强化学习之Q-learning简介
https://blog.csdn.net/Young_Gy/article/details/73485518
强化学习在alphago中大放异彩,本文将简要介绍强化学习的一种q-learning。先从最简单的q-table下手,然后针对state过多的问题引入q-network,最后通过两个例子加深对q-learning的理解。
强化学习
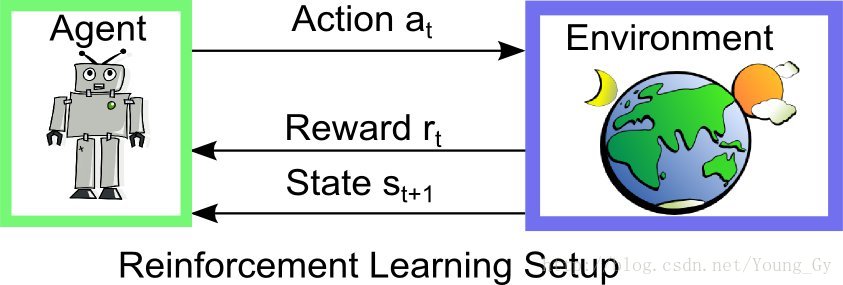
强化学习通常包括两个实体agent和environment。两个实体的交互如下,在environment的statestst下,agent采取actionatat进而得到rewardrtrt 并进入statest+1st+1。
强化学习的问题,通常有如下特点:
- 不同的action产生不同的reward
- reward有延迟性
- 对某个action的reward是基于当前的state的
Q-learning
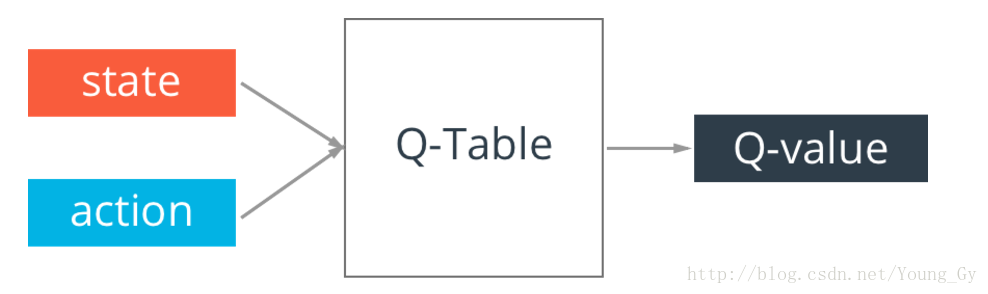
Q-Table
Q-learning的核心是Q-table。Q-table的行和列分别表示state和action的值,Q-table的值Q(s,a)Q(s,a)衡量当前states采取actiona到底有多好。
Bellman Equation
在训练的过程中,我们使用Bellman Equation去更新Q-table。
Bellman Equation解释如下:Q(s,a)Q(s,a)表示成当前ss采取aa后的即时rr,加上折价γγ后的最大reward max(Q(s′,a′)max(Q(s′,a′)。
算法
根据Bellman Equation,学习的最终目的是得到Q-table,算法如下:
- 外循环模拟次数num_episodes
- 内循环每次模拟最大步数num_steps
- 根据当前的state和q-table选择action(可加入随机性)
- 根据当前的state和action获得下一步的state和reward
- 更新q-table: Q[s,a] = Q[s,a] + lr*(r + y*np.max(Q[s1,:]) - Q[s,a])
实例
以FrozenLake为例,代码如下:
# import lib
import gym
import numpy as np
# Load the environment
env = gym.make('FrozenLake-v0')
# Implement Q-Table learning algorithm
#Initialize table with all zeros
Q = np.zeros([env.observation_space.n,env.action_space.n])
# Set learning parameters
lr = .8
y = .95
num_episodes = 2000
#create lists to contain total rewards and steps per episode
#jList = []
rList = []
for i in range(num_episodes):
#Reset environment and get first new observation
s = env.reset()
rAll = 0
d = False
j = 0
#The Q-Table learning algorithm
while j < 99:
j+=1
#Choose an action by greedily (with noise) picking from Q table
a = np.argmax(Q[s,:] + np.random.randn(1,env.action_space.n)*(1./(i+1)))
#Get new state and reward from environment
s1,r,d,_ = env.step(a)
#Update Q-Table with new knowledge
Q[s,a] = Q[s,a] + lr*(r + y*np.max(Q[s1,:]) - Q[s,a])
rAll += r
s = s1
if d == True:
break
#jList.append(j)
rList.append(rAll)
print "Score over time: " + str(sum(rList)/num_episodes)
print "Final Q-Table Values"
print Q- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
Deep-Q-learning
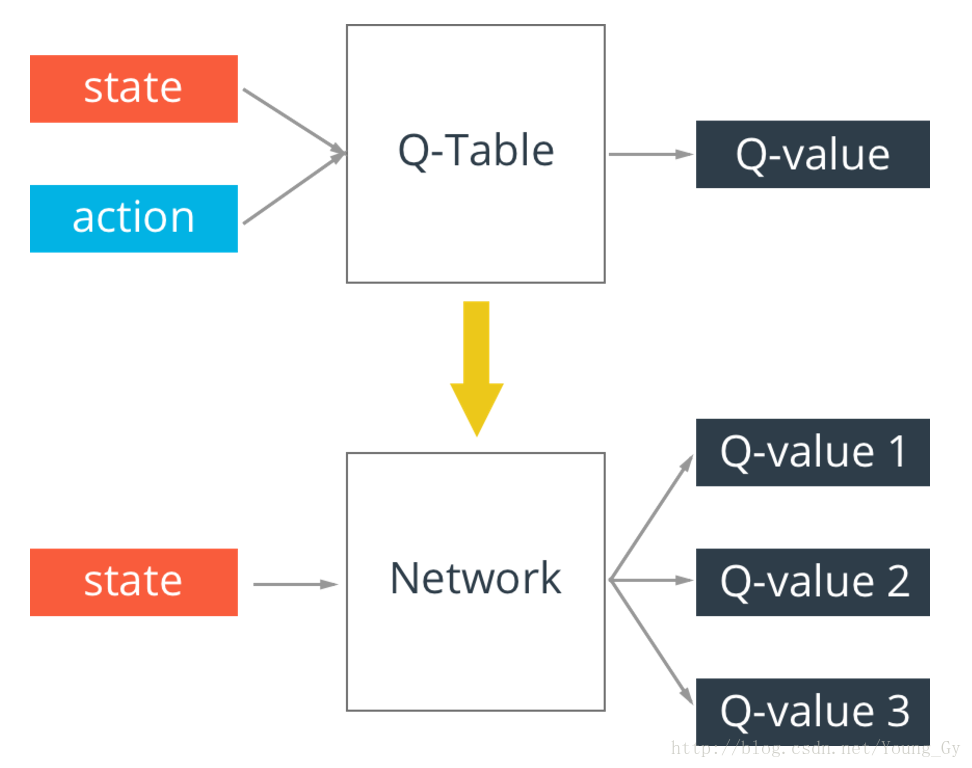
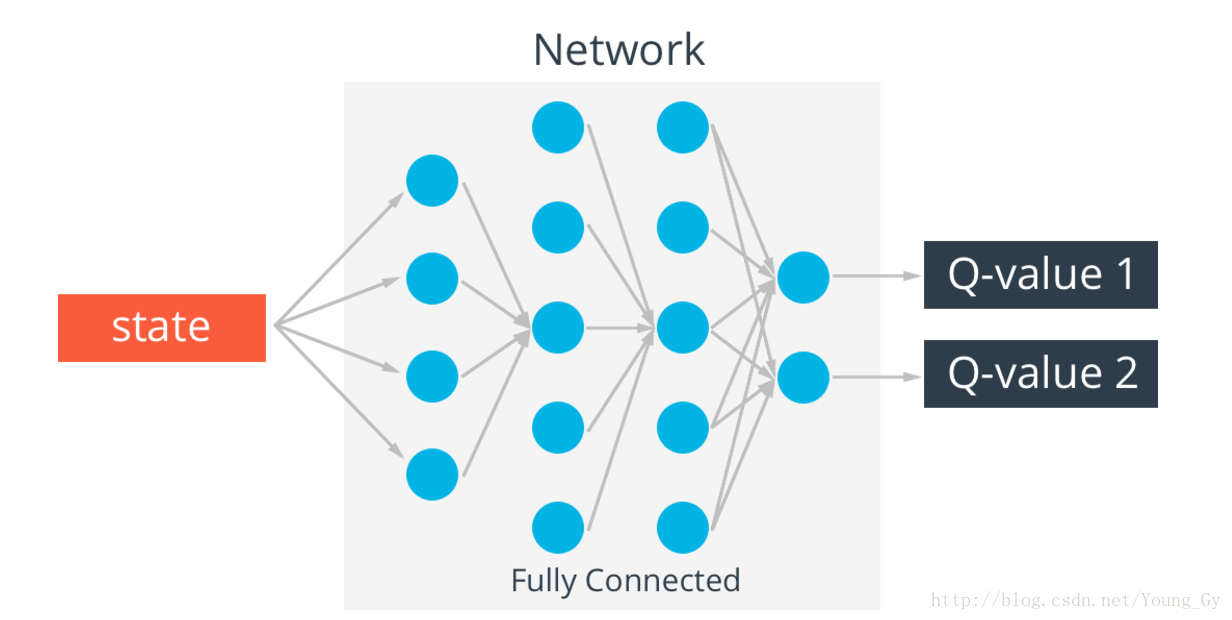
q-table存在一个问题,真实情况的state可能无穷多,这样q-table就会无限大,解决这个问题的办法是通过神经网络实现q-table。输入state,输出不同action的q-value。
Experience replay
强化学习由于state之间的相关性存在稳定性的问题,解决的办法是在训练的时候存储当前训练的状态到记忆体MM,更新参数的时候随机从MM中抽样mini-batch进行更新。
具体地,MM中存储的数据类型为 <s,a,r,s′><s,a,r,s′>,MM有最大长度的限制,以保证更新采用的数据都是最近的数据。
Exploration - Exploitation
- Exploration:在刚开始训练的时候,为了能够看到更多可能的情况,需要对action加入一定的随机性。
- Exploitation:随着训练的加深,逐渐降低随机性,也就是降低随机action出现的概率。
算法

实例
CartPole
# import lib
import gym
import tensorflow as tf
import numpy as np
# Create the Cart-Pole game environment
env = gym.make('CartPole-v0')
# Q-network
class QNetwork:
def __init__(self, learning_rate=0.01, state_size=4,
action_size=2, hidden_size=10,
name='QNetwork'):
# state inputs to the Q-network
with tf.variable_scope(name):
self.inputs_ = tf.placeholder(tf.float32, [None, state_size], name='inputs')
# One hot encode the actions to later choose the Q-value for the action
self.actions_ = tf.placeholder(tf.int32, [None], name='actions')
one_hot_actions = tf.one_hot(self.actions_, action_size)
# Target Q values for training
self.targetQs_ = tf.placeholder(tf.float32, [None], name='target')
# ReLU hidden layers
self.fc1 = tf.contrib.layers.fully_connected(self.inputs_, hidden_size)
self.fc2 = tf.contrib.layers.fully_connected(self.fc1, hidden_size)
# Linear output layer
self.output = tf.contrib.layers.fully_connected(self.fc2, action_size,
activation_fn=None)
### Train with loss (targetQ - Q)^2
# output has length 2, for two actions. This next line chooses
# one value from output (per row) according to the one-hot encoded actions.
self.Q = tf.reduce_sum(tf.multiply(self.output, one_hot_actions), axis=1)
self.loss = tf.reduce_mean(tf.square(self.targetQs_ - self.Q))
self.opt = tf.train.AdamOptimizer(learning_rate).minimize(self.loss)
# Experience replay
from collections import deque
class Memory():
def __init__(self, max_size = 1000):
self.buffer = deque(maxlen=max_size)
def add(self, experience):
self.buffer.append(experience)
def sample(self, batch_size):
idx = np.random.choice(np.arange(len(self.buffer)),
size=batch_size,
replace=False)
return [self.buffer[ii] for ii in idx]
# hyperparameters
train_episodes = 1000 # max number of episodes to learn from
max_steps = 200 # max steps in an episode
gamma = 0.99 # future reward discount
# Exploration parameters
explore_start = 1.0 # exploration probability at start
explore_stop = 0.01 # minimum exploration probability
decay_rate = 0.0001 # exponential decay rate for exploration prob
# Network parameters
hidden_size = 64 # number of units in each Q-network hidden layer
learning_rate = 0.0001 # Q-network learning rate
# Memory parameters
memory_size = 10000 # memory capacity
batch_size = 20 # experience mini-batch size
pretrain_length = batch_size # number experiences to pretrain the memory
tf.reset_default_graph()
mainQN = QNetwork(name='main', hidden_size=hidden_size, learning_rate=learning_rate)
# Populate the experience memory
# Initialize the simulation
env.reset()
# Take one random step to get the pole and cart moving
state, reward, done, _ = env.step(env.action_space.sample())
memory = Memory(max_size=memory_size)
# Make a bunch of random actions and store the experiences
for ii in range(pretrain_length):
# Uncomment the line below to watch the simulation
# env.render()
# Make a random action
action = env.action_space.sample()
next_state, reward, done, _ = env.step(action)
if done:
# The simulation fails so no next state
next_state = np.zeros(state.shape)
# Add experience to memory
memory.add((state, action, reward, next_state))
# Start new episode
env.reset()
# Take one random step to get the pole and cart moving
state, reward, done, _ = env.step(env.action_space.sample())
else:
# Add experience to memory
memory.add((state, action, reward, next_state))
state = next_state
# Training
# Now train with experiences
saver = tf.train.Saver()
rewards_list = []
with tf.Session() as sess:
# Initialize variables
sess.run(tf.global_variables_initializer())
step = 0
for ep in range(1, train_episodes):
total_reward = 0
t = 0
while t < max_steps:
step += 1
# Uncomment this next line to watch the training
env.render()
# Explore or Exploit
explore_p = explore_stop + (explore_start - explore_stop)*np.exp(-decay_rate*step)
if explore_p > np.random.rand():
# Make a random action
action = env.action_space.sample()
else:
# Get action from Q-network
feed = {mainQN.inputs_: state.reshape((1, *state.shape))}
Qs = sess.run(mainQN.output, feed_dict=feed)
action = np.argmax(Qs)
# Take action, get new state and reward
next_state, reward, done, _ = env.step(action)
total_reward += reward
if done:
# the episode ends so no next state
next_state = np.zeros(state.shape)
t = max_steps
print('Episode: {}'.format(ep),
'Total reward: {}'.format(total_reward),
'Training loss: {:.4f}'.format(loss),
'Explore P: {:.4f}'.format(explore_p))
rewards_list.append((ep, total_reward))
# Add experience to memory
memory.add((state, action, reward, next_state))
# Start new episode
env.reset()
# Take one random step to get the pole and cart moving
state, reward, done, _ = env.step(env.action_space.sample())
else:
# Add experience to memory
memory.add((state, action, reward, next_state))
state = next_state
t += 1
# Sample mini-batch from memory
batch = memory.sample(batch_size)
states = np.array([each[0] for each in batch])
actions = np.array([each[1] for each in batch])
rewards = np.array([each[2] for each in batch])
next_states = np.array([each[3] for each in batch])
# Train network
target_Qs = sess.run(mainQN.output, feed_dict={mainQN.inputs_: next_states})
# Set target_Qs to 0 for states where episode ends
episode_ends = (next_states == np.zeros(states[0].shape)).all(axis=1)
target_Qs[episode_ends] = (0, 0)
targets = rewards + gamma * np.max(target_Qs, axis=1)
loss, _ = sess.run([mainQN.loss, mainQN.opt],
feed_dict={mainQN.inputs_: states,
mainQN.targetQs_: targets,
mainQN.actions_: actions})
saver.save(sess, "checkpoints/cartpole.ckpt")
# Testing
test_episodes = 10
test_max_steps = 400
env.reset()
with tf.Session() as sess:
saver.restore(sess, tf.train.latest_checkpoint('checkpoints'))
for ep in range(1, test_episodes):
t = 0
while t < test_max_steps:
env.render()
# Get action from Q-network
feed = {mainQN.inputs_: state.reshape((1, *state.shape))}
Qs = sess.run(mainQN.output, feed_dict=feed)
action = np.argmax(Qs)
# Take action, get new state and reward
next_state, reward, done, _ = env.step(action)
if done:
t = test_max_steps
env.reset()
# Take one random step to get the pole and cart moving
state, reward, done, _ = env.step(env.action_space.sample())
else:
state = next_state
t += 1
env.close()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
FrozenLake
# import lib
import gym
import numpy as np
import random
import tensorflow as tf
import matplotlib.pyplot as plt
%matplotlib inline
# laod env
env = gym.make('FrozenLake-v0')
# The Q-Network Approach
tf.reset_default_graph()
#These lines establish the feed-forward part of the network used to choose actions
inputs1 = tf.placeholder(shape=[1,16],dtype=tf.float32)
W = tf.Variable(tf.random_uniform([16,4],0,0.01))
Qout = tf.matmul(inputs1,W)
predict = tf.argmax(Qout,1)
#Below we obtain the loss by taking the sum of squares difference between the target and prediction Q values.
nextQ = tf.placeholder(shape=[1,4],dtype=tf.float32)
loss = tf.reduce_sum(tf.square(nextQ - Qout))
trainer = tf.train.GradientDescentOptimizer(learning_rate=0.1)
updateModel = trainer.minimize(loss)
# Training
init = tf.initialize_all_variables()
# Set learning parameters
y = .99
e = 0.1
num_episodes = 2000
#create lists to contain total rewards and steps per episode
jList = []
rList = []
with tf.Session() as sess:
sess.run(init)
for i in range(num_episodes):
#Reset environment and get first new observation
s = env.reset()
rAll = 0
d = False
j = 0
#The Q-Network
while j < 99:
j+=1
#Choose an action by greedily (with e chance of random action) from the Q-network
a,allQ = sess.run([predict,Qout],feed_dict={inputs1:np.identity(16)[s:s+1]})
if np.random.rand(1) < e:
a[0] = env.action_space.sample()
#Get new state and reward from environment
s1,r,d,_ = env.step(a[0])
#Obtain the Q' values by feeding the new state through our network
Q1 = sess.run(Qout,feed_dict={inputs1:np.identity(16)[s1:s1+1]})
#Obtain maxQ' and set our target value for chosen action.
maxQ1 = np.max(Q1)
targetQ = allQ
targetQ[0,a[0]] = r + y*maxQ1
#Train our network using target and predicted Q values
_,W1 = sess.run([updateModel,W],feed_dict={inputs1:np.identity(16)[s:s+1],nextQ:targetQ})
rAll += r
s = s1
if d == True:
#Reduce chance of random action as we train the model.
e = 1./((i/50) + 10)
break
jList.append(j)
rList.append(rAll)
print "Percent of succesful episodes: " + str(sum(rList)/num_episodes) + "%"
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
参考资料
- Simple Reinforcement Learning with Tensorflow Part 0: Q-Learning with Tables and Neural Networks
- Udacity Deep Learning Nano Degree

 浙公网安备 33010602011771号
浙公网安备 33010602011771号