AAAI 2018 论文 | 蚂蚁金服公开最新基于笔画的中文词向量算法
导读:词向量算法是自然语言处理领域的基础算法,在序列标注、问答系统和机器翻译等诸多任务中都发挥了重要作用。词向量算法最早由谷歌在2013年提出的word2vec,在接下来的几年里,该算法也经历不断的改进,但大多是仅适用于拉丁字符构成的单词(比如英文),结合中文语言特性的词向量研究相对较少。本文介绍了蚂蚁金服人工智能部与新加坡科技大学一项最新的合作成果:cw2vec——基于汉字笔画信息的中文词向量算法研究,用科学的方法揭示隐藏在一笔一划之间的秘密。

作者:曹绍升 陆巍 周俊 李小龙
AAAI大会(Association for the Advancement of Artificial Intelligence),是一年一度在人工智能方向的顶级会议之一,旨在汇集世界各地的人工智能理论和领域应用的最新成果。该会议固定在每年的2月份举行,由AAAI协会主办。
第32届AAAI大会-AAAI 2018将于2月2号-7号在美国新奥尔良召开,其中蚂蚁金服人工智能部和新加坡科技大学合作的一篇基于汉字笔画信息的中文词向量算法研究的论文“cw2vec: Learning Chinese Word Embeddings with Stroke n-grams”被高分录用(其中一位审稿人给出了满分,剩下两位也给出了接近满分的评价)。我们将在2月7日在大会上做口头报告(Oral),欢迎大家一起讨论交流。
单个英文字符(character)是不具备语义的,而中文汉字往往具有很强的语义信息。不同于前人的工作,我们提出了“n元笔画”的概念。所谓“n元笔画”,即就是中文词语(或汉字)连续的n个笔画构成的语义结构。

▲图1 n元笔画生成的例子
如上图,n元笔画的生成共有四个步骤。比如说,“大人”这个词语,可以拆开为两个汉字“大”和“人”,然后将这两个汉字拆分成笔画,再将笔画映射到数字编号,进而利用窗口滑动产生n元笔画。其中,n是一个范围,在上述例子中,我们将n取值为3, 4和5。
在论文中我们提出了一种基于n元笔画的新型的损失函数,如下:

其中,W和C分别为当前词语和上下文词语,σ是sigmoid函数,T(w)是当前词语划窗内的所有词语集合,D是训练语料的全部文本。为了避免传统softmax带来的巨大计算量,这篇论文也采用了负采样的方式。C'为随机选取的词语,称为“负样例”,λ是负样例的个数,而则表示负样例C'按照词频分布进行的采样,其中语料中出现次数越多的词语越容易被采样到。相似性sim(·,·)函数被按照如下构造:

其中,

为当前词语对应的一个n元笔画向量,而

是其对应的上下文词语的词向量。这项技术将当前词语拆解为其对应的n元笔画,但保留每一个上下文词语不进行拆解。S(w)为词语w所对应的n元笔画的集合。在算法执行前,这项研究先扫描每一个词语,生成n元笔画集合,针对每一个n元笔画,都有对应的一个n元笔画向量,在算法开始之前做随机初始化,其向量维度和词向量的维度相同。
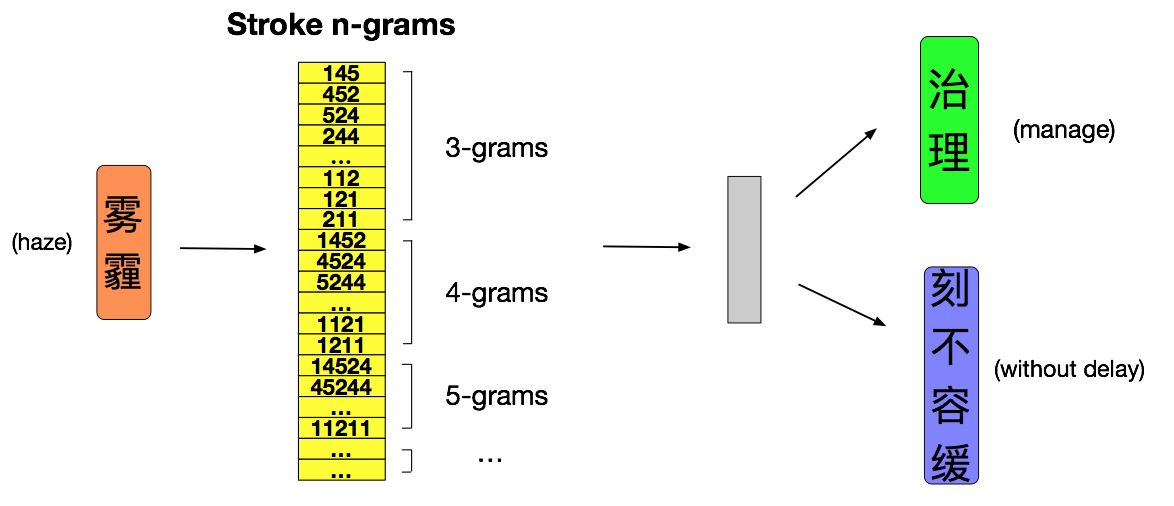
▲图2 算法过程的举例
如上图所示,对于“治理 雾霾 刻不容缓”这句话,假设此刻当前词语恰好是“雾霾”,上下文词语是“治理”和“刻不容缓”。首先将当前词语“雾霾”拆解成n元笔画并映射成数字编码,然后划窗得到所有的n元笔画,根据设计的损失函数,计算每一个n元笔画和上下文词语的相似度,进而根据损失函数求梯度并对上下文词向量和n元笔画向量进行更新。
为了验证这项研究提出的cw2vec算法的效果,在公开数据集上,与业界最优的几个词向量算法做了对比:

▲图3 实验结果
上图中包括2013年谷歌提出的word2vec的两个模型skipgram和cbow,2014年斯坦福提出的GloVe算法,2015年清华大学提出的基于汉字的CWE模型,以及2017年最新发表的基于像素和偏旁的中文词向量算法,可以看出cw2vec在word similarity,word analogy,以及文本分类和命名实体识别的任务中均取得了一致性的提升。同时,这篇文章也展示了不同词向量维度下的实验效果:
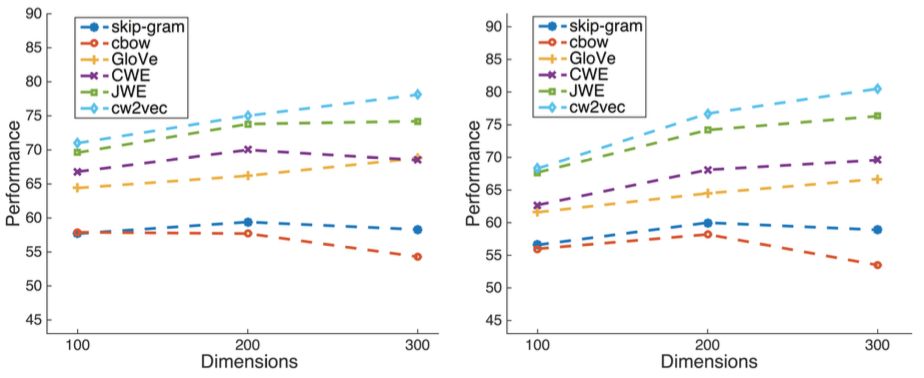
▲图4 不同词向量维度下的实验结果
上图为不同维度下在word analogy测试集上的实验结果,左侧为3cosadd,右侧为3cosmul的测试方法。可以看出这项算法在不同维度的设置下均取得了不错的效果。此外,也在小规模语料上进行了测试:
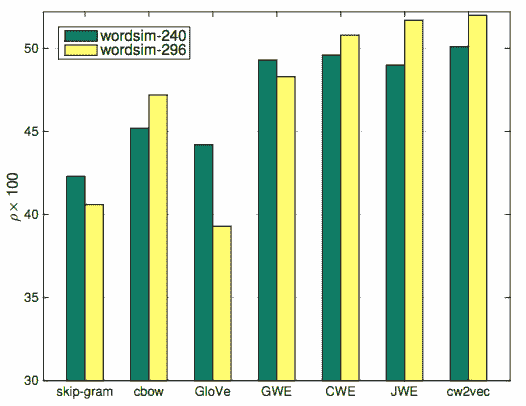
▲图5 小训练数据下的实验结果
上图是仅选取20%中文维基百科训练语料,在word similarity下测试的结果,skipgram, cbow和GloVe算法由于没有利用中文的特性信息进行加强,所以在小语料上表现较差,而其余四个算法取得了不错的效果,其中cw2vec的算法在两个数据集上均取得的了最优效果。
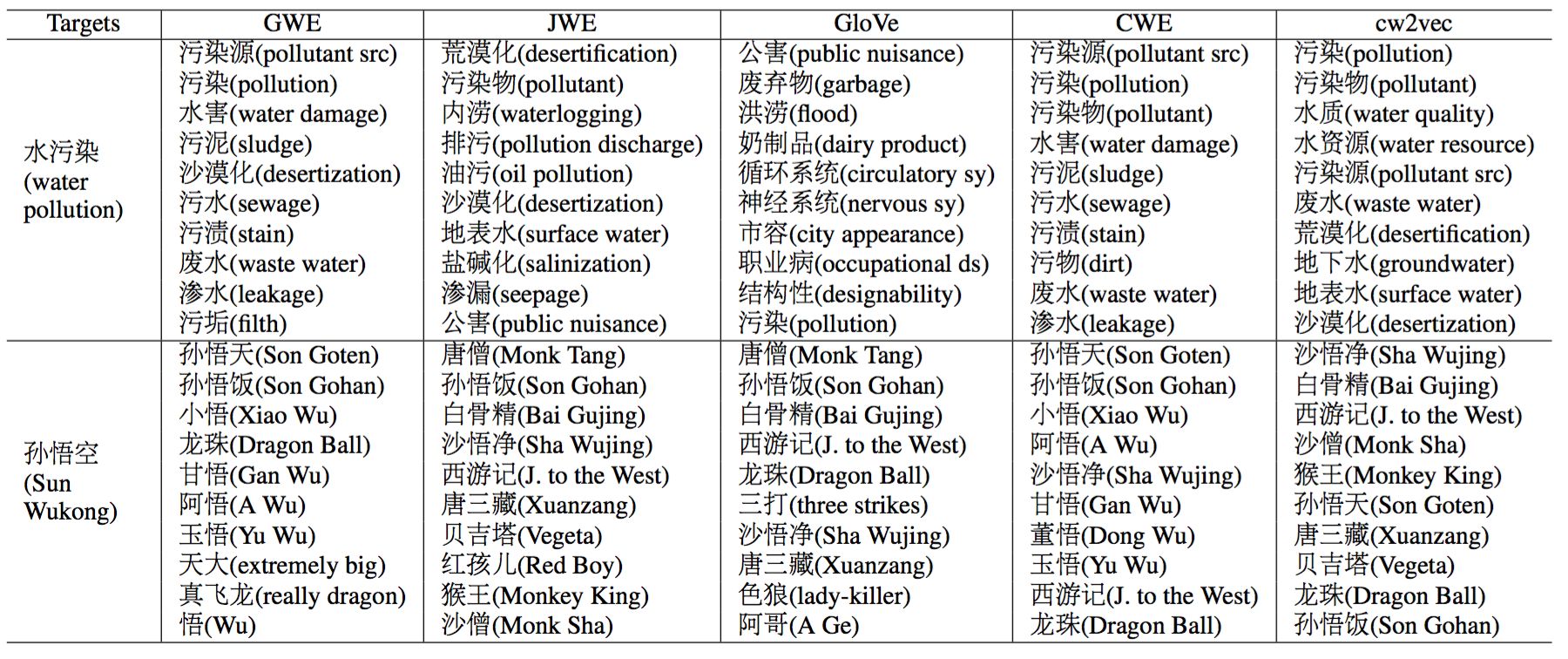
▲图6 案例分析结果
为了更好的探究不同算法的实际效果,这项研究专门选取了两个词语做案例分析。第一个是环境相关的“水污染”,然后根据词向量利用向量夹角余弦找到与其语义最接近的词语。GWE找到了一些和“污”字相关的词语,比如“污泥”,“污渍”和“污垢”,而JWE则更加强调后两个字“污染”GloVe找到了一些奇怪的相近词语,比如“循环系统”,“神经系统”。CWE找到的相近词语均包含“水”和“污”这两个字,猜测是由于其利用汉字信息直接进行词向量加强的原因。此外,只有cw2vec找到了“水质”这个相关词语,分析认为是由于n元笔画和上下文信息对词向量共同作用的结果。第二个例子,特别选择了“孙悟空”这个词语,该角色出现在中国的名著《西游记》和知名日本动漫《七龙珠》中,cw2vec找到的均为相关的角色或著作名称。
作为一项基础研究成果,cw2vec在蚂蚁和阿里的诸多场景上也有落地。在智能客服、文本风控和推荐等实际场景中均发挥了作用。此外,不单单是中文词向量,对于日文、韩文等其他语言也进行类似的尝试,相关的发明技术专利已经申请近二十项。
我们希望能够在基础研究上追赶学术界、有所建树,更重要的是,在具体的实际场景之中,能够把人工智能技术真正的赋能到产品里,为用户提供更好的服务。
福利-论文下载链接:
https://github.com/ShelsonCao/cw2vec/blob/master/cw2vec.pdf(请将网址复制至浏览器打开,或点击阅读原文)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号