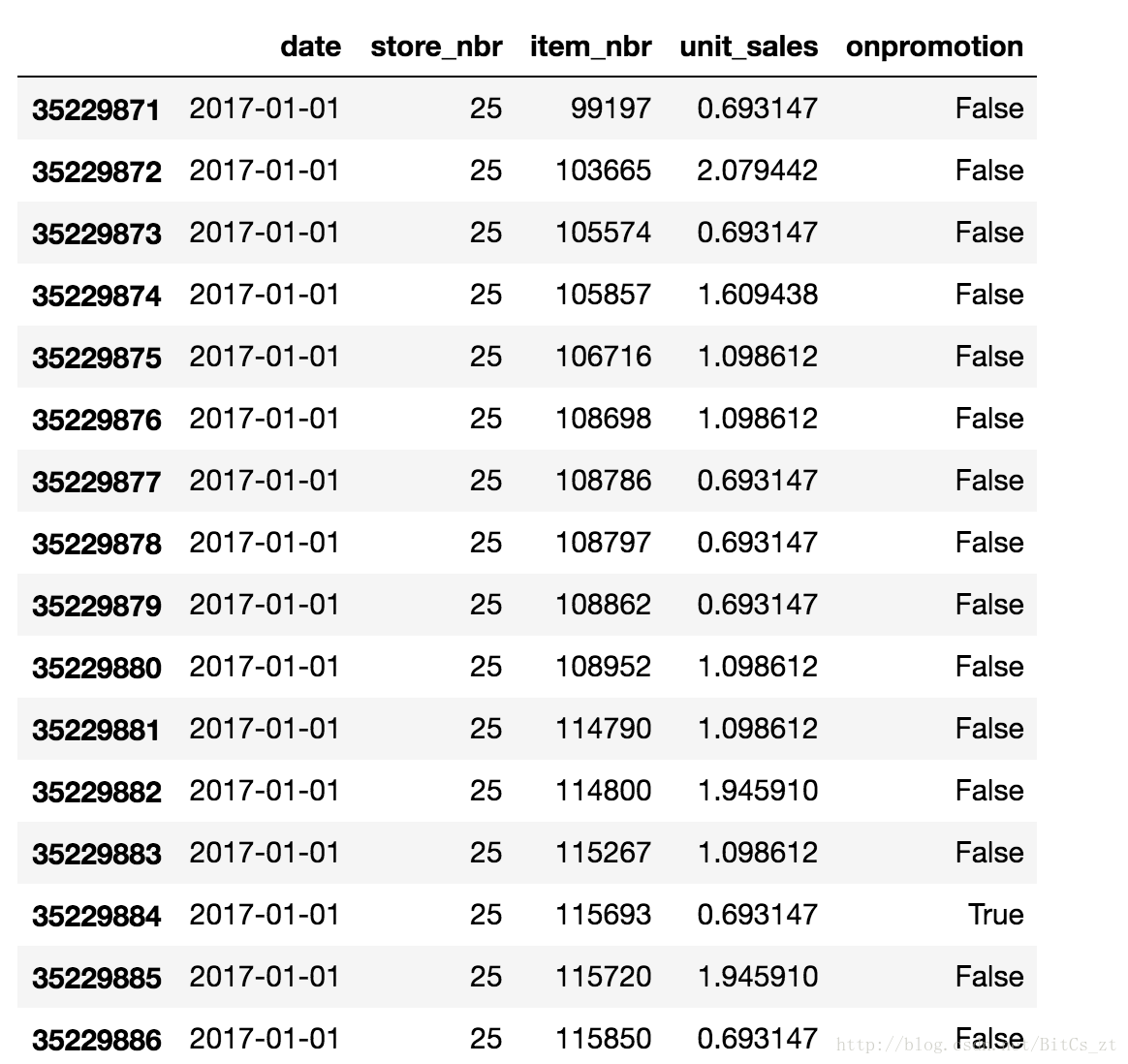
可以看到,在如上这种数据组织方式下,难以“下手”,特征数目太少不可能直接用模型训练,且其中的日期、ID等特征都不是数值型数据。思考几日后,在forum上发现了一个帖子Ceshine Lee-LGBM Starter
,将数据按<商店ID、商品ID、日期>三级索引形式重新组织,得到数据表如下:
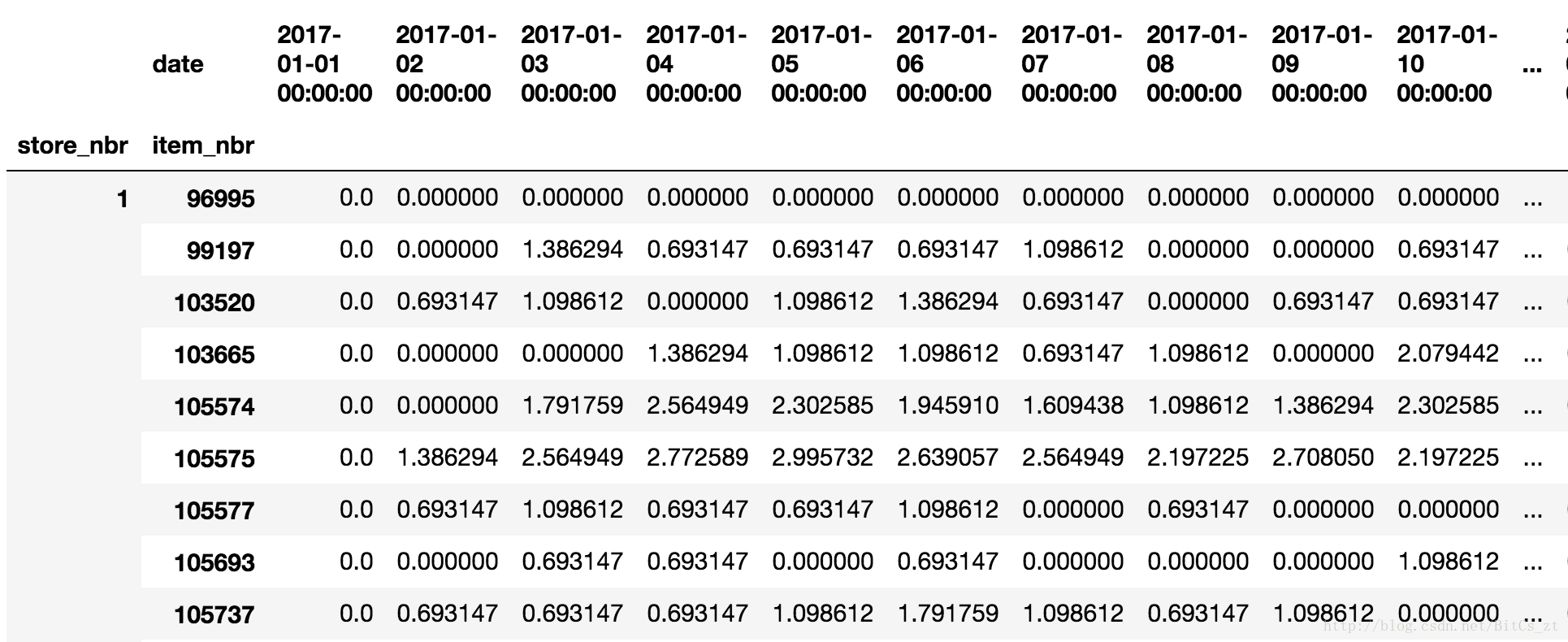
此时每个数据条目便有了真实意义——某商店的某商品在一段时间内的销量。如此将该问题转变为了类似“股票价格预测”的问题,这与我们的最终目标“预测某商店的某商品在2017年8月16日-31日的销量”也能对应上。该文还做出了其他一些尝试:抽取了销量均值作为特征来训练LGBM,针对16日-31日的每一天分别训练模型进行预测,选取与16日-31日有相同周期的(16日为周三)作为训练数据。最后排名靠前的选手基本都参照了该文的思想。
分析
利用机器学习来解决实际问题,关键无外乎四点,对应到本题有如下分析:
- data。1、观察原始数据,并进行适当的变换,使得数据适用于机器学习模型。在本题中,原始数据的呈现形式并不直观,数据条目之间是独立的,特征数量不够且不是数值型。将其转化成为销量序列后,自然而然地成为了一个时序预测问题,这个领域是我们较为熟悉的。2、组织训练集和验证集。本题需要预测共16日的销量,因此训练集和验证集的标签也要是16日,这不免在时间段上带来重叠,合理利用更多日期的信息显然会对最后结果有帮助。
- feature。有了数据后,应考虑如何组织成为特征,将其变为适合模型的训练数据。在本题中,每一数据条目为某商店某商品数百日内每天的销量,我们显然不能将其全部运用到模型中,一来数据量过于庞大,二来会引入许多噪声(如许多商品在一长段时间内都没有销量)。日均销量就是一个很好的特征,既能压缩特征数量,也能一定程度上降噪。我们应该考虑还能构造哪些feature,能很好的表示数据同时又不丢失太多信息。
- model。选取什么样的模型来解决这个问题比较合适?针对时间序列问题,第一想法是RNN,深层RNN抗噪声和表示能力极强,但原始数据对应下每个timestamp只有1天的销量,feature还需要自己构造。而且每个数据条目的scale很不一样,调参成本应该会很高;第二想法是决策树模型,树模型解决问题的逻辑是归类,把类似的商品(同一商店、不同商店的同一商品、同一类别的商品等)归在一起,其本质是“强平均”,即通过决策树归类相似的商品,再作平均。这种方法不能直接使用销量序列,需要人为构造有意义的特征;但由于树模型有XGBoost和LGBM的高效实现,参数意义也较为明显,试错成本会比NN低。
- ensemble。模型融合是比赛进行到最后必不可少的一步,简单的可以多个模型结果做bagging,复杂的可以用第一层模型结果来训练第二层模型。在kaggle比赛中bagging是很tricky的,一定要有着好的cv做辅助,否则极容易过拟合。
data、feature、model、ensemble四个部分不可能严格意义上串行工作,有可能选用了model后发现不合适,更换model的同时数据可能也需要重新整理。这需要我们建立良好的pipeline,减少反复调整带来的额外工作量,并记录好重要步骤作log。
Data
先将原始数据转变为销量序列。由于时间相关序列在训练集和验证集的组织上需要严格根据时间决定,给出2017年5-8月日历如下:

可以看到,待预测日为16-31共计16日,要注意到以周三为起点这一周期信息,并且要最大化地利用信息。由于之前做EDA,单个商品没有反映出长期的周期性,故可以认为,训练集越接近待预测日,整合越多的信息,越能准确预测。比如选择7.26-8.9的每个商品的价格作为训练集标签,7.26之前的价格数据抽取feature作训练集,这段时间是符合周期分布(周三开始、周四结束)下时间上最接近测试集的16日,将其称为一个batch。考虑获取多个batch形成训练集,可以选取7.5-7.20、7.12-7.27、7.26-8.9三个batch,即间隔一周或若干周选取一个batch,保持了周期性。虽然batch之间可能有一定的重复性,但这是必要的。一来使数据量增多,模型不容易过拟合,二来针对某个商品,我们有了若干个数据条目(一个条目即为上图中某个商店的某个商品在一段时间内的销量),无论是使用树模型还是NN,这都能使模型更加robust。
实验中batch为6-15不等,batch之间间隔试了1、2、4周。使用7.26-8.9做validation set,在比赛后期,利用带validation set来确定模型训练轮数R(validation set上准确率确定是否结束训练),再将validation set的数据加入到training set,这样我们可以利用更靠近8.16的数据,实际上也这样做也确实带来了准确率的提升。
Feature
针对某一batch,比如7.26-8.9,根据商品价格序列抽取如下特征:
- 前10,20,…,100天(指7.26之前,下同)的均销量-mean_{}
- 前3,7,14,21,28,…,100天参与推销活动的次数和-promo_{}
- 前7,14,28,56,84,112,140天销量为0的天数和-zero_{}
- 前7,14,28,56,96,140天的最高销量-max_{}
- 最近一周每天的销量-day_{}
- 过去四个月每个月的销量-mean_month_{}
- 近一段时间周x的均销量-mean_week_{}
- 前14,28,42,56,70,84,100,120天销量不为0天数的均销量-sale_mean_{}
- 前14,28,42,56,70,84,100,120天销量不为0天数的销量方差-std-{}
- 待预测16天每天是否参与推销活动-promo_future_{}
由于在比赛过程中常想到新的特征,加入特征又需要重新实验,耗时耗力。故在比赛之初,就应该尽量把特征工程做好,同时建好pipeline,以减小增删特征重复试验带来的精力损耗。同时要结合树模型所产生的feature importance判断特征好坏。Data和Feature的实验在比赛早期要尽可能做完善,虽然不可能尽善尽美,一定要建好pipeline,血的教训!!!比赛进行到后期时,model和ensemble也要做实验时,在jupyter里写代码的弊端就体现出来了,往往上下翻阅很久。良好的pipeline会让功能架构清晰很多。
Model
其实刚看到时间序列模型是想用RNN的,找了forum里面一个LSTM网络跑了一下,笔记本跑了一晚上,成本太高了,就放弃了。主要还是使用的树模型。这次尝试了LGBM,据说是比XGBoost快,这次时间紧,也就没做对比。总的来说还是挺好用的,速度也很快。由于比赛过程中,除了模型调参还要调整data和feature,所以最终跑出来的单个模型也没有表现特别好的。而且在比赛后期由于提交次数限制,很多模型调参只是根据本地cv判别了优劣,而这次比赛的本地cv和提交结果不是完全同步提升的,可能错过了一些潜在的好模型,这也是以后要注意的。对于LGBM的调参还是太稚嫩了,只能说多经历多学习吧。
还使用了CatBoost,据说对类别型数据支持较好,但应该是我还不太了解一些参数的意义,只是简单地做了一些设置,最终该模型表现效果不如LGBM,且速度比较慢。
比赛初始还尝试用auto encoder,效果不理想就放弃了。花费时间成本也比较高。理论上来说直接调参RNN是更好的选择,上次比赛优胜选手使用了该模型,自己也想试试。也算尝试了一下吧。
Ensemble
时间缘故,也没有时间做两层的ensemble了,只是将结果进行了简单的加权bagging。最终参与bagging的模型有7个LGBM+1个CatBoost+1个Median-based。最后放榜的成绩只有小数点后三位,有很多简单的bagging和单个模型与最终提交的bagging是一样的成绩,也无法得知孰优孰劣,本着bagging模型多样性的原则,还是选择了一个较多模型的bagging。
结赛后,也看了forum上很多排名靠前选手给出的解决办法。很多使用了NN based的方法,不过多数都来自于之前一些时间序列比赛的经验,也说明了经验对于神经网络的设计构建是多么的重要。不过让人欣慰的是排名第1的选手给出的得分最高的模型是LGBM,结合了很好的特征工程。让我这种现阶段没有DNN实验条件的人有了很多希冀。
总结下从这个比赛学到的东西:
- 时间序列的问题转化
- 基于日期的训练集、验证集分割和选取(周期特征,batch的获得,如何利用更多数据)
- 特征工程(时序统计特征)
- CV(验证集的设置)
- LGBM的调参
- 不同预处理、特征工程、batch设置下的ensemble
- CatBoost、LSTM的简单使用
待提高之处:
- pipeline的建设!!!(一定早点设计,省去后面实验的大麻烦,尤其是在jupyter下编程)
- 特征工程(规范地结合feature importance来筛选特征,不同类型特征分批实验)
- CV和LB的同步规律(即如何通过设置、分析本地CV来提高模型最终效果)
- LGBM的调参(自动化调参,减少调参精力)
- 神经网络模型的使用(希望早点具备实验条件)
- 合理把握比赛时间和节奏,及时“止损”(比赛后期花了很多时间调参却没有太大进展,收获效率低)
- …
给出赛后排名靠前选手的解决方案汇总:
Top Solutions
以上是这次比赛我自己方面的一些总结,一分耕耘一分收获吧。最后40/1675的成绩,获了一枚银牌,心里也很开心。以后还是多打比赛,多写代码,多看forum,多学东西。
但做好事,不问前程。
--------------------- 本文来自 ZSYGOOOD 的CSDN 博客 ,全文地址请点击:https://blog.csdn.net/bitcs_zt/article/details/79256688?utm_source=copy

 浙公网安备 33010602011771号
浙公网安备 33010602011771号