LSTM 文本情感分析/序列分类 Keras
LSTM 文本情感分析/序列分类 Keras
请参考 http://spaces.ac.cn/archives/3414/
neg.xls是这样的

pos=pd.read_excel(‘pos.xls’,header=None,index=None) #读取训练语料完毕
pos[‘mark’]=1
neg[‘mark’]=0 #给训练语料贴上标签
pn=pd.concat([pos,neg],ignore_index=True) #合并语料
neglen=len(neg)
poslen=len(pos) #计算语料数目
cw = lambda x: list(jieba.cut(x)) #定义分词函数
pn[‘words’] = pn[0].apply(cw)
comment = pd.read_excel(‘sum.xls’) #读入评论内容
#comment = pd.read_csv(‘a.csv’, encoding=’utf-8′)
comment = comment[comment[‘rateContent’].notnull()] #仅读取非空评论
comment[‘words’] = comment[‘rateContent’].apply(cw) #评论分词
d2v_train = pd.concat([pn[‘words’], comment[‘words’]], ignore_index = True)
w = [] #将所有词语整合在一起
for i in d2v_train:
w.extend(i)
dict = pd.DataFrame(pd.Series(w).value_counts()) #统计词的出现次数
del w,d2v_train
dict[‘id’]=list(range(1,len(dict)+1))
get_sent = lambda x: list(dict[‘id’][x])
pn[‘sent’] = pn[‘words’].apply(get_sent)
maxlen = 50
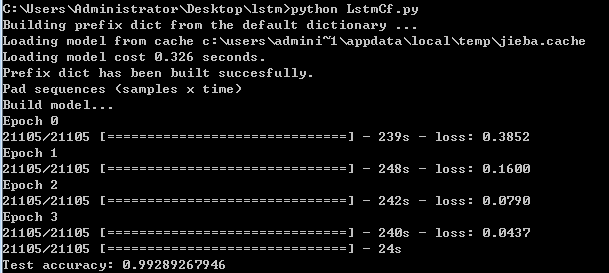
print “Pad sequences (samples x time)”
pn[‘sent’] = list(sequence.pad_sequences(pn[‘sent’], maxlen=maxlen))
x = np.array(list(pn[‘sent’]))[::2] #训练集
y = np.array(list(pn[‘mark’]))[::2]
xt = np.array(list(pn[‘sent’]))[1::2] #测试集
yt = np.array(list(pn[‘mark’]))[1::2]
xa = np.array(list(pn[‘sent’])) #全集
ya = np.array(list(pn[‘mark’]))
print ‘Build model…’
model = Sequential()
model.add(Embedding(len(dict)+1, 256))
model.add(LSTM(256, 128)) # try using a GRU instead, for fun
model.add(Dropout(0.5))
model.add(Dense(128, 1))
model.add(Activation(‘sigmoid’))
model.compile(loss=’binary_crossentropy’, optimizer=’adam’, class_mode=”binary”)
print ‘Fit model…’
model.fit(xa, ya, batch_size=32, nb_epoch=4) #训练时间为若干个小时
classes = model.predict_classes(xa)
acc = np_utils.accuracy(classes, ya)
print ‘Test accuracy:’, acc
可以试一试
w = [] #将所有词语整合在一起
for i in d2v_train:
w.extend(i)
newList = list(set(w))
print “newlist len is”
print len(newList)
dict = pd.DataFrame(pd.Series(w).value_counts()) #统计词的出现次数
print type(dict)
print len(dict)
可以发现print len(newList)结果和print len(dict) 也就是说dict的长度就是所有不重复词语的distinct的长度。
主要有一个这个函数 sequence.pad_sequences
https://keras.io/preprocessing/sequence/#pad_sequences
http://www.360doc.com/content/16/0714/10/1317564_575385964.shtml
 如果指定了参数maxlen,比如这里maxlen为50,那么意思就是这里每句话只截50个单词,后面就不要了,如果一句话不足50个单词,则用0补齐。
如果指定了参数maxlen,比如这里maxlen为50,那么意思就是这里每句话只截50个单词,后面就不要了,如果一句话不足50个单词,则用0补齐。首先,Word2Vec 将词语对应一个多维向量,
model.add(Embedding(len(dict)+1, 256))
参数参考 http://www.360doc.com/content/16/0714/09/1317564_575385061.shtml
http://blog.csdn.net/niuwei22007/article/details/49406355
然后
model.add(LSTM(256, 128)) # try using a GRU instead, for fun
model.add(Dropout(0.5))
model.add(Dense(128, 1))
model.add(Activation(‘sigmoid’))
整个流程对应下图

再看一看keras自带的例子:imdb_lstm
maxlen = 100
print(“Pad sequences (samples x time)”)
X_train = sequence.pad_sequences(X_train, maxlen=maxlen)
X_test = sequence.pad_sequences(X_test, maxlen=maxlen)
print(‘X_train shape:’, X_train.shape)
print(‘X_test shape:’, X_test.shape)
print(‘Build model…’)
model = Sequential()
model.add(Embedding(max_features, 128))
model.add(LSTM(128, 128)) # try using a GRU instead, for fun
model.add(Dropout(0.5))
model.add(Dense(128, 1))
model.add(Activation(‘sigmoid’))
同样的道理
如果训练样本较少,为了防止模型过拟合,Dropout可以作为一种trikc供选择。在每个训练批次中,通过忽略一半的特征检测器(让一半的隐层节点值为0),可以明显地减少过拟合现象。这种方式可以减少特征检测器间的相互作用,检测器相互作用是指某些检测器依赖其他检测器才能发挥作用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号