
网络爬虫-url索引
网络爬虫-url索引
http://www.cnblogs.com/yuandong/archive/2008/08/28/Web_Spider_Url_Index.html
url索引的作用是判断一个url是否被抓取过,采用的算法主要是MD5数字签名。
假设一共要抓取的url不超过1亿条,用一个二进制的位表示一个url是否被抓取过,则至少需要1亿个位,我们管每一个位叫一个“槽”。考虑到MD5的算法是可能出现冲突(即不同的url算出来的MD5可能相同,这种概率很小),槽越少,冲突越明显,所以槽越多越好。但另一方面,还要考虑到占用内存的大小,因为在抓取的过程中,为了保证效率,所有的槽都需要载入内存。目前我使用的是2的28次方,即32M,相当于268435456(2.6亿)个槽。
当要判断一个url是否已经抓取过的时候,只要判断该url经过MD5签名后的值所对应的槽是否标记为1即可。例如给出的url是:http://www.ouc.edu.cn/,经过128位的MD5签名后,得出的1073542761,则需要判断的就是第1073542761个槽是0还是1。同样的道理,当完成一个url的抓取后,要将对应的槽标记为1。
存储槽的32M空间在内存是不连续的,因为操作系统很难划分出32M的连续内存空间,所以将其分为4096个段Segment,每段2048个32位整数,32*2048*4096=268435456。相当于一个整型的二维数组。
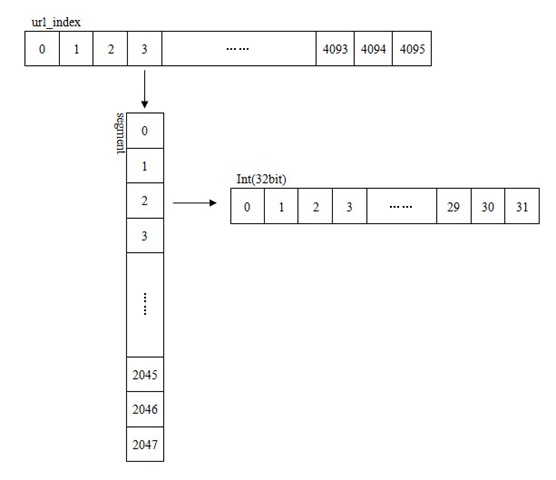
我们使用32位的MD5作为签名,表示为一个整数。这个整数分为三部分,分别是段地址、段偏移和值地址。第5-16位表示段地址,17-27位表示段偏移,28-32位(最后5位,取值范围为2的5次方,即0-31)表示在整形值中的位置、即值地址。

当给定一个url的MD5值时,通过以下函数计算出其段地址:
1: unsigned short get_segment_index(unsigned int md5) {
2:
3: //5-16位表示段地址
4:
5: unsigned short result;
6: bzero(&result, sizeof(unsigned short));
7: memcpy(&result, ((char*)&md5) + 2, sizeof(unsigned short));
8:
9: return result & 0x0FFF;
10: }
通过以下函数计算出其段偏移:
1: unsigned short get_segment_offset(unsigned int md5) {
2:
3: //17-27位表示段偏移
4:
5: unsigned short result;
6: bzero(&result, sizeof(unsigned short));
7: memcpy(&result, ((char*)&md5), sizeof(unsigned short));
8:
9: return result >> 5;
10: }
通过以下函数计算其值偏移:
1: unsigned int get_value(unsigned int md5) {
2:
3: //28-32(最后5位)为表示值
4:
5: unsigned int result = 1;
6: return result << (md5 & 0x0000001F);
7: }
再得到段地址、段偏移和值偏移后,就通过一下函数判定该Url是否已被抓取:
1: bool is_url_crawled(char* url) {
2:
3: //将给出的url进行md5运算,取得对应的Value,于储存的Value按位与
4:
5: unsigned int url_md5 = md5(url);
6: unsigned short segment_index = get_segment_index(url_md5);
7: unsigned short segment_offset = get_segment_offset(url_md5);
8: unsigned int value = get_value(url_md5);
9:
10: unsigned int result = (unsigned int)
(url_index[segment_index][segment_offset] & value);
11:
12: return result > 0 ? TRUE : FALSE;
13: }
如果未被抓取,在完成抓取后,通过以下函数标记为已抓取:
1: int mark_url_as_crawled(char* url) {
2:
3: //取得段地址、段偏移和url对应的值
4: unsigned int url_md5 = md5(url);
5: unsigned short segment_index = get_segment_index(url_md5);
6: unsigned short segment_offset = get_segment_offset(url_md5);
7: unsigned int value = get_value(url_md5);
8:
9: //通过按位或标记url对应的位为已抓取
10: url_index[segment_index][segment_offset] |= value;
11:
12: //同步写入索引文件
13: value = url_index[segment_index][segment_offset];
14: long offset = (((long)segment_index) * SEGMENT_LENGTH + segment_offset)
* sizeof(unsigned int);
15: if(fseek(index_file, offset, SEEK_SET) != 0)
16: return -1;
17:
18: if(fwrite(&value, sizeof(unsigned int), 1, index_file) != 1)
19: return -1;
20:
21: fflush(index_file);
22: return 0;
23: }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号