对Attention is all you need 的理解
https://blog.csdn.net/mijiaoxiaosan/article/details/73251443
本文参考的原始论文地址:https://arxiv.org/abs/1706.03762
谷歌昨天在arxiv发了一篇论文名字教Attention Is All You Need,提出了一个只基于attention的结构来处理序列模型相关的问题,比如机器翻译。传统的神经机器翻译大都是利用RNN或者CNN来作为encoder-decoder的模型基础,而谷歌最新的只基于Attention的Transformer模型摒弃了固有的定式,并没有用任何CNN或者RNN的结构。该模型可以高度并行地工作,所以在提升翻译性能的同时训练速度也特别快。
以下是谷歌Transformer的结构示意图。

模型分为编码器和解码器两个部分,编码器由6个相同的层堆叠在一起,每一层又有两个支层。第一个支层是一个多头的自注意机制,第二个支层是一个简单的全连接前馈网络。在两个支层外面都添加了一个residual的连接,然后进行了layer nomalization的操作。模型所有的支层以及embedding层的输出维度都是dmodel=512dmodel=512. 模型的解码器也是堆叠了六个相同的层。不过每层除了编码器中那两个支层,解码器还加入了第三个支层,如图中所示同样也用了residual以及layer normalization。具体的细节后面再讲。
论文是从attention结构开始介绍Transformer的,这里为了方便,从模型的输入开始介绍。
模型输入。
编码器和解码器的输入就是利用学习好的embeddings将tokens(一般应该是词或者字符)转化为dmodeldmodel 维向量。对解码器来说,利用线性变换以及softmax函数将解码的输出转化为一个预测下一个token的概率。
位置编码。
由于模型没有任何循环或者卷积,为了使用序列的顺序信息,需要将tokens的相对以及绝对位置信息注入到模型中去。论文在输入embeddings的基础上加了一个“位置编码”。位置编码和embeddings由同样的维度都是dmodeldmodel 所以两者可以直接相加。有很多位置编码的选择,既有学习到的也有固定不变的。本文中用了正弦和余弦函数进行编码。
这里的pos是位置,i是维度。
下面介绍我对本文最重要的一部分注意力模型的理解。
论文首先给attentioin进行了一个定义。attention函数可以看作将一个query和一系列key-value对映射为一个输出(output)的过程。这里的query,keys,values以及output都是向量。输出是由带权的values加起来得到的,而每个value的权重是根据query和相应的key通过一个函数计算出来的。
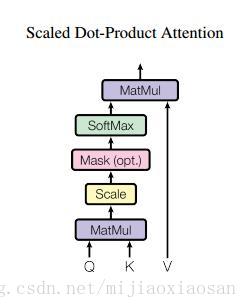
scaled 的点乘attention
论文中用的attention是基本的点乘的方式,就是多了一个所谓的scale。输入包括维度为dkdk 的queries以及keys,还有维度为dvdv 的values。计算query和所有keys的点乘,然后每个都除以dk‾‾√dk(这个操作就是所谓的Scaled)。之后利用一个softmax函数来获取values的权重。
实际操作中,attention函数是在一些列queries上同时进行的,将这些queries并在一起形成一个矩阵QQ 同时keys以及values也并在一起形成了矩阵KK 以及VV 。则attention的输出矩阵可以按照下述公式计算:
文中还讨论了点乘和additive attention的区别,additive的attention用了一个单层的前馈网络,理论上二者的复杂度是差不多的,但是实际上点乘更快而且空间上更有效率,因为点乘可以利用高度优化了的矩阵乘法代码来实现。
当dkdk 比较小时,两个机制的效果几乎差不多,而在dkdk 比较大的时候,additive的attention效果比没有scale操作的点乘attention效果好。作者怀疑这是因为the dot products growing too large in magnitude to result in useful gradients after applying the softmax function(不知道怎么翻译好),所以作者用了scale这个操作来规模化点乘。
下图为作者scale 点乘attention的结构图。
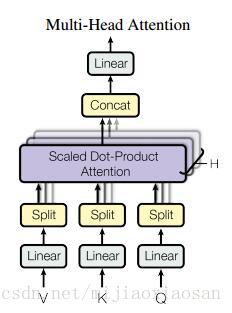
多头的attention (Multi-Head Attention)
这个应该是本文最核心的部分。本文结构中的Attention并不是简简单单将一个点乘的attention应用进去。作者发现先对queries,keys以及values进行hh 次不同的线性映射效果特别好。学习到的线性映射分别映射到dkdk , dkdk 以及dvdv 维。分别对每一个映射之后的得到的queries,keys以及values进行attention函数的并行操作,生成dvdv 维的output值。具体操作细节如以下公式。
这里映射的参数矩阵,WiQ∈ℝdmodel∗dkWiQ∈Rdmodel∗dk ,WiK∈ℝdmodel∗dkWiK∈Rdmodel∗dk ,WiV∈ℝdmodel∗dvWiV∈Rdmodel∗dv。
本文中对并行的attention层(或者成为头)使用了h=8h=8 的设定。其中每层都设置为dk=dv=dmodel/h=64dk=dv=dmodel/h=64. 由于每个头都减少了维度,所以总的计算代价和在所有维度下单头的attention是差不多的。
把这些attention头的output拼接起来作为最终值,就像下图中multihead attention结构示意图所描述的一样。
在本模型中如何使用attention
本文提出的模型Transformer以三种不同的方式使用了多头attention。
1. 在encoder-decoder的attention层,queries来自于之前的decoder层,而keys和values都来自于encoder的输出。这个类似于很多已经提出的seq-to-seq模型所使用的attention机制。
2. 在encoder含有self-attention层。在一个self-attention层中,所有的keys, values以及queries都来自于同一个地方,本例中即encoder之前一层的的输出。
3. 类似的,decoder中的self-attention层也是一样。不同的是在scaled点乘attention操作中加了一个mask的操作(设置为负无穷),这个操作是保证softmax操作之后不会将非法的values连到attention中(个人理解,比如你这一位置queryattention的values不能有这一位置之后的values的信息,只能有该位置前面的values,本人菜鸟欢迎拍砖)。
之前说模型由堆叠在一起的六个层组成,每层由两个支层,attention层就是其中一个,而attention之后的另一个支层就是一个前馈的网络。公式描述如下。
该网络是两个线性变换,中间加了一个ReLU激活函数。每个位置(position)上的线性变换是一样的,但是不同层与层的参数是不一样的。该网络的输入和输出维度都是dmodeldmodel ,不过中间层的维度是2048.
模型的整体框架基本介绍完了,其最重要的创新应该就是Self-Attention的使用级联的多头attention架构。
作者在文中深入讨论了为什么选择使用self attention这一结构。主要从三个方面来谈。第一是每层的总计算复杂性,其次是能并行计算的数量,这点论文用所要求的序列操作的最小值来量化。第三点是针对网络长距离依赖的路径长度。为了提升在长序列上的计算性能,self-attention应该改被限制(restrict)在一个size大小为rr 的邻域内,这样可以将最大路径长度增加到O(n/r)O(n/r) ,至于具体如何去做作者说在未来工作中会研究。

上图为self attention结构与cnn以及rnn的性能比较,可以看出self attention还是具有优势的。
论文中的东西就说这么多了,下面说我的感想。
自我感觉谷歌这次放大招了,完全抛弃了CNN以及RNN这几年做神经机器翻译的固有思维,仅用了attention来对句子进行编码和解码。从论文后面的附图可以看出该模型已经在很大程度上“理解”了句子的意思。也许过一段时间,各种层叠attention及其变种的模型就会满天飞了,但谷歌无疑开了这样一个好头,就是我们不必对固有的模型抱有很深的执念,尝试各种可能也许会有意想不到的效果。不过话说回来,谁知道这个模型是失败了多少次之后才有的成功呢?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号