第四周:卷积神经网络 part3
一、循环神经网络视频学习
- 循环神经网络—基本应用
语音问答、机器翻译、股票预测、作词作诗机、模仿写论文和代码(主要是格式上的模仿)、图像理解、视觉问答。RNN是一种特殊的神经网络结构, 它是根据"人的认知是基于过往的经验和记忆"这一观点提出的. 它与DNN,CNN不同的是: 它不仅考虑前一时刻的输入,而且赋予了网络对前面的内容的一种'记忆'功能。

-
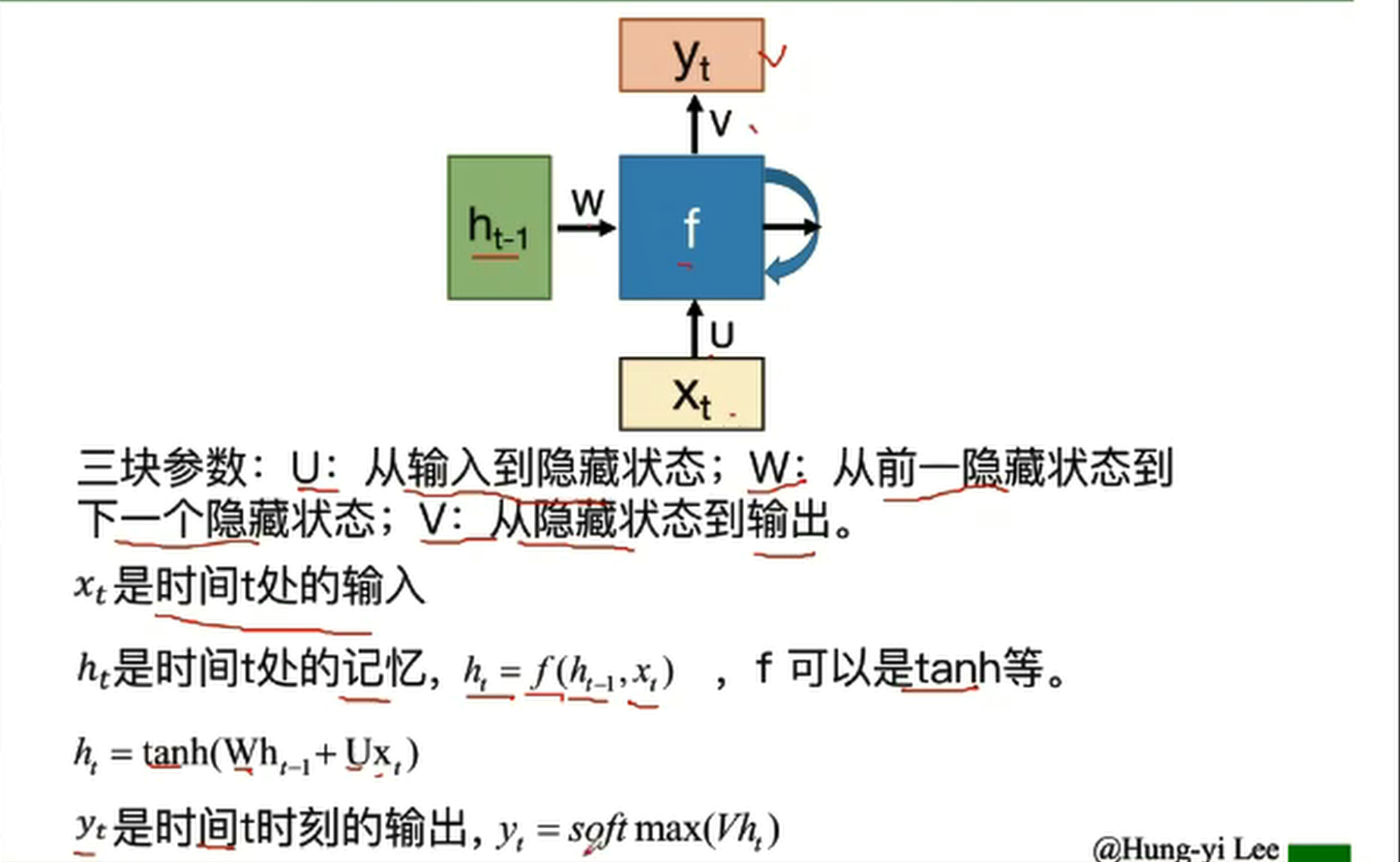
RNN的基本结构
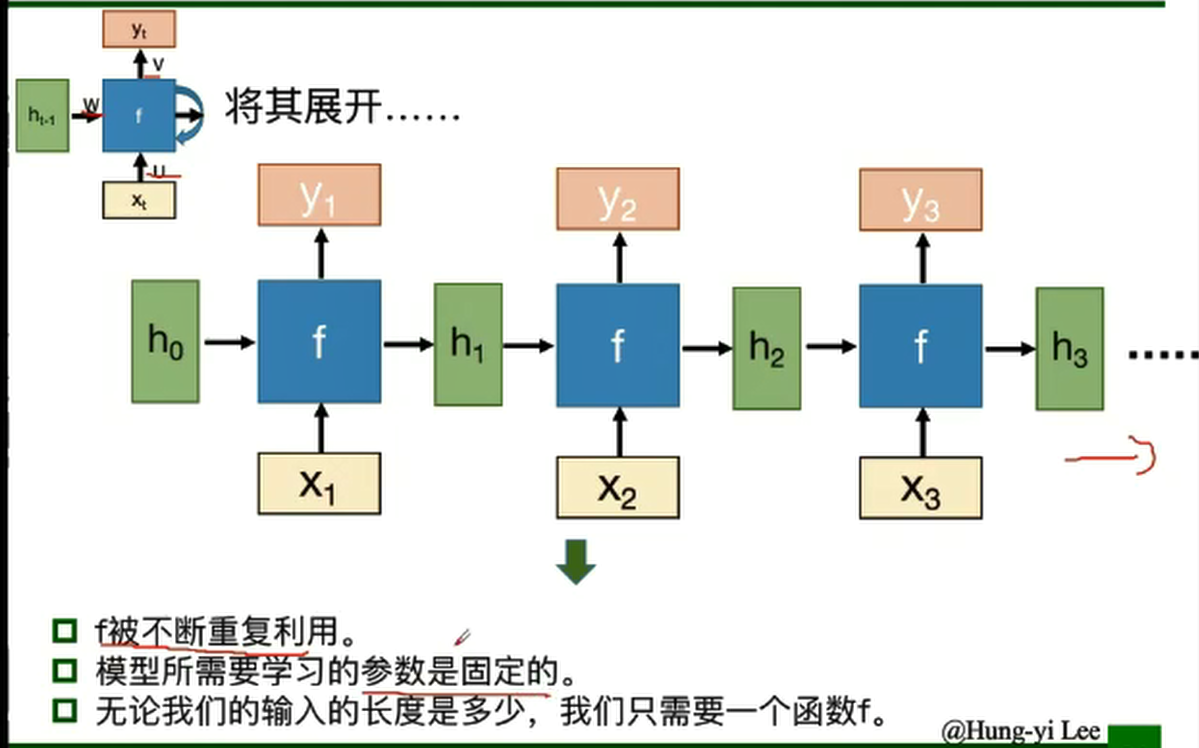
RNN之所以称为循环神经网络,即一个序列当前的输出与前面的输出也有关。具体的表现形式为网络会对前面的信息进行记忆并应用于当前输出的计算中,即隐藏层之间的节点不再无连接而是有连接的,并且隐藏层的输入不仅包括输入层的输出还包括上一时刻隐藏层的输出。
- 深度RNN
深度RNN类似双向 RNN,区别在于每 个每一步的输入有多层网络,这样的话该网络便具有更加强大的表达能力和学习 能力,但是复杂性也提高了,同时需要训练更多的数据。基本结构与RNN相同,只是在深度上不断延伸。

- 双向RNN
![]()

小结:
隐藏层状态h可以被看作是“记忆”,因为它包含了之前时间点上的相关信息
输出y不仅由当前的输入所决定,还会考虑到之前的“记忆”,有两者共同决定
RNN在不同时刻共享同一组参数( U,W,V ),极大的减小了需要训练和预估的参数量
-
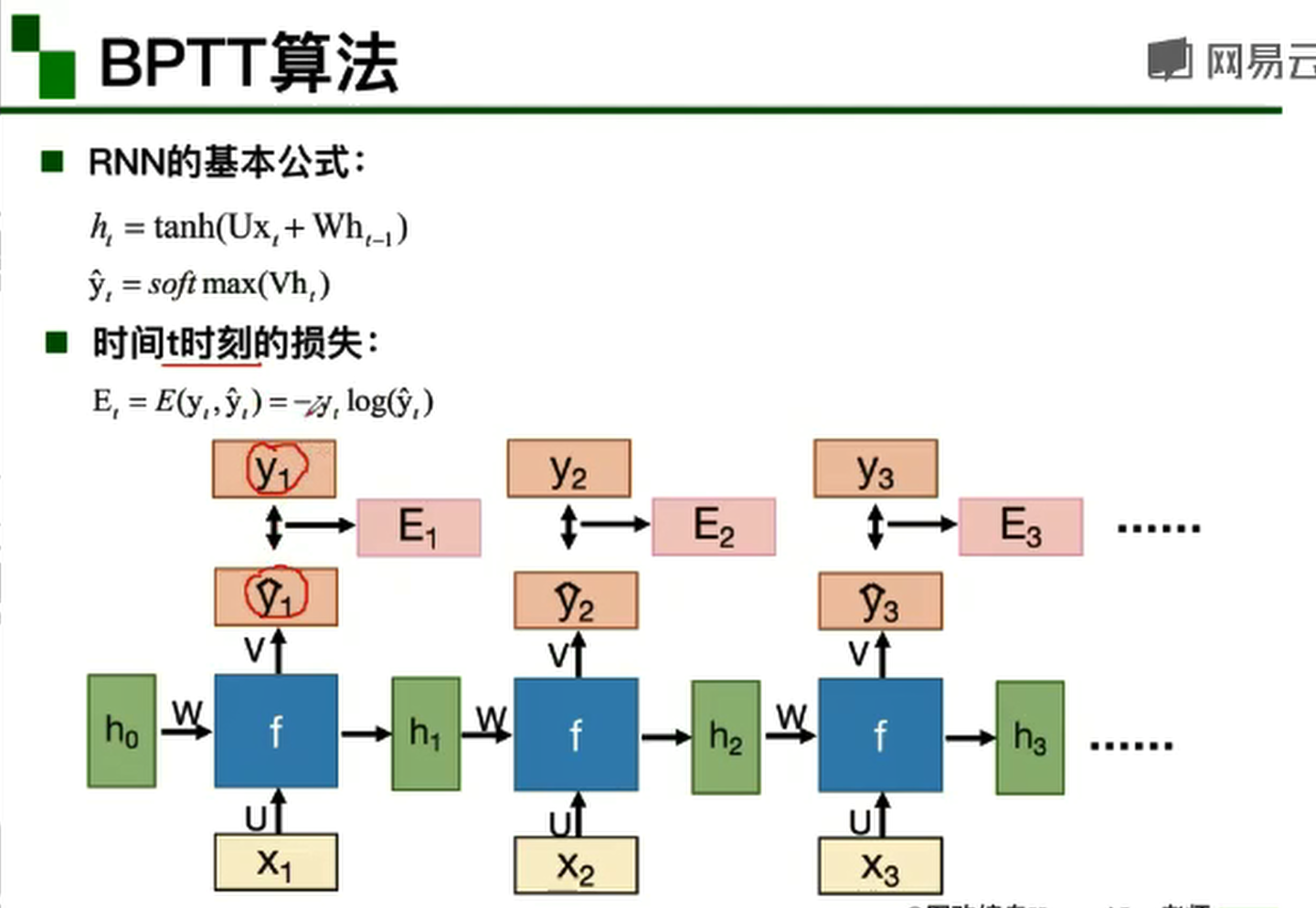
BPTT算法
BPTT算法是常用的训练RNN的方法,其实本质还是BP算法,只不过RNN处理时间序列数据,所以要基于时间反向传播,故叫随时间反向传播。BPTT的中心思想和BP算法相同,沿着需要优化的参数的负梯度方向不断寻找更优的点直至收敛。综上所述,BPTT算法本质还是BP算法,BP算法本质还是梯度下降法,那么求各个参数的梯度便成了此算法的核心。

- 传统RNN的问题
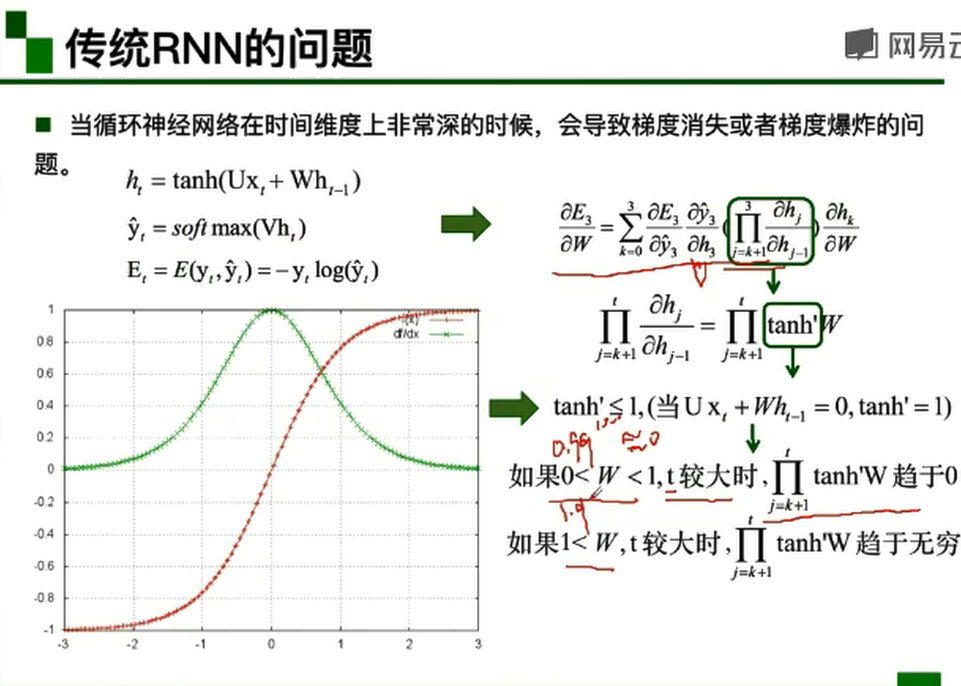
当循环神经网络在时间维度上非常深的时候,会导致梯度消失或者梯度爆炸的问题。梯度爆炸导致的问题:模型训练不稳定,梯度变为Nan(无效数字),lnf(无穷大)。

-
Long Short-term Memory-LSTM(长短期记忆模型)
长短期记忆(Long short-term memory, LSTM)是一种特殊的RNN,主要是为了解决长序列训练过程中的梯度消失和梯度爆炸问题。简单来说,就是相比普通的RNN,LSTM能够在更长的序列中有更好的表现。

遗忘门:决定丢弃信息。
输入门:确定需要更新的信息。
输出门:输出信息。
RNN和LSTM对记忆的处理方式不同。
RNN 的“记忆”在每个时间点都会被新的输入覆盖,但 LSTM 中“记忆”是与新的输入相加。
LSTM:如果前边的输入对 Ct 产生了影响,那这个影响会一直存在,除非遗忘门的权重为0。
小技巧:LSTM中learning rate可以被尽量的设置小。
小结:
LSTM实现了三个门计算:遗忘门,输入门,输出门。
LSTM的一个初始化技巧就是将输入门的 bias 置为正数(例如1或5,这点可以查看各大框架代码),这样模型刚开始训练时 forget gate 的值接近于 1 ,不会发生梯度消失。
但LSTM有三个门,运算复杂,如何解决?->GRU。
Gated Recurrent Unit-GPU(门控循环单元)。
-
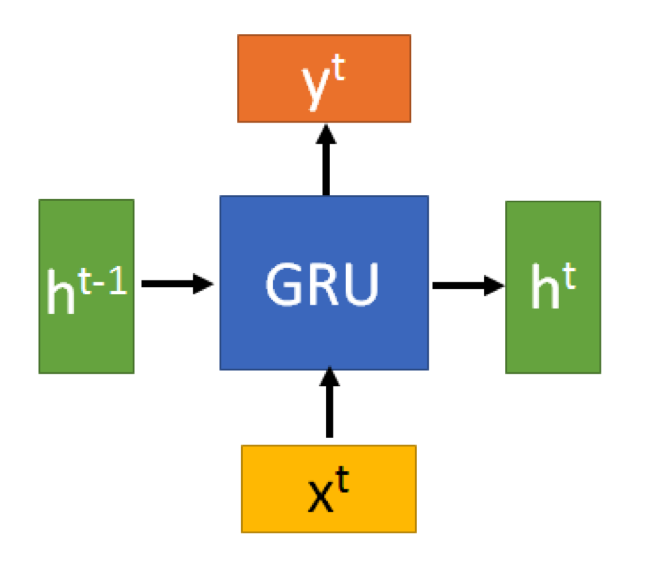
Gated Recurrent Unit-GPU(门控循环单元)
GRU(Gate Recurrent Unit)是循环神经网络(Recurrent Neural Network, RNN)的一种。和LSTM(Long-Short Term Memory)一样,也是为了解决长期记忆和反向传播中的梯度等问题而提出来的。
![]()
GRU的输入输出结构与普通的RNN是一样的。有一个当前的输入
,和上一个节点传递下来的隐状态(hidden state)
,这个隐状态包含了之前节点的相关信息。结合
和
,GRU会得到当前隐藏节点的输出
和传递给下一个节点的隐状态
。

-
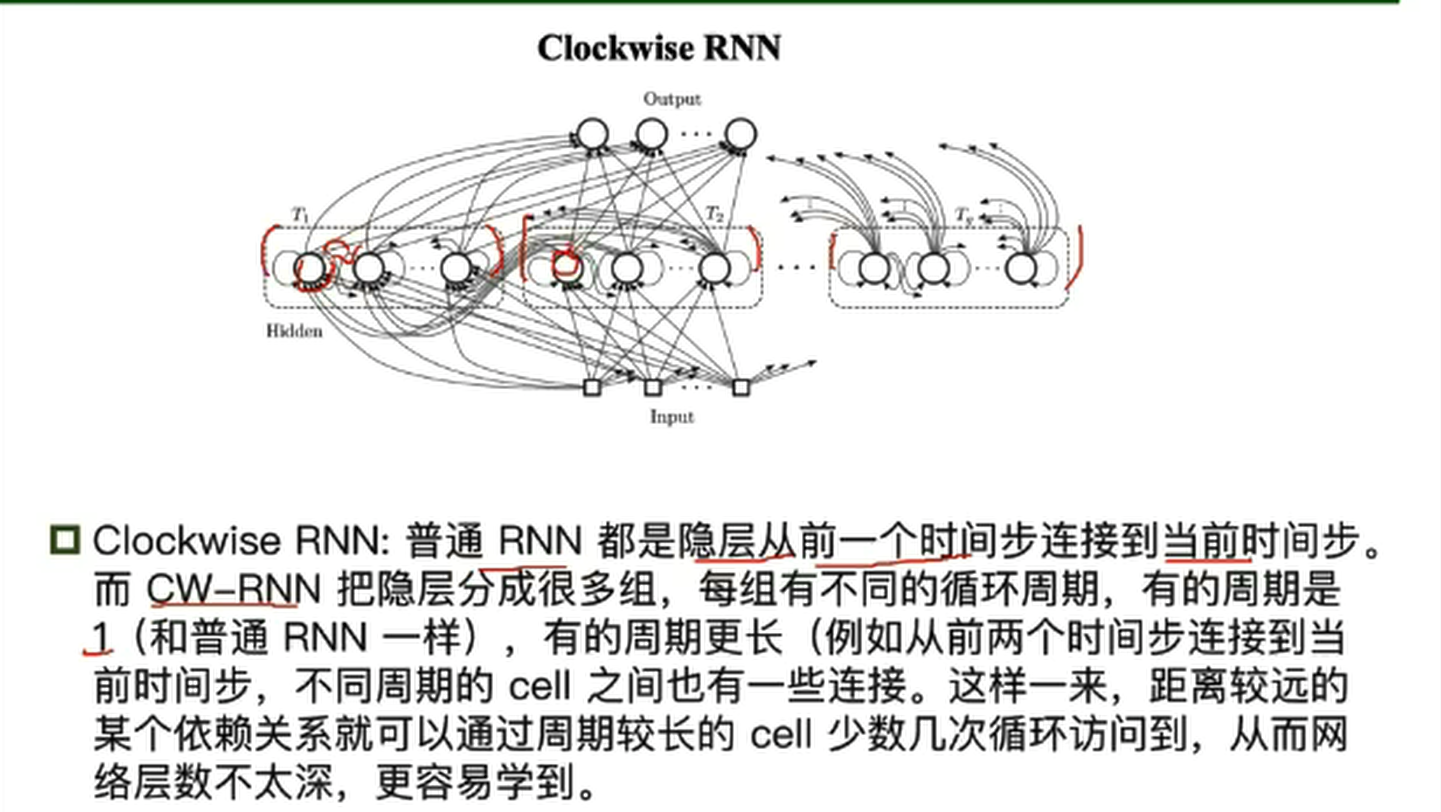
拓展—解决RNN梯度消失的其他方法
- Clockwise RNN
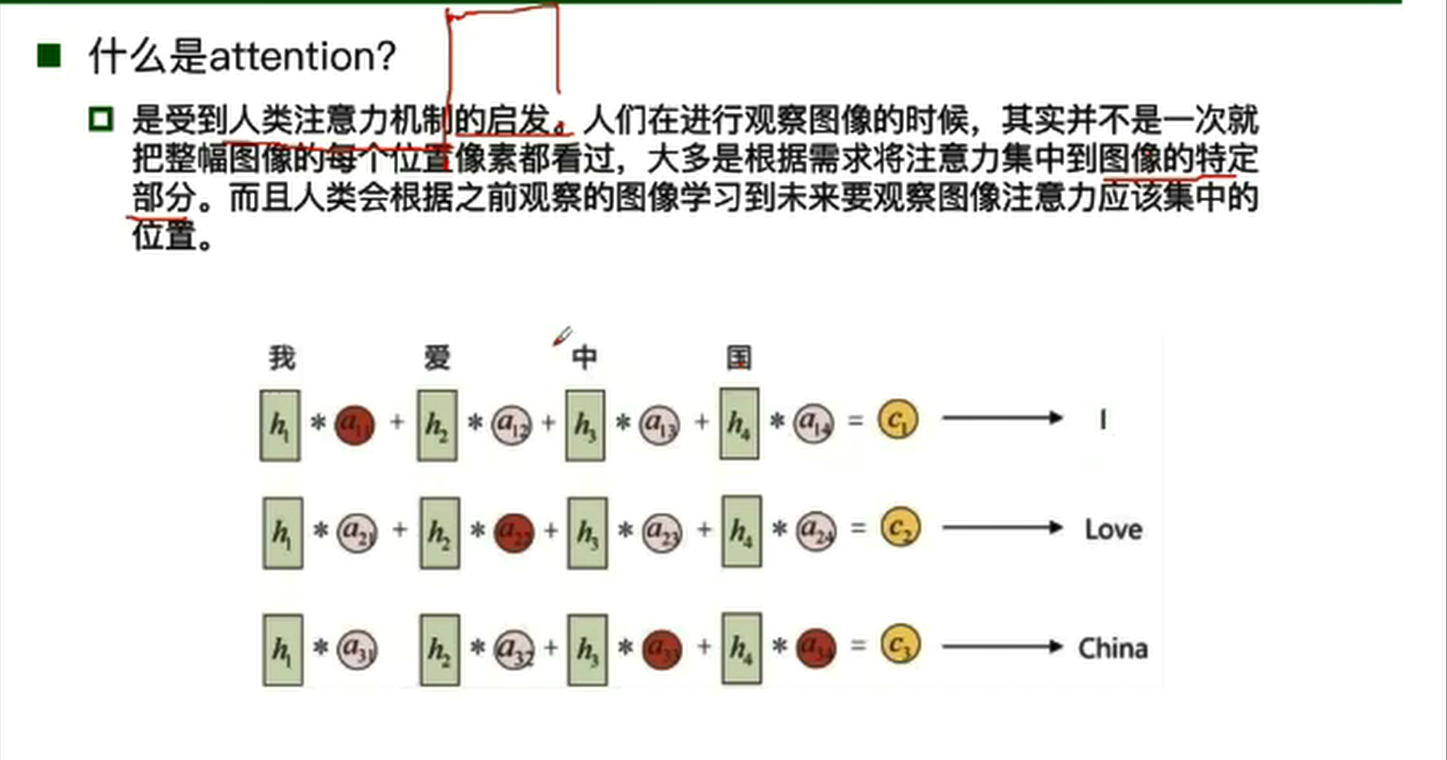
- 基于attention的RNN
![]()
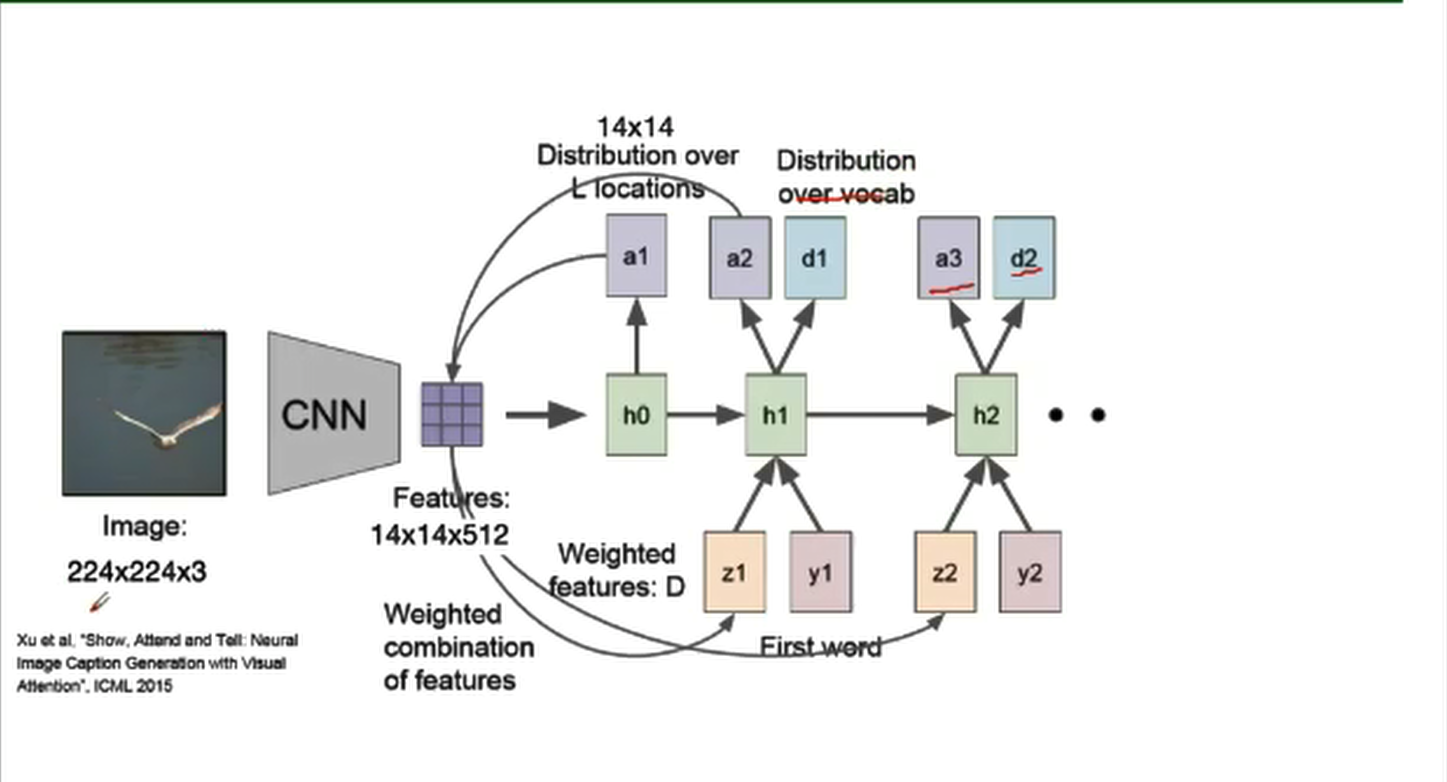
基本结构:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号