
hdfs实践(hadoop_04)
Hdfs操作命令
- 查看根目录:Hadoop fs -ls /
- 上传文件到根目录:hadoop fs -put a.txt /
- 相同功能另一种写法:hadoop fs -copyFromLocal 本地路径 hdfs的路径
- 下载:hadoop fs -get /aa.txt 和 hadoop fs -copyToLocal /aa.txt
- 创建test目录:hadoop fs -mkdir /test 和 hadoop fs -mkdir -p /test/test
- 删除文件或文件夹:hadoop fs -rm /a.txt 和hadoop fs -rm -r /test
- 看文件:hadoop fs -cat /a.txt
- 文件大的时候分页看 hadoop fs -cat /a.txt less
动态扩容
1、准备一台服务器,配置好环境:网络、ip、防火墙、主机名、域名、免密登陆、jdk
(1)域名:etc/hosts 192...** hdp-01
(2)免密登陆:ssh-copy-id -i ~/.ssh/id_dsa.pub hdp-test
2、从原集群的任意一台机器上复制hadoop安装包到新机器上、
3、在原集群的slaves文件中添加新机器的主机名(只修改master机器即可)
4、在新机器上启动datanode即可
一些配置属性
块大小:参数dfs.blocksize 默认128M (由客户端决定)
副本数量:参数dfs.replication 默认3 (由客户端决定)
元数据存目录:参数dfs.namenode.name.dir 默认file://${hadoop.tmp.dir}/dfs/name (给服务器端namenode使用)一般生产环境应该挂载磁盘,写法:
<name>dfs.namenode.name.dir</name>
<value>/mnt/disk1,/mnt/disk2,/mnt/disk3</value>
文件块存储目录:参数dfs.datanode.name.dir 默认file://${hadoop.tmp.dir}/dfs/data (给服务器端datanode使用)一般生产环境应该挂载磁盘,写法:
<name>dfs.datanode.name.dir</name>
<value>/data/disk1,/data/disk2,/data/disk3</value>
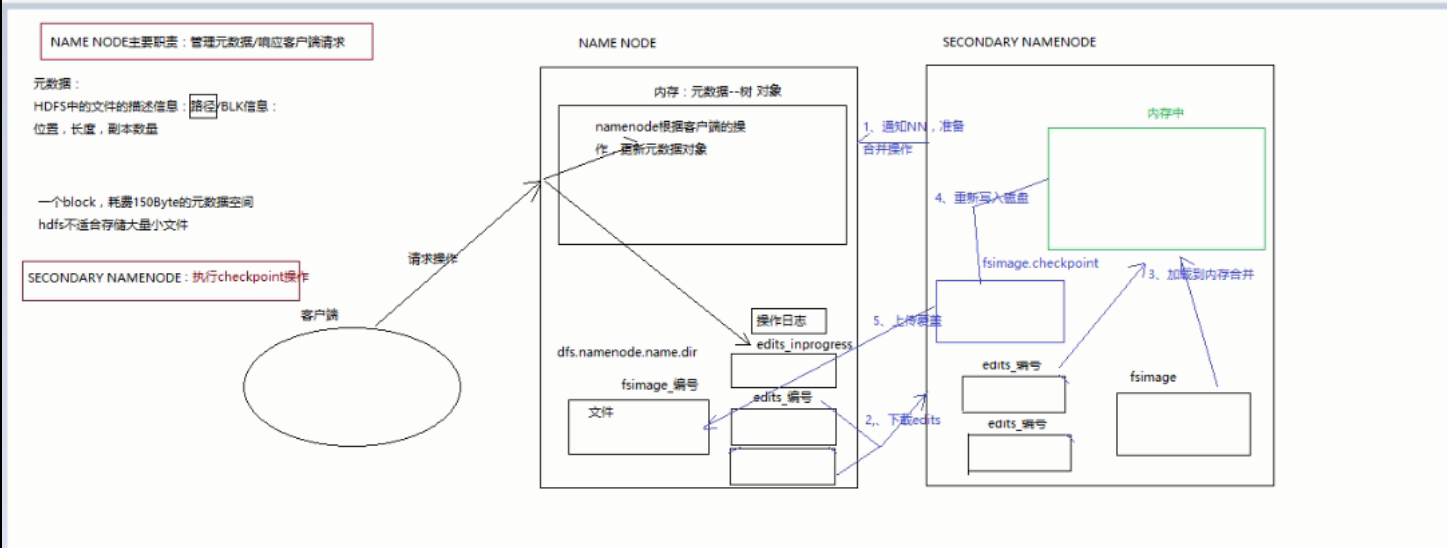
namenode操作职责
-
namenode 主要职责管理元数据/响应客户端请求
-
元数据(存储在内存中):
hdfs中文件的描述信息:路径/blk信息
位置,长度,副本数量
一个block,耗费150byte的元数据空间
hdfs不适合存储大量小文件 -
元数据-存内存中-是个对象
持久化:dfs.namenode.name.dir
fsimage_编号 -
问题:客户端进程操作,更改内存中的元数据,如果持久化不及时,就会造成两方数据不一致,這样宕机就恢复不了。
namenode解决方案:
客户端操作namenode时-记录操作日志edit_inprogress
宕机回复时,先加载fsimage_文件后 ,在执行操作日志edit_inprogress
- fsimage_编号+edit_编号介绍
fsimage_40持久化的数据
edit_inprogress记录最近正在操作的记录
edit_1...50记录历史操作的记录
数据恢复时候,加载fsimage_40后 ,只需要执行edit_41..50的文件即可。
- 如何保证edit_编号,和fsimage_编号保持最近。避免恢复时话费时间过长?
hdfs引入了secondary namenode 执行checkpoint
它每隔一段时间 ,会通知namenode进行合并操作
secondary namenode 向 namenode下载 edit_编号文件,和fsimage_编号文件(fsimage只需第一次下载一次,之后secondary namenode本地就有了)。
secondary namenode 加载fsiamge文件到内存,执行下载过来的edit操作。之后将新的fsimage文件写回namenode

 浙公网安备 33010602011771号
浙公网安备 33010602011771号