JavaScript学习笔记系列2:Dom操作(一)
一.什么是Dom?
DOM------>Document Object Model 直接翻译就是文档对象模型。
DOM------>定义了表示和修改文档所需的对象、这些对象的行为和属性以及这些对象之间的关系。DOM对象即为宿主对象,由浏览器厂商定义,用来操作html和css功能的一类对象的集合。也有人称DOM是对HTML以及XML的标准编程接口。说白了就是类型C#对象集合。举个例子 I/0,I/O包含了很多操作文件和流的对象。意思是一样的。
二.如何使用Dom?
1.查看方法。docment.getElementsById()。通过Id获取元素。下面代码实操。
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <meta http-equiv="X-UA-Compatible" content="ie=edge"> <title>Document</title> </head> <body> <div id="MyDiv"> 一小时小超人很帅! </div> <script type="text/javascript"> var div=document.getElementById('Only') </script> </body> </html>
定义了一个div变量,并且通过Id取到Div。接下来在控制台看一下效果。
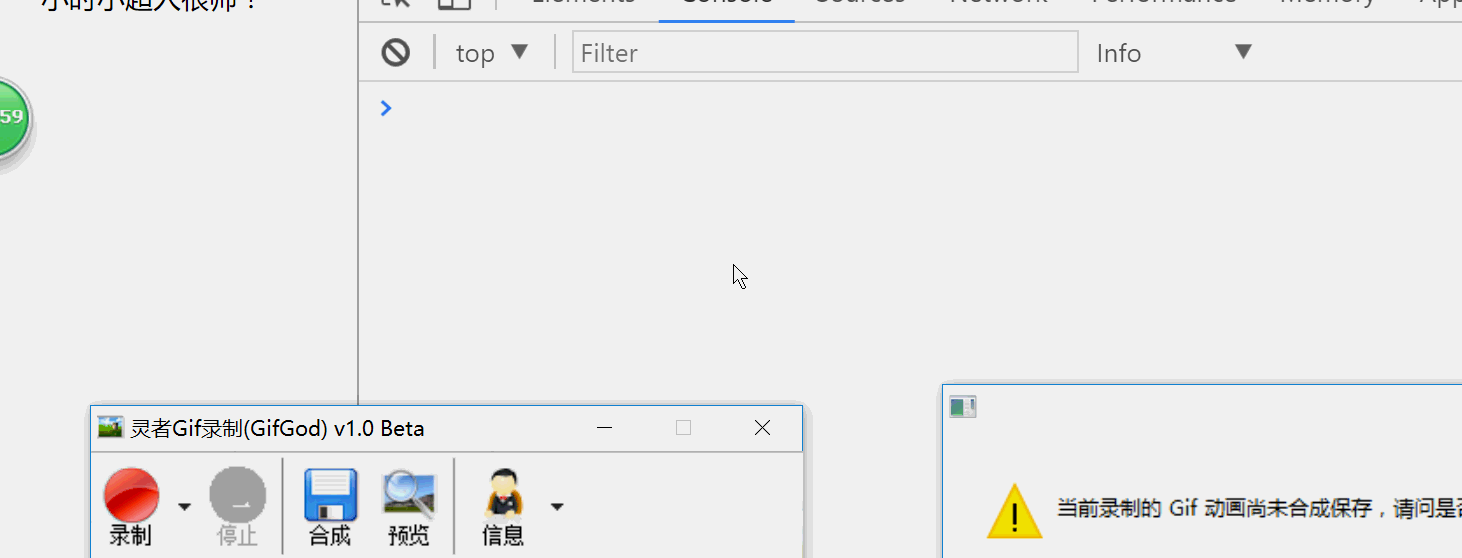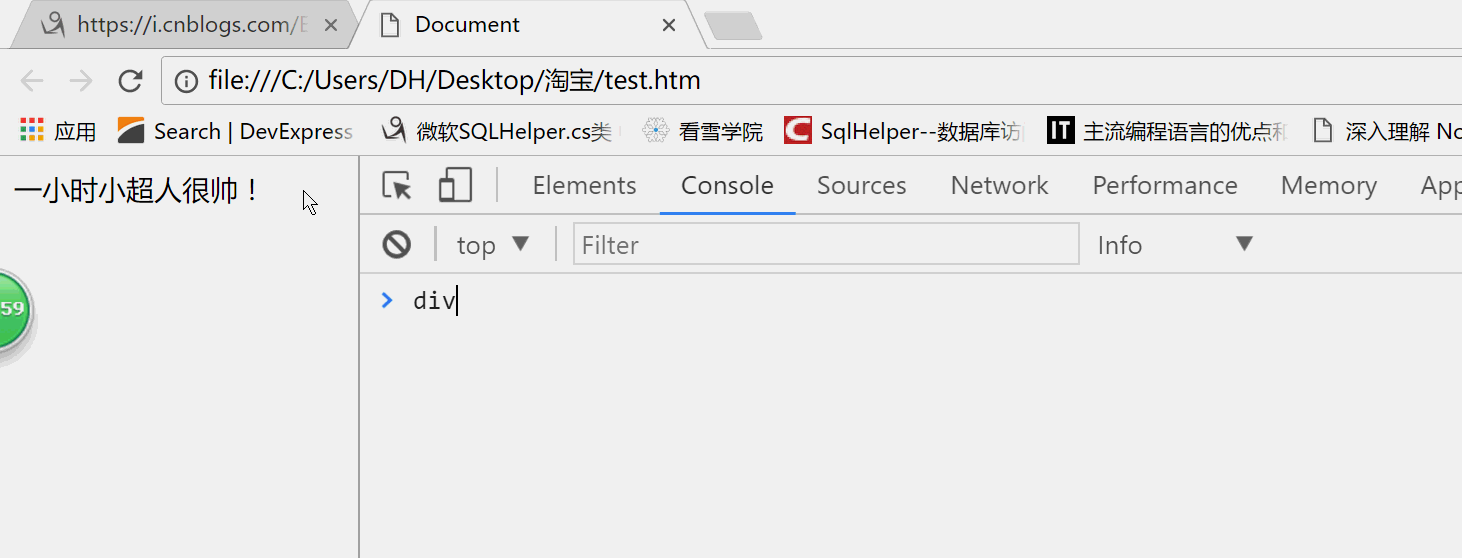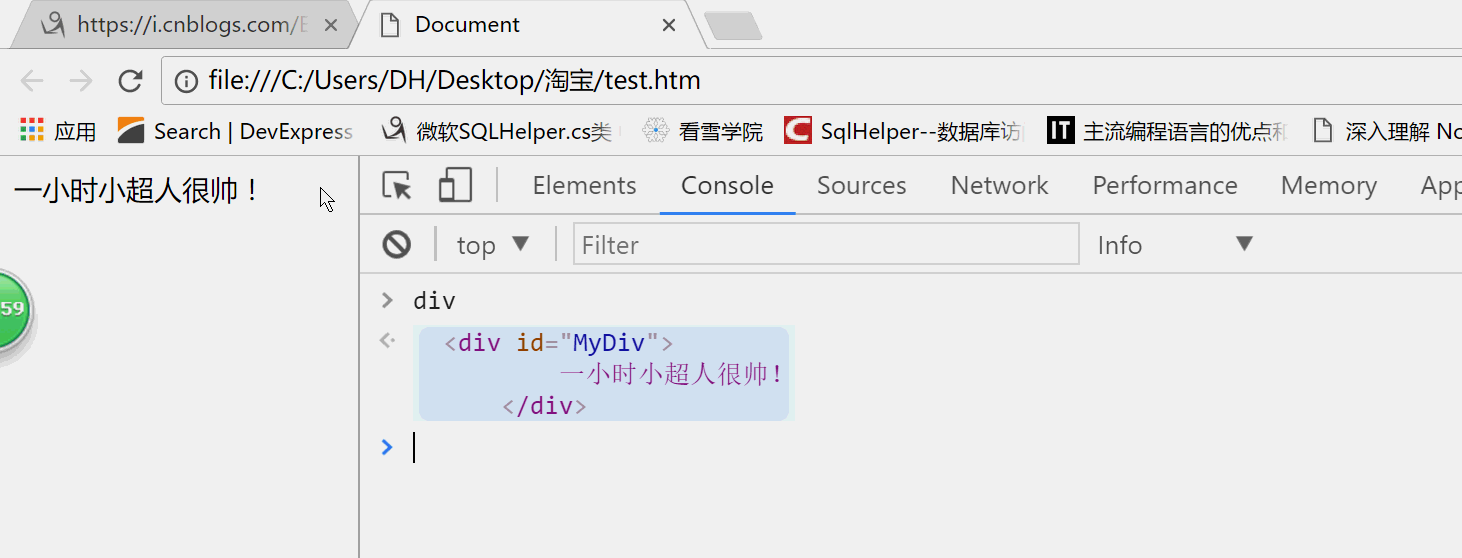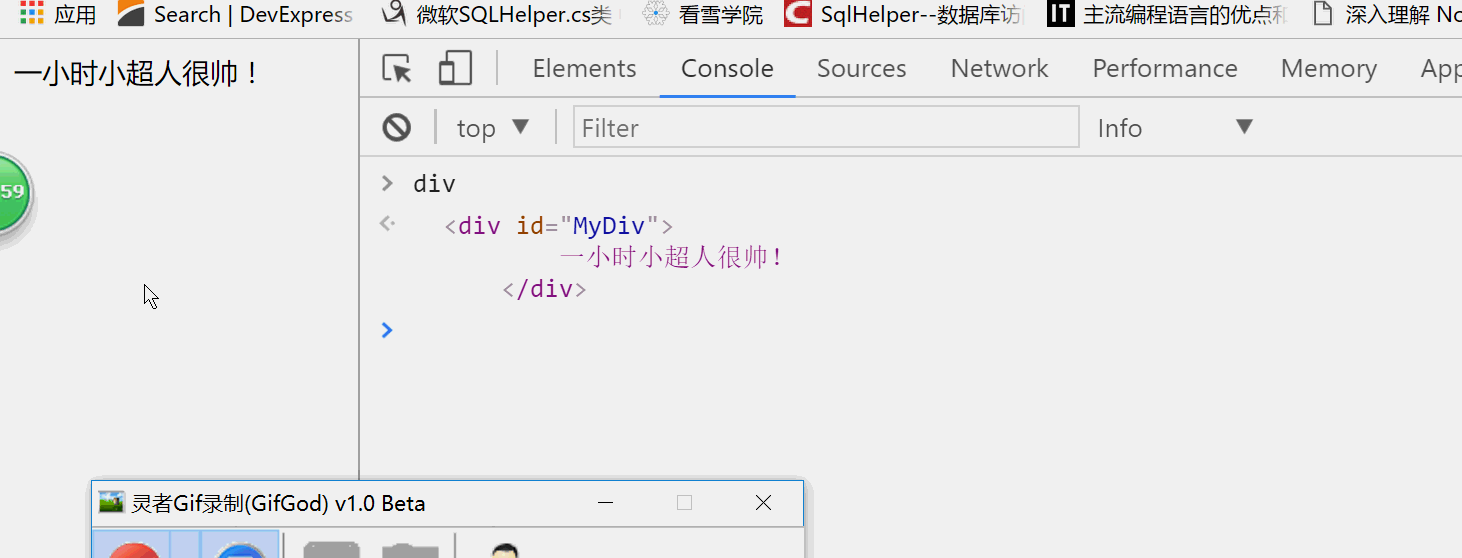
我输出div这个变量就显示了div。在IE8以下的浏览器id是不区分的大小写。
除了getElementById,还有好多个方法。我下面列举下。
document.getElementById() //元素id 在Ie8以下的浏览器,不区分id大小写,而且也返回匹配name属性的元素
getElementsByTagName() // 标签名
getElementsByName(); //IE不支持需注意,只有部分标签name可生效(表单,表单元素,img,iframe)
getElementsByClassName() // 类名 -> ie8和ie8以下的ie版本中没有,可以多个class一起
querySelector() // css选择器 在ie7和ie7以下的版本中没有
querySelectorAll() // css选择器 在ie7和ie7以下的版本中没有
简单说下querySelector 和 querySelectorAll
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <meta http-equiv="X-UA-Compatible" content="ie=edge"> <title>Document</title> </head> <body> <div clas="MyDiv"> 一小时小超人很酷! </div> <div id="MyDiv"> 一小时小超人很帅! </div> <script type="text/javascript"> var div=document.querySelector('.MyDiv') </script> </body> </html>
querySelector写法和Css选择器的写法一样。
querySelector和querySelectorAll的区别是一个返回单个,一个返回的是类数组。如果querySelector满足多个只返回第一个。
2.上面的操作是获取了节点。接下来讲讲节点有哪些操作。
遍历节点树:
parentNode -> 父节点 (最顶端的parentNode为#document);
childNodes ->子节点们
firstChild ->第一个节点
lastChild ->最后一个节点
nextSibling->最后一个兄弟节点
previousSibling->前一个兄弟节点。
上面我列举的都是节点的属性。我们整个html文档是一个树型的。通过上面的操作我可以遍历整个树,意思就是可以找个整个树上的任意的节点,并且操作。
遍历元素节点树:
parentElement->返回当前元素的父元素节点。(IE不兼容)
children->返回当前元素的子节点元素
node.childElementCount === node.children.length当前元素节点的子元素节点个数(IE不兼容)
firstElementChild -> 返回的是第一个元素节点(IE不兼容)
lastElementChild->返回的是最后一个元素节点(IE不兼容)
nextElementSibling/previousElementSiling->返回后一个/前一个兄弟元素节点。(IE不兼容)
` 上面2个一个是遍历节点树,一个是遍历元素节点树。这个两个有什么区别呢?首先要了解一个概念就是节点:什么节点?节点定义不仅仅是指我们的html标签,文字,注释都算是节点,还有属性啦比如id,class这些都是。所以两者区别都是知道了。遍历节点,不仅包含html标签。还包含其他的东西。
而遍历元素节点。则是遍历我们真正需要的元素节点。所以从使用上。我们的遍历元素节点是方便的。但是!注意这里的但是。实际我们使用的是遍历节点树。这是为什么呢?为什么遍历元素节点更方便。因为IE不兼容。只要不兼容。就不好用了。为什么IE这么不一样。
因为那个时期。浏览器是IE的天下。市场份额占了78成。所以他就牛逼啊。就不遵守规则,玩自己的一套。不过后来随着市场份额减少。他也变老实了。下面代码演示以下。
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <meta http-equiv="X-UA-Compatible" content="ie=edge"> <title>Document</title> </head> <body> <div class="MyDiv">一小时小超人很酷! </div> <div id="MyDiv1"> 一小时小超人很帅! </div> <script type="text/javascript"> var div=document.getElementById('MyDiv1') var div1=div.previousElementSibling </script> </body> </html>
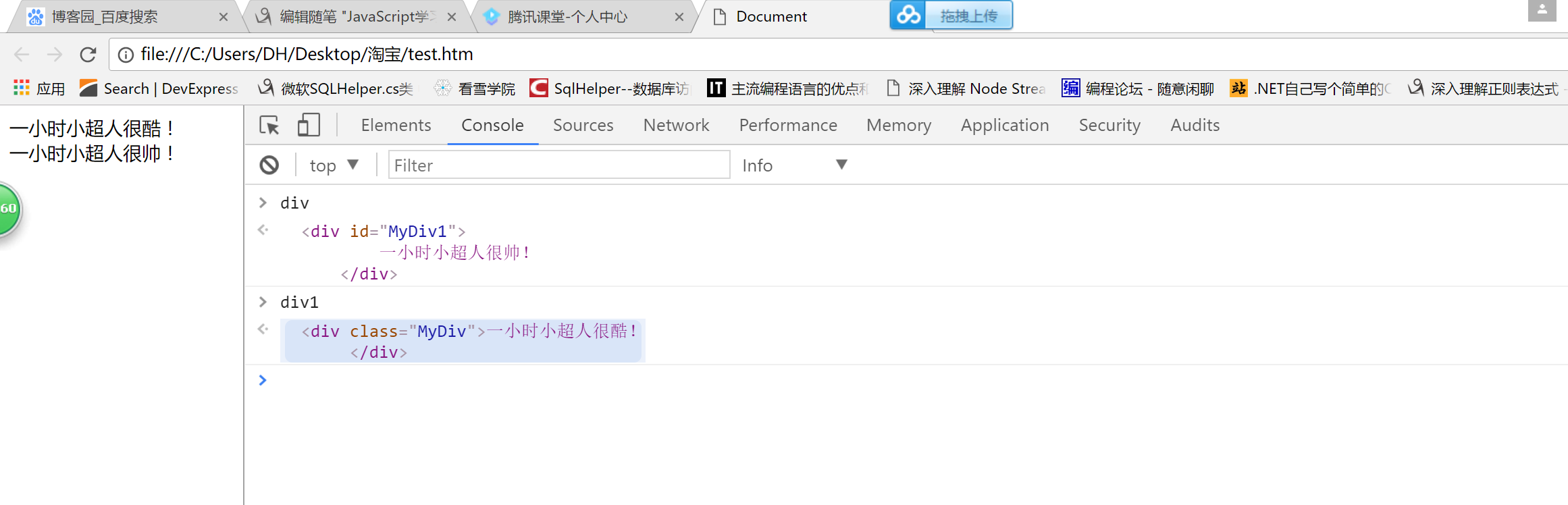
既然我们实际中用的是遍历节点树。那怎么区分这个节点是我们想要的还是不是我们想要的呢?dom在节点上为我们提供了type属性让我们进行区分
节点的类型
元素节点 —— 1
属性节点 —— 2
文本节点 —— 3
注释节点 —— 8
document —— 9
DocumentFragment —— 11
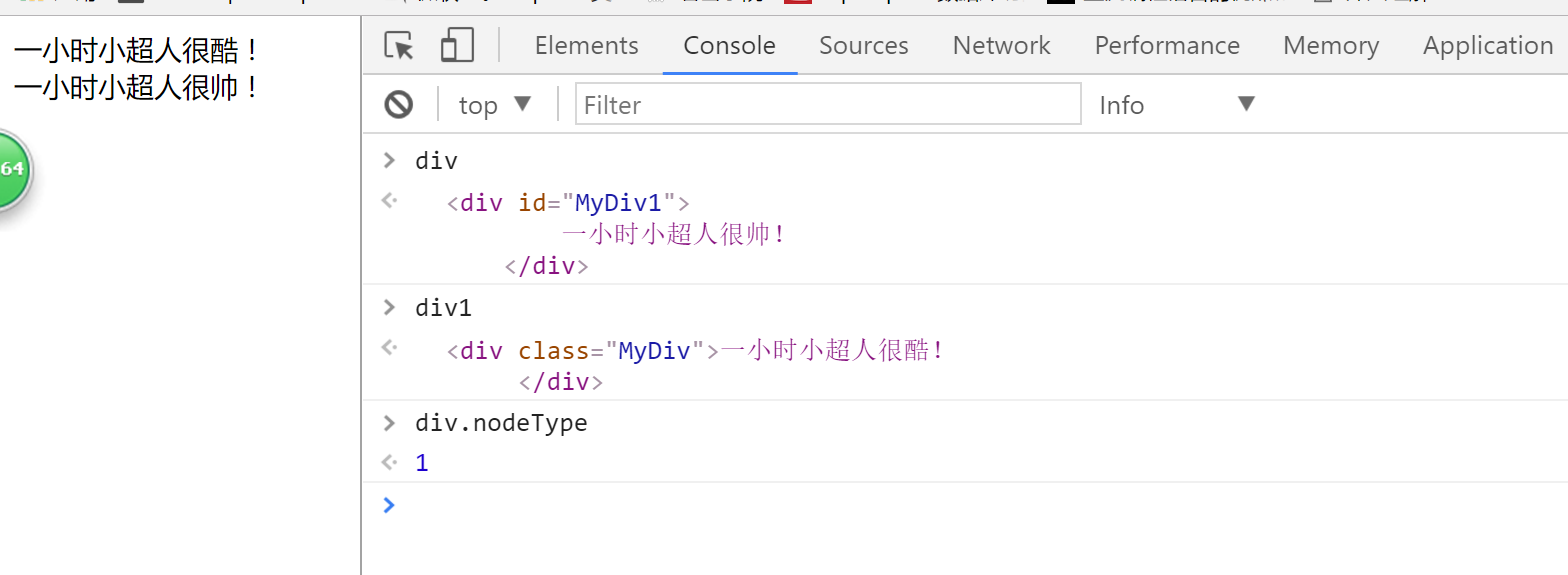
获取节点类型 nodeType
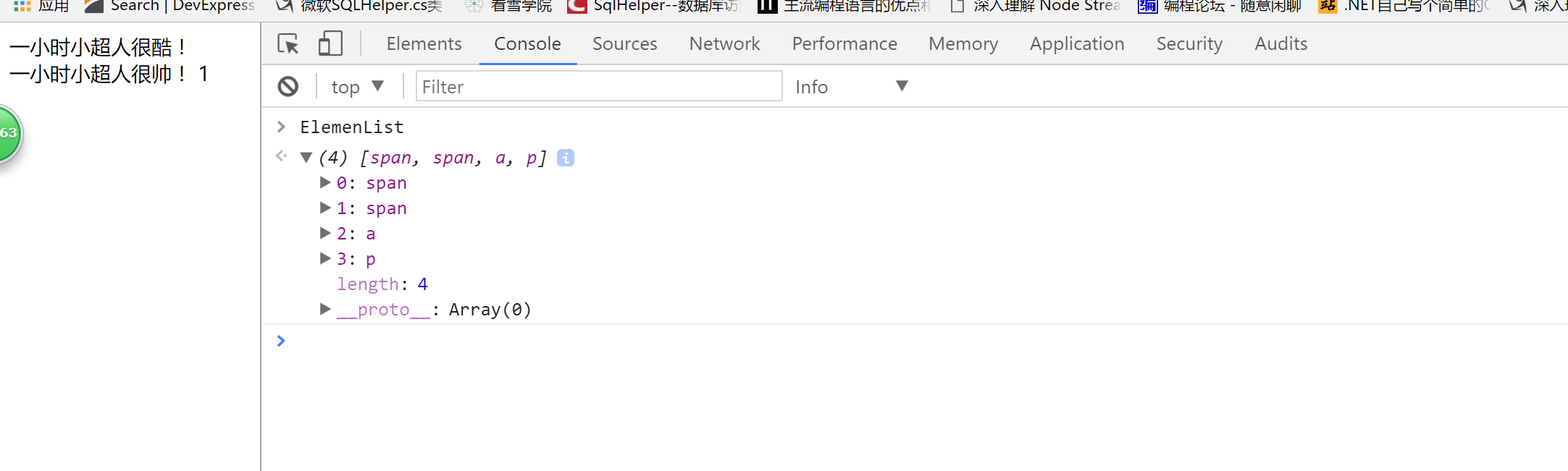
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <meta http-equiv="X-UA-Compatible" content="ie=edge"> <title>Document</title> </head> <body> <div class="MyDiv">一小时小超人很酷! </div> <div id="MyDiv1"> 一小时小超人很帅! <span>1</span> <span><a href=""></a></span> <a href=""></a> <p></p> </div> <script type="text/javascript"> var div=document.getElementById('MyDiv1') var div1=div.previousElementSibling var Elements=div.childNodes; var ElemenList=[]; for(var i=0;i<Elements.length;i++) { if(Elements[i].nodeType==1) { ElemenList.push(Elements[i]) } } </script> </body> </html>
三.小结
好好学习,天天向上

 浙公网安备 33010602011771号
浙公网安备 33010602011771号