

XPath & XSL
XML是一个完整的树状结构文档,从根节点到子节点一层一层往下。这有点类似于操作系统的文件的管理,从根目录到子目录,一层一层往下也形成树状结构(或许和Linux或是Unix相比较更相似一些,因为他们只定义了一个根目录,并没有很清晰的分区的概念,而Windows则出现了分区的概念,所以只能用一个盘里的目录结构来比较,不过其实也是可以在Windows的所有分区上层抽象出一个父节点作为根节点,这样,这种比较就更加直观了!)。正如我们需要在不同的目录中跳转以取得需要的文件和目录信息,所以有cd、dir(ls)等命令。在XML中,也需要在不同的节点跳转以获取节点的信息,并做一些查询工作,这样就诞生了XPath技术。XPath是XML Path Language的缩写,它一种专门用来在XML文档中查询信息的语言。有人将XPath比作数据库中的SQL语句,也有人将XQuery比作数据库中的SQL语言,我没有具体的看过XQuery和XPath有什么的区别,不过XQuery是基于XPath的,因此获取这两种比喻都是可以成立的,我不完整的理解是XQuery只是对XPath的一种封装,就像现在出现的很多新技术其实并不能谈上什么新技术,这些所谓的新技术只是对传统的旧的技术的方法框架的总结,然后用自己的方式去套一层框架,以自己的一套实现方式使编程变得更加的简单,美之名曰:新技术。这正是应了中国的一句俗语:换汤不换药。
什么是XPath?w3school.com.cn给出的解释是:
· XPath 使用路径表达式在 XML 文档中进行导航
· XPath 包含一个标准函数库
· XPath 是 XSLT 中的主要元素
· XPath 是一个 W
个人感觉用第一句话就可以给出了XPath的本质意义了。XPath就是在XML文档中导航的技术,它借用了路径表达式的技术,所以取名为Path。XPath是一种非常有用的技术,它实现了在XML文档的不同节点之间的导航,因而其他涉及到对XML文档节点处理的技术一般都会用到XPath技术,比如XSL、XPointer、XQuery等技术。
XPath数据类型

对boolean函数的参数:
如果为数值型,且数值为0或是NaN,返回true,否则false。
如果是空节点集合,返回true,否则为false。
如果是空片段,返回true,否则为false。
如果是是字符型,且字符长度为0,返回true,否则false。
布尔表达式有:
=、<(<)、>(>)、<=(<=)、>=(>=)。
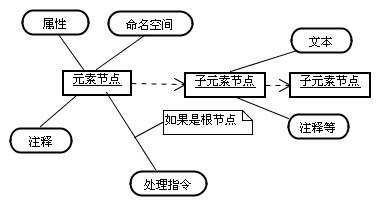
XPath的7种节点类型

其实这些节点核心都是围绕元素节点。如下图:
XPath表达式
说了那么多,现在应该是切入主题的时候了。XPath在XML文档中的导航主要是通过表达式和函数来实现的。一个表达式返回的结果可以是一个单独的节点、一组节点、一个布尔值、一个浮点数或是一个字符串。如在以下的XML文档中:
<?xml version="1.0" encoding="ISO-8859-1"?>
<bookstore>
<book>
<title lang="en">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
</bookstore>
/bookstore/book 表示选择元素book。
注:XPath表达式不能在文档中定位XML声明(因为XML声明不是XML文档结构的一部分)。它也不能定位嵌入的DTD声明或是CDATA块。
定位节点
XPath表达式中主要用两个符号来表达节点的定位:
“/” 当前“目录”下的元素节点,它是一种绝对路径的表达方式,因而要从根目录开始。
如果是 ”/” 则表示选取根节点。
“//” 当前“目录”下的所有相应的元素节点。它是一种相对路径的表达方式,会搜索当前路
径下的所有相应的元素。如 ”//book” 表示在当前文档下的所有含book元素的节点。
另外可以用 “*” 符号表达一些未知的元素,如 “//*” 表达选择当前文档下所有元素。
例如:
/bookstore//year 表示bookstore元素下的所有year元素
/*/price 表示所有在第二层元素中含有price元素的元素。
选择分支
XPath表达式中可以用[]表达选择分支。如:
/bookstore/book[@lang] 表示/bookstore/book中所有含有lang属性的book元素
/bookstore/book[price=29.99] 表示/bookstore/book中所有price=29.99的book元素
/bookstore/book[price=29.99]/price表示/bookstore/book中所有price=29.99的price元素
/bookstore/book[1] 表示/bookstore下的第一个book元素(从1而非0开始索引)
/bookstore/book[last()] 表示/bookstore下的最后一个book元素
通过 | 选择多个路径
XPath中可以使用 | 操作符来选择多个路径。如:
//title | //@lang 表达所有含所有title元素以及所有lang属性。
选择属性
在XPath中,属性以@开头,其他的操作类似于元素的选择于定位。
//book[@lang] 选择所有含有lang属性的book元素
//@lang 选择所有lang属性
//book[@*] 选择所有book元素
一些常用的操作符和专用字符
已经提到过的有 “/” “//” “*”等。
另外还有:
. 表示当前上下文(“目录”)
.. 表示父节点(“父目录”)
: 表示从元素或属性中分离命名空间的前缀
() 表示组合操作
[] 引用一个过滤模式
+ - * div mod 表示 和 差 乘 除 模 操作
XPath定位路径
一个XPath的定位路径将返回一个节点集。这就是节点定位的另一种表达方式。可以有绝对路径(/step/step/…)和相对路径(step/step/…)的表达。定位路径语法为:
轴名::节点测试[预测]
轴为定位路径和当前节点的关系。
节点测试为当前要选择的类型和名称。节点测试可以是子节点名、属性名、函数等。
预测相当于节点定位的选择分支,它提供一些过滤条件。
如:
child::price 表示当前节点中的子节点中的所有price元素
attribute::src 表示当前节点的src属性
child::text() 表示当前节点的所有文本子节点
child::*/child::price 表示当前节点的所有孙子节点中的所有price元素
child::book[position()=1] 表示当前节点第一个book子元素
parent::book[attribute::type=”string”] 表示当前节点中type是string的所有book父节点
轴:
ancestor 当前节点的所有祖先节点
ancestor-of-self 当前节点或是所有祖先节点
attribute 当前节点的所有属性
child 当前节点的所有子节点
descendant 当前节点的所有后代节点
descendant-or-self 当前节点或是所有它的后代节点
following 文档中当前节点结束标记后的所有节点
following-sibling 文档中当前节点后的所有同层节点
namespace 当前节点中的所有含有命名空间的节点
parent 当前节点的父节点
preceding 文档中当前节点标记开始前的所有节点
preceding-sibling 文档中当前节点钱的所有同层节点
self 当前节点本身
一些常用定位路径的缩写
直接省略 表示child:: 如price是child::price的缩写
@ 表示attribute:: 如@type=”string”是attribute::type=”string”的缩写
. 表示self::node()
.. 表示parent::node()
// 表示/descendant-or-self::node()/
XPath标准库函数
XPath库函数主要有:节点函数,字符串函数,数值函数以及布尔函数。
节点函数有:position, last(), count(), name(), id(string), idref(), key(), doc(), docref(), local-part(), namespace(), qname(), generate-id()等
字符串函数:concat(), contains(), normalize-space(), starts-with(), string(), substring(), substring-after(), substring-before(), translate()等
数值函数:ceiling(), floor(), number(), round(), sum()等
布尔函数:boolean(), false(), not(), true()等
具体可以参看:http://www.w3school.com.cn/xpath/xpath_functions.asp
XSL概述
XSL(Extensible Stylesheet Language,扩展样式表语言)是一种基于XML的语言,它用来转换XML文档到另一种文档。在功能上,它类似于CSS,但是它是专门为XML设计的样式显示文档,而CSS是专门为HTML设计的,因而在显示功能上,它表达能力更强,也更加符合XML的规范,比如XSL不仅可以决定XML文档的显示方式,而且可以想添加或是移动元素,它还能重新排列或是索引数据等。不过它也比CSS更加的复杂。XSL是通过将XML文档转换为其他文档(如HTML文档)来控制它的显示效果,同时它也提供了一些格式化的操作。因而XSL包含了两部分:一部分用来转换XML文档,一部分用来格式化XML文档。对于这两种不同的需求,出现了三种技术:XSLT(Extensible Stylesheet Language Transformations):一种用于转换XMl文档的语言,XPath(XML Path Language):一种用于在XML文档中导航的语言,XSL-FO(Extensible Stylesheet Language Formatting Objects):一种用于格式化XML文档的语言。
可以将XSL理解成:
l 一种将XML转换成HTML的语言。
l 一种可以过滤和分类XML数据的语言。
l 一种可以对一个XML文档部分进行寻址的语言。
l 一种可以基于数值格式化XML数据的语言。(如用红色显示负数)
l 一种向不同设备输出XML数据的语言。(如屏幕、纸张等)
使用XSL样式表将XML文档转换成其他不同格式的文档(如HTML)有三种主要处理方式:
1. 将XML文件和XSL样式表文件都发送到客户端,客户端根据XSL样式表文件来转换XML文件,并将他们呈现给用户。这种方式服务器的处理相对简单,但是要传输两个文件,而且不利于数据的保密,会被某些不法用户得到一些服务器内部信息。但是由于它不用在服务器端处理,因而相应速度会好一些。
2. 服务器将XSL样式表引用于XML文档,并把转换后的文档发送给客户端。这种方式会加重服务器的负担。只能用于处理数据量不大的情况下。
3. 第三方应用程序将原XML文档转换为某种形式的文档(一般为HTML),然后将此文档放到服务器上。服务器把转换后的文档发送给客户端。这种方式可以减轻服务器的负担,数据保密良好,唯一的要求就是需要一个第三方转换程序。这种方式和前面一种方式一样因为要在服务器端处理转换,所以反应速度会相对减慢。
XSL样式表对XML文档的转换过程:
1. 根据XML文档构造一个源树,XSL处理器根据XSL样式表文件的指示对这个源树进行排序、复制、过滤、删除、选择、运算等操作后产生一颗结果树。这种转换协议通过XSLT来完成。
2. 在生成结果树后,对其进行解释以产生一种合适显示、打印或播放的文件,即格式化。

XSL文档结构
XSL文档的标准格式如下:
<?xml version=”
<xsl:stylesheet version=”
模板规则
输出模板
</xsl:stylesheet>
模板规则分为模式(Pattern)和模板(Template)。模式用来定义模板规则所适用的树状结构,模板用来与此模式匹配时进行输出。
在XML文档中对XSL的引用:
<?xml-stylesheet type=”text/xsl” href=”要引用的xsl文件的路径及文件名”?>
有一下XML文件:
<?xml version="1.0" encoding="ISO-8859-1"?>
<?xml-stylesheet type=”text/xsl” href=”tableFormat.xsl”?>
<bookstore>
<book category="COOKING">
<title lang="en">Everyday Italian</title>
<author>Giada De Laurentiis</author>
<year>2005</year>
<price>30.00</price>
</book>
<book category="CHILDREN">
<title lang="en">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
<book category="WEB">
<title lang="en">XQuery Kick Start</title>
<author>James McGovern</author>
<author>Per Bothner</author>
<author>Kurt Cagle</author>
<author>James Linn</author>
<author>Vaidyanathan Nagarajan</author>
<year>2003</year>
<price>49.99</price>
</book>
<book category="WEB">
<title lang="en">Learning XML</title>
<author>Erik T. Ray</author>
<year>2003</year>
<price>39.95</price>
</book>
</bookstore>
有XSL文件tableFormat.xsl定义如下:
<?xml version=”
<xsl:stylesheet version=”
<xsl:template match=”/”>
<html>
<head><title>购书中心数据显示表</title></head>
<body>
<h2 align=”center”>购书中心数据显示表</h2>
<table border=”
<tr>
<th>书名</th>
<th>语言</th>
<th>作者</th>
<th>出版时间</th>
<th>价格</th>
</tr>
<xsl:for-each select=”/bookstore/book”>
<tr>
<td><xsl:value-of select=”title” /></td>
<td><xsl:value-of select=”@lang” /></td>
<td><xsl:value-of select=”auther” /></td>
<td><xsl:value-of select=”year” /></td>
<td><xsl:value-of select=”price” /></td>
</tr>
</xsl:for-each>
</table>
</html>
</xsl:template>
</xsl:stylesheet>
XSLT(XSLT模板)元素的语法
XSLT用于将XML文档转换为其他形式的文档,如HTML文件、PDF文件、甚至一段声音。目前XSLT最主要的功能是将XML文档转换为HTML文档。
XSLT由一个或多个模板构成。模板由两部分组成:匹配模式(Match Pattern)和执行。匹配模式定义XML文档中被模板处理的节点;执行定义输出的格式。这两部分分别对应的元素为:xsl:template和xsl:apply-templates。
对执行,感觉这个词用的不好,开始我就被弄的糊里糊涂的,不知道这次词在表达的是什么意思。因而有必要做一个具体的介绍。xsl:apply-templates元素是相当于子函数的调用,在xsl:template元素内调用这样一个“子函数”,而这个“子函数”的实现则在另外的地方时先,它的实现也是通过xsl:template元素来定义。并且xsl:apply-templates元素会为它的被调用地中的每个匹配元素调用一次它的实现模板,所以我们也看到了它的定义中的templates是复数形式的。调用和被调用之间的识别是通过匹配模式集来识别的。这样讲解比较抽象,以上面的例子为例,上面我们是用xsl:for-each元素来实现的,但是我们也可以用xsl:apply-templates元素来实现:
<?xml version=”
<xsl:stylesheet version=”
<xsl:template match=”/”>
<html>
<head><title>购书中心数据显示表</title></head>
<body>
<h2 align=”center”>购书中心数据显示表</h2>
<table border=”
<tr>
<th>书名</th>
<th>语言</th>
<th>作者</th>
<th>出版时间</th>
<th>价格</th>
</tr>
<tr>
<xsl:apply-templates select=”/bookstore/book” />
</tr>
</table>
</html>
</xsl:template>
<xsl:template math=”book”>
<td><xsl:value-of select=”title” /></td>
<td><xsl:value-of select=”@lang” /></td>
<td><xsl:value-of select=”auther” /></td>
<td><xsl:value-of select=”year” /></td>
<td><xsl:value-of select=”price” /></td>
</xsl:template>
</xsl:stylesheet>
xsl:template元素
xsl:template元素是XSL样式表中最重要的元素。每一个模板都由一个xsl:template元素构成,即xsl:template元素是模板的根元素。其语法定义规则如下:
<xsl:template match=”模板应用于输入文档的节点集(XPath表达式返回的结果)”>
模板的内容…..
</xsl:template>
模板的内容是要输出的文档的结构,如上例中的定义,输出一张以HTML格式定义的表格。
xsl:apply-templates元素
xsl:apply-templates元素指示处理器发现一个合适的模板,而且在每个选择的元素上执行指定的任务。可以将其理解为子函数的调用。定义语法如下:
<xsl:apply-templates select=”要处理元素的匹配模式”>
</xsl:apply-templates>
xsl:value-of元素获取节点值
XSL通过xsl:value-of元素来获取XML文件中被选择的元素或属性的内容。格式如下:
<xsl:value-of />
表示选取当前XML文件元素集中的所有元素或属性的内容。
<xsl:value-of select=”匹配模式” />
匹配模式由XPath表达式确定,因而它可以有许多中形式的定义。同XPath,属性名前需加@或是使用轴定义(attribute::)。
xsl:for-each元素
xsl:for-each元素循环被选择的节点集,并对每个节点进行一次处理。格式:
<xsl:for-each select=”匹配模式”>
要处理输出的内容….
</xsl:for-each>
xsl:value-of元素只能用于获取确切的节点的内容,如果有多个节点,则xsl:value-of元素只处理第一项元素。因而对匹配模式存在多个元素的返回集中,可以用xsl:for-each元素和xsl:value-of元素合在一起使用,如上面的例子所示。
模板的默认规则
1. 元素默认规则
<xsl:template math=”* | /(任何元素节点或根节点)”>
<xsl:apply-templates />
</xsl:template>
2. 文本节点默认规则
<xsl:template math=”text()(所有文本节点)”>
<xsl:value-of select=”.” />
</xls:template>
这两个规则同时使用,可以使一张空的XSL样式表,对于输入的XML文档,可以默认的输出该XML文档的所有内容字符。这种默认规则的优先级很低,因而只要有其他的定义,就可以覆盖他们的定义。
空的样式表定义如下:
<?xml version=”
<xsl:stylesheet xmlns:xsl=”http://www.w3.org/1999/XSL/Transform” >
</xsl:stylesheet>
对输出元素排序
xsl:sort元素可以对输出元素按规则排序。xsl:sort元素可以作为xls:apply-templates元素或xsl:for-each元素的子元素出现。其定义如下:
<xsl:sort select=”元素名” order=”ascending | descending”
case-order=”upper-first | lower-first” data-type=”text | number | qname” />
data-type表示被排序的数据类型,可以是数值、文本或用户自定义,默认为文本。
select定义排序输出元素的关键字。
order表示升序还是降序排序。默认为ascending。
case-order表示大小写的排序规则。即大写在前还是小写在前。
如:
<xsl:apply-templates select=”/bookstore/book”>
<xsl:sort select=”price” data-type=”number” order=”descending” />
</xsl:apply-templates>
选择
XSL提供了两个元素,他们可以根据输入文档来改变输出内容。
1.xsl:if元素:根据输入文档中存在的模式,决定是否输出给定的内容。
2.xls:choose元素:根据文档中存在的模式,从几个可能的XML段中选出一个。
xsl:if元素定义:
<xsl:if test=”匹配模式”>
</xsl:if>
匹配模式可以任意的XPath表达式,因而这里可以测试元素名,元素内容,属性内容等。
如:
<xsl:if text=”price[.=10.0]”>
<font color=”red”>
<xsl:value-of select=”price” />
</font>
</xsl:if>
xls:choose元素定义:
<xsl:choose>
<xsl:when test=”匹配模式”>
输出内容…
</xsl:when>
<xsl:when test=”匹配模式”>
输出内容….
</xsl:when>
….
<xsl:otherwise>
输出内容….
<xsl:otherwise>
</xsl:choose>
输出内容的扩展
之前的内容中,我们一直在做把XML文档转换为HTML文档。而且所做的都是将XML文档中元素的内容或属性内容转换为HTML文档中的内容。然后XSL定义的是将XML文档转换为另一种的文档,它可以是HTML文档,也可以是另一种的XML文档,因而不可避免的,有时候需要根据XML文档中的内容决定输出的内容,包括输出的元素标签值,元素的属性值,元素的内容,注释等。因而XSL样式表中定义了几种方式来实现这样的功能:属性值模板、xsl:element元素、xsl:attribute元素、xsl:pi元素、xsl:comment元素和xsl:text元素等。
属性值模板:
使用{}格式将输入的属性值或是元素值写入相应的输出流,多个{}可以一起使用,表示连接(如{id}{title}形式)。如:
对以下源XML文档:
<DVD id=”
<title>wind</title>
<format>movie</format>
<genre>classic</genre>
</DVD>
可以通过以下XSL文档转换成<DVD id=”
<xsl:template math=”DVD”>
<DVD id=”{@id}” title=”{title}” format=”{movie}”>
<xsl:value-of select=”genre” />
</DVD>
</xsl:template>
xsl:element元素
<xsl:element name=”要创建元素的名称” namespace=”所创建元素的命名空间”
use-attribute-sets=”属性集限定名” />
该元素实现动态的根据输入XML文档的值,在输出文档中创建新的元素。
如上例子的转换中可以将源XML文档转换成:
<wind format=”movie”>classic</wind>
通过以下的XSL文档的转换即可:
<xsl:element name=”{title}” >
<xsl:attribute name=”format”>
<xsl:value-of select=”format” />
</xsl:attribute>
<xsl:value-of select=”genre” />
</xsl:element>
xsl:attribute元素
<xsl:attribute name=”属性名” namespace=”创建属性的命名空间”>
属性的值….
</xsl:attribute>
xsl:attribute元素一般作为xsl:element元素的子元素来使用,如上例。也可以作为xls:attribute-set元素的子元素。
xsl:attribute-set元素
<xsl:attribute-set name=”属性集限定名” use-attribute-sets=”已定义的属性值限定名”>
<xsl:attribute ….. >…..</xsl:attribute>
…….
</xsl:attribute-set>
注:属性集中定义的属性可以被使用的元素中自己的同名属性覆盖。
且属性集的定义可以在xsl:template元素之外。
xsl:comment元素和xsl:text元素
这两个元素都直接像输出文件中输出注释或文本,由于文本可以直接插入输出文件中,所以xsl:text元素只是在需要保留文本格式的时候,如一段代码,使用,因为改元素可以原封不动的保留定义的文本格式。如:
<xsl:comment> This is a comment! </xsl:comment>
<xsl:text> space reserved ! </xsl:text>
xsl:copy元素和xsl:copy-of元素
<xsl:copy use-attribute-sets=”属性集名”>
要复制的内容…
</xsl:copy>
将xsl:copy中的内容输出到输出流。
<xsl:copy><xsl:apply-templates /><xsl:copy> 将当前元素的内容复制到输出流。
<xsl:copy><apply-templates select=”* | @* | comment() | pi() | text()” /><xsl:copy>
将当前元素原封不动的复制到输出流。
简单的,可以直接通过xsl:copy-of元素来复制匹配节点的所有元素(包括命名空间,子节点,节点属性等)。
<xsl:copy-of select=”匹配模式” />
如:<xsl:copy-of select=”price” />
xsl:number元素
xsl:number元素可以在输出文件中插入格式化整数。由value属性计算出数值,通过四舍五入转换成整数,然后根据format属性对整数进行格式化,最后插入该整数。语法如下:
<xsl:number level=”single | multiple | any” count=”pattern” from=”pattern” value=”number-expression” format={string} lang={nmtoken} letter-value={“alphabetic | traditional”} grouping-separator={char} grouping-size={number} />
这个元素比较复杂,我还没完全理解意思。先放下!
xsl:variable元素
定义全局变量或是局部变量,一定复制就不能改变。或许说常量更适合一些,因为它的定义的用处就和宏定义的用处是一样的。
<xsl:variable name=”变量限定名” select=”表达式”>
变量值….
</xsl:variable>
若存在select属性,则表达式的值即为定义的变量的值,此时,变量的内容必须为空。
访问该变量只要在变量名钱加上$即可。
如:<xsl:value-of select=”$define” />
类似的功能和定义的有xsl:param元素。
<xsl:param name=”参数名” select=”表达式”>
参数值….
</xsl:param>
这两个元素的定义和要求都是一样的,个人感觉用法也是一样的,不知道为什么会同时存在。
另有类似的定义有:xsl:with-param元素。
<xsl:with-param name=”参数名” select=”表达式”>
参数值….
</xsl:with-param>
这些属性的要求都是一样的,这个元素主要是用于xsl:call-template和xsl:apply-templates元素中,作为传入的参数使用。参数的使用也是在参数名前加$符。
命名模板
在xsl:template元素中加入name属性,就可以创建命名模板。这样就可以通过xsl:call-template元素在其他的xsl:template元素中用模板名调用改模板。
<xsl:call-template name=”templateName” />
关于空白节点
<xsl:strip-space/xsl:preserve-space element=”elementName” />
xsl:strip-space元素用于删除被选择节点中的空白节点
xsl:preserve-space元素用于保留内容中的任何空白
也可以在在xsl:stylesheet元素中设置indent-result属性为yes,以允许处理程序将多于的空白插入到输出文档中。
<xsl:stylesheet xmlns:xsl=” http://www.w3.org/TR/WD-xsl” ident-result=”yes”>
…..
</xsl:stylesheet>
导入其他样式表
可以通过xsl:import或xsl:include元素导入另一个XSL文件。
<xsl:import/xsl:include href=”location” />
它们两个所不同的是:
xls:import只能直接包含在xsl:stylesheet之后,而xsl:include则可以在最后一个xsl:import之后的任意外置。
参考:
《XML完全开发指南》 科学出版社 孙更新 裴红义 杨金龙 编著

