
数据结构学习笔记(更新ing)
数据结构学习笔记(更新ing)
前言
本文最初写于去年数据结构课程学习伊始,最近对笔记进行了部分的排版和重构,有时间我会继续完善的,谢谢家人萌!
参考教材:《数据结构(C语言版)》 严蔚敏 著
第一章 绪论
第二章 线性表
2.1 线性表的类型定义
2.1.1 线性表的定义
什么是线性表
线性表是n 个类型相同数据元素的有限序列, 通常记作(a1 , a2 , a3 , …, an )。
线性结构的基本特征
01 集合中必存在唯一的一个“第一元素”。
02 集合中必存在唯一的一个 “最后元素”。
03 除最后元素之外,均有唯一的后继。
04 除第一元素之外,均有唯一的前驱。
线性结构的抽象数据类型描述
ADT List {
数据对象:D={ ai | ai ∈ElemSet, i=1,2,...,n, n≥0 }
{称 n 为线性表的表长; 称 n=0 时的线性表为空表。}
数据关系:R1={ |ai-1 ,ai∈D, i=2,...,n }
基本操作
}ADT List
线性表的基本操作
InitList(&S) //构造一个空的线性表L
DestroyList(&S) //销毁线性表L
ListEmpty(S)//判断L是否空
ListLength(S) //求L的长度
PirorElem(L,cur_e,&pre_e) //求前驱的值
NextElem(L,cur_e,&next_e) //求后驱的值
GetElem(L,i&e) //取i位置的值
LocateElem(L,e,compare()) //在线性表中查找e
ListTravelse(L,visit()) //遍历线性表
ClearList(&L) //清空线性表
ListInsert(&L,i,e) //在i位置插入e
ListDelete(&L,i,&e) //删除i位置的元素
静态数组和动态数组的说明
静态数组
typedef struct{
Elemtype data[30];
int length;
int listsize;
}SqList;
动态数组
typedef struct{
Elemtype *elem;
int length;
int listsize;
}SqList;
SqList L; //声明线性表变量L
L.elem = (ElemType*)malloc(30*sizeof(ElemType));
L.data 是数组名
L.elem 是数组名
2.1.2 基本操作的应用
基本操作的应用 例2-1
#include<stdio.h>
/*题目概述:
假设:有两个集合A和B分别用两个线性表LA和LB表示,即:线性表中的数据元素即为集合中的成员。
现要求一个新的集合A=AUB。
*/
void union(List &La,List Lb){
La_len=ListLength(La);
La_len=ListLength(Lb); //求线性表的长度
for(i=1;i<=Lb_len;i++){
GetElem(Lb,i,e); //对Lb进行遍历,取Lb中第i个元素赋给e
if(!LocateElem(La,e,equal())) //判断条件:La中元素与Lb中元素相等,然后作非运算
ListInsert(La,++La_len,e); //将La中不存在和e相同的元素插入进去
}
}
/*时间复杂度分析:O(ListLength(La)*ListLength(Lb))
整体结构为一个循环嵌套一个条件判断,
循环体中第7行对Lb做遍历,所以复杂度为ListLength(Lb),
条件判断中对La中每一个元素做检验,所以复杂度为ListLength(La)
基本操作的应用 例2-2
#include<stdio.h>
/*题目概述:
将两个“数据元素按值递增有序排列”的线性表La和Lb归并到线性表Lc中,且Lc具有同样的性质。
*/
void MergeList(List La,List Lb,List &Lc){
InitList(Lc); //构造空的线性表Lc
La_len=ListLength(La);
Lb_len=ListLength(Lb);
while((i<=La_len)&&(j<=Lb_len)){ //当i和j均<=各自对应表长,保证La和Lb均不为空
GetElem(La,i,ai);
GetElem(Lb,i,bi); //获取元素位置
if(ai<=bj){ //将ai插入到Lc中
ListInsert(Lc,++k,ai);
++i;
}else{ //将bi插入到Lc中
ListInsert(Lc,++k,aj);
++j;
}
//有一方元素达到表长,此时只剩下一个线性表中有元素没有插入
while(i<=La_len){ //当La不空时
GetElem(La,i,ai);
ListInsert(Lc,++k,ai);
} //插入La表中剩余元素
while(i<=Lb_len){ //当Lb不空时
GetElem(Lb,j,bj);
ListInsert(Lc,++k,bj);
} //插入Lb表中剩余元素
}
}
/*时间复杂度分析:O(ListLength(La)+ListLength(Lb))
2.2 线性表的顺序表示和实现
2.2.0 前言
存储线性表,就是要保存至少两类信息:
01 线性表中的数据元素
02 线性表中数据元素的顺序关系
2.2.1 线性表的顺序表示
定义
以数据元素x 的存储位置和数据元素 y 的存储位置之间的某种关系表示逻辑关系<x,y>。
线性表的顺序表示最简单的一种顺序映象方法是:令x的存储位置和y 的存储位置相邻。
图示
用一组地址连续的存储单元依次存放线性表中的数据元素

数据元素地址之间的关系
以“存储位置相邻”表示有序对时, ai-1和ai的地址关系如下:
LOC(ai ) = LOC(ai-1 ) + C
// C为一个数据元素所占存储量
所有数据元素的存储位置均取决于第一个数据元素的存储位置。
LOC(ai ) = LOC(a1 ) + (i-1)×C
// LOC(a1 )表示基地址
顺序表的实现
01 数据元素的数据类型Elemtype实现
02 顺序表数据类型的实现
03 顺序表的实现
04 顺序表数据类型的动态数组
实现表格的顺序存储
#include<stdio.h>
/*步骤:
1.数据元素的数据类型Elemtype实现
2.顺序表数据类型的实现
3.顺序表的实现
*/
//第一步 方式1:
typedef data{
char name[8];
int age;
char sex[2];
float score;
};
typedef struct data Elemtype;
//第一步 方式2:
typedef struct data{
char name[8];
int age;
char sex[2];
float score;
}Elemtype;
//第一步 方式3:
typedef struct {
char name[8];
int age;
char sex[2];
float score;
}Elemtype;
//第二步 方式1 静态数组实现:
typedef struct {
Elemtype data[30];
int length;
int listsize;
}SqList; //SqList现在是一个顺序表数据类型
//第三步
SqList L;
//第i个人的信息存储在:
L.data.[i].name;
L.data.[i].age;
L.data.[i].sex;
L.data.[i].score;
//表信息:
L.length; //线性表长度
L.listsize; //线性表规模
2.2.2 基本操作的实现
构造一个空线性表
Status InitList_Sq(SqList &L){ L.elem=(ElemType*)malloc(LIst_INIT_SIZE*sizeof(ElemType)); if(!L.elem) exit(OVERFLOW); L.length=0; L.listsize=LIST_INIT_SIZE; return OK;} //InitList_Sq/*应用时:先声明线性表变量Sqlist L; 然后调用函数InitList_Sq(L);
销毁线性表
Status DestroyList(SqList &L){ free(L.elem); return OK;} //InitList_Sq;
判断线性表是否为空
Status ListEmpty(SqList L){ if(L.length==0) return TRUE; else return FALSE;} //InitList_Sq
求线性表的表长
Status ListLength(SqList L){ return L.length;}//InitList_Sq
求前驱的值
Status PriorElem(SqList L,int cur_e,Elemtype &pre_e){ if(cur_e<=0||L.length==0||cur_e>L.length) return error; else pre_e=L.elem[cur_e-1];}/*应用时,线性表L变量cur_e必须赋值;同时声明变量Elemtype a;调用方式:PriorElem(L,cur_e,a);*/
插入操作算法
p=//数组下标控制Status ListInsert_Sq(SqList&L,int i,ElemType){ //在顺序表L的第i个元素之前插入新的元素e for(j=L.length-1;j>=i-1;--j) L.elem[j+1]=L.elem[j]; L.elem[i-1]=e; ++L.length //表长+1 return OK;}//ListInsert__Sq//指针控制Status ListInsert_Sq(SqList&L,int i,ElemType){ //在顺序表L的第i个元素之前插入新的元素e q=&(L.elem[i-1]); for(p=&(L.elem[L.length-1]);p>=q;--p) *(p+1)=*p; *q=e; ++L.length; return OK;}//ListInsert_Sq//插入操作算法if(i<1||i>L.length+1)return ERROR; //插入位置不合法if(L.length>=L.listsize){ //当前存储空间已满,增加分配 newbase=(ElemType*)realloc(L.elem,(L.list+LISTINCREMENT*sizeof(ElemType))); if(!newbase) exit(OVERFLOW); //存储分配失败 L.elem=newbase; //新基址 L.listsize+=LISTINCREMENT; //增加存储容量}//指针控制举例ListInsert_Sq(L,5,66)q=&(L.elem[i-1]); //q指示插入位置for(p=&(L.elem[L.length-1]);p>=q;--p) *(p+1)=*p;
删除操作
//指针控制Status ListDelet_Sq(SqList&L,int i,ElemType &e){ if((i<1)||(i>L.length)) return ERROR; //删除位置不合法 p=&(L.elem[i-1]); //p为被删除元素的位置 e=*p; //被删除元素的值赋给e q=L.elem+L.length-1; //表尾元素的位置 for(++p;p<=q;++p) *(p-1)=*p; //被删除元素之后的元素左移 --L.length; //表长减1 return OK;}//ListDelete_Sq//数组下标控制Status ListDelet_Sq(SqList&L,int i,ElemType &e){ if((i<1)||(i>L.length)) return ERROR; //删除位置不合法 e=L.elem[i-1]; //记录删除的元素 for(j=i-1;j<L.length-1;j++) L.elem[j]=L.elem[j+1]; --length; //表长减1 return OK; //元素左移}//ListDelete_Sq//指针控制举例ListDelete_Sq(L,5,e)p=&(L.elem[i-1]);q=L.elem+L.length-1;for(++p;p<=q;++p) *(p-1)=*p;
单链表的C语言实现
Typedef struct LNode { ElemType data; // 数据域 struct LNode *next; // 指针域} LNode, *LinkList; 技术上:LinkList和Lnode * 等价 参考整数类型int和指针类型int *typedef int* intp; intp a; 上述两句等价于int *a; 语义:Lnode用来定义节点LinkList用来定义链表(头指针)定义节点、定义链表定义节点:LNode L; 两个域的表示方法分别为:数据域 L.data;指针域 L.next;定义链表:LinkList L(等价于 LNode *L)L = (LNode*) malloc(sizeof (LNode));两个域的表示方法分别为:数据域 L->data;指针域 L->next;
构造一个空的带头节点的线性表L
InitList(&L) //构造一个空的带头节点的线性表LLinkList L;void InitList(LinkList &L){ L = NULL;}void InitList(LinkList &L){ L = (Lnode*)malloc(sizeof(Lnode)); L->next = NULL;}
取单链表中某位置的值
GetElem_L(LinkList L,int i,ElemType &e)
在单链表某位置插入新元素
单链表操作的实现 Status ListInsert_L(LinkList L,int i,ElemType e) //L为带头结点的单链表的头指针,本算法在链表中第i个结点之前插入新的元素e插入过程 1.查找第i-1个个结点p; 2.生成结点s,存入e; 3.s->next = p->next; p->next = s;Status ListInsert_L(LinkList L,int i,ElemType &e){ //L为带头结点的单链表的头指针,本算法在链表中第i个结点之前插入新的元素e p = L; j = 0; while(p && j<i-1){ p = p->next; ++j; } //寻找第i-1个结点 if(!p || j>i-1) {return ERROR; } //i大于表长或者小于1 s = (LinkList)malloc(sizeof(LNode)); s->data = e; s->next = p->next; p->next = s; //插入} //ListInsert_L//算法的时间复杂度为O(ListLength(L))
对单链表中某元素实现删除操作
单链表操作的实现 ListDelete_L(LinkList L, int i, ElemType &e) //L为带头结点的单链表的头指针,本算法删除链表中第i个结点,值储入e删除过程 1.查找第i-1个结点p; 2.q=p->next; p->next=q->next; 3.e=q->data; free(q);Status ListDelete_L(LinkList L, int i, ElemType &e){ p = L; j = 0; while(p->next && j<i-1) { p = =->next; ++j; } //p的后继代表要删除的元素,因此p->next不能为空 if(!(p->next)||j>i-1) return ERROR; //i不在1和表长之间 //删除位置不合理 q = p->next; p->next = q->next; e = q->data; free(q); return OK;} //ListDelete_L//算法的时间复杂度为O((ListLength(L))
将单链表重新置为一个空表
void ClearList(&L){ // while(L->next){ p = L->next; L->next = p->next; free(p); }} //ClearList//算法的时间复杂度为O((ListLength(L))
建立单链表——头插法
例如:建立三个元素a,b,c的单链表 L [\\\| ^ ] ——> [ a | ^ ] | \ | [ c | ] ——> [ b | ]p = (LNode *)malloc(sizeof(LNode));p->data = e;p->next = L->next;L->next = P;生成链表的过程是一个结点“逐个插入”的过程//单链表的头插法建表有什么特点?
建立单链表——尾插法
例如:建立三个元素a,b,c的单链表 L [\\\| ^ ] ——> [ a | ^ ] ——> [ b | ] ——> [ c | ^ ]r=L;p = (LNode *)malloc(sizeof(LNode));p->data = e;r->next = p;r = p;r->next = NULL;//单链表的头插法建表有什么特点?
单链表和循环链表操作比较
设两个链表La=(a1 ,a2 ,...,an )和Lb=(b1 ,b2 ,...bm),讨论如下问题:1.La、Lb都是带头结点的单链表,如何实现将Lb接在La 之后?时间复杂度是多少? 答:La、Lb都是带头结点的单链表,Lb接在La之后,时间复杂度是 O(length(La)) R = La; R->next = Lb->next; While(R->next) free(Lb) R = R->next; 2.La、Lb都是带头结点头指针的单循环链表,如何实现将Lb接在La之后还形成一个循环链表?时间复杂度是多少? 答:La、Lb都是带头结点头指针的单循环链表,实现将Lb接在La之后还形成一个循环链表,时间复杂度是 O(length(La)+length(Lb)) R1 = La; R2 = Lb; R1->next = Lb->next; While(R1->next!=La) While(R2->next!=Lb) R2->next = La; R1 = R1-next; R2 = R2-next; free(Lb); 3.La、Lb都是带头结点尾指针的单循环链表,如何实现 将Lb接在La之后还形成一个循环链表?时间复杂度是多少? 答:La、Lb都是带头结点尾指针的单循环链表,实现将Lb接在La之后还形成一个循环链表,时间复杂度是 O(1) L1 = La-next; Lb->next = L1; L2 = Lb-next; free(L2); La->next = L2->next;
双向链表的C语言实现
//类型定义typedef struct DuLNode{ ElemType data; struct DuLNode *prior; struct DuLNode *next;} DuLNode,*DuLinkList;
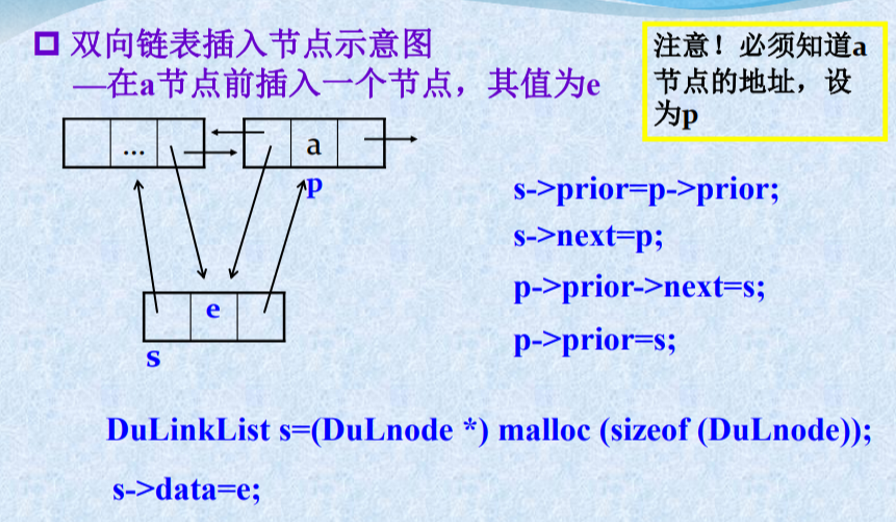
双向链表的插入算法
Status ListInsert_Dul(DuLinkList &L,int i,ElemType e){ if(!(p=GetElemP_DuL(L,i))) return error; if(!(s=(DuLinkList)malloc(sizeof(DuLNode)))) return error; s->data = e; s->prior = p->prior; s->next = p; p->prior->next = s; p->prior = s; return OK;}
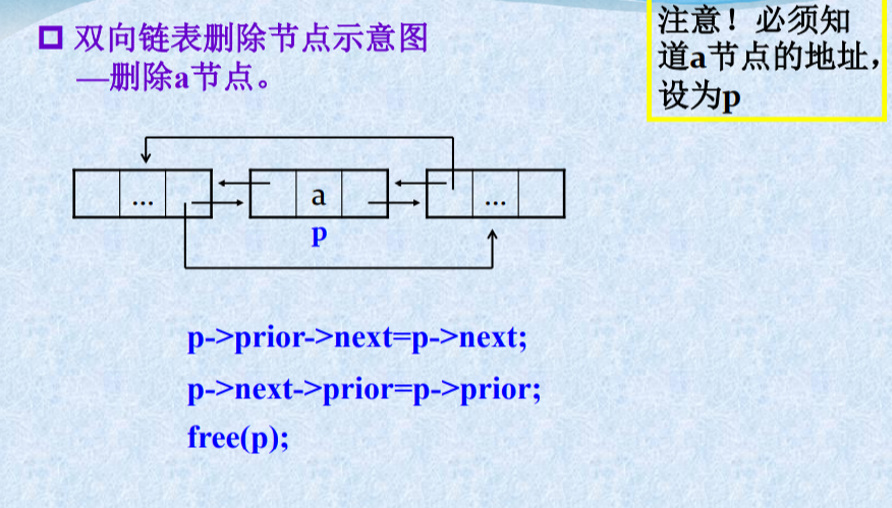
双向链表的删除算法
Status ListDelete_Dul(DuLinkList &L,int i,ElemType e){ if(!(p=GetElemP_DuL(L,i))) return error; e = p->data; p->prior->next = p->next; p->next->prior = p->prior; free(p); return OK;}
2.2.3 基本操作的分析
插入操作
1.插入操作过程示意图
2.插入操作算法
数组下标控制
指针控制
插入算法时间复杂性分析
删除操作算法
1.删除操作过程示意图
2.删除操作算法
数组下标控制
指针控制
删除算法时间复杂性分析
2.2.4 顺序表的优缺点
优点
01 节省存储空间
02 对线性表中第i个结点的操作易于实现
03 容易查找一个结点的前驱和后继
缺点
01 插入和删除操作需要移动数据
02 建立空表时,较难确定所需的存储空间
2.3 线性表的链式表示和实现
2.3.1 单链表
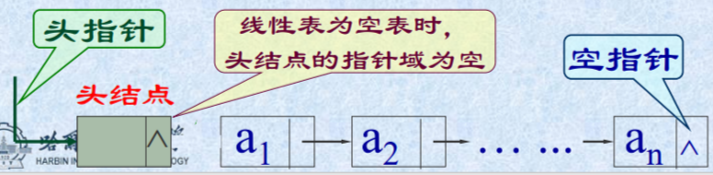
单链表的结构示意图

链表的定义
一个线性表由若干个结点组成,每个结点至少含有两个域:
数据域(信息域)和 指针域(链域),
由这样的结点存储的线性表称作链表。
结构特点
01 逻辑次序和物理次序不一定相同。
02 元素之间的逻辑关系用指针表示。
03 需要额外空间存储元素之间的关系。
头指针的概念
在链式存储结构中以第一个结点的存储地址作为线性表的基地址,通常称它为“头指针”。
线性表的最后一个数据元素没有后继,因此最后一个结点中的“指针域"是一个特殊的值"NULL",通常称它为"空指针" 。

头结点
01 头结点的概念
在单链表上设置一个结点,它本身不存放数据,它的指针域指向第一个元素的地址。
02 头结点的作用
使对第一个元素的操作与对其它元素的操作保持一致。

单链表的基本操作的实现分析
1.构造一个空的带头节点的线性表L
2.取单链表中某位置的值
3.在单链表某位置插入新元素
4.对单链表中某元素实现删除操作
5.建立单链表——头插法
6.建立单链表——尾插法
链表的优缺点
优点
01 插入和删除不需要移动数据(时间复杂性低)。
02 不需预先分配空间。
缺点
01 指针占用存储空间,增加了内存负担。
02 只能顺序查找(操作)。
2.3.2 静态链表
2.3.3 循环链表
循环链表示意图
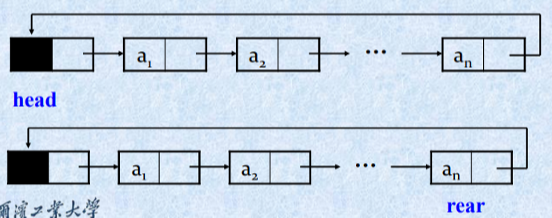
循环链表的概念
单链表最后一个结点的指针域没有利用,如果使其指向头指针(头结点),则首尾构成一个循环,称作循环链表。
循环链表的优点
从表中任一结点出发均可找到表中其它结点。
讨论:在循环链表中多采用尾指针?为什么?
什么是尾指针?
指向表尾的指针称为是尾指针。
讨论:在循环链表中多采用尾指针?为什么?
结论:采用头指针时,查找第一个结点容易,查找尾结 点不容易,如果采用尾指针,则查找第一个结点和最后 一个结点都容易。
单链表和循环链表操作比较
2.3.4 双向链表
双向链表的概念
一个链表的每一个结点含有两个指针域:一个指针指向其前驱结点,另一个指针指向其后继结点,这样的链表称为双向链表。
双向链表的结构示意图

双向链表的优缺点
优点:可以双向查找线性表。
缺点:进一步增加了内存负担,操作难度加大了。
双向链表的C语言实现
双向链表中地址关系
在双向链表中:
p->prior指向p的前驱,p->next指向p的后继
以下都是p结点的地址:
p->next->prior 和 p->prior->next
双向链表的操作特点
查询” 和单链表相同。
“插入” 和“删除”时需要同时修改两个方向上的 指针。
双向链表插入节点示意图
双向链表删除节点示意图
双向链表的插入算法
双向链表的删除算法
第三章 栈和队列(栈PART)
3.1 栈
栈的示意图
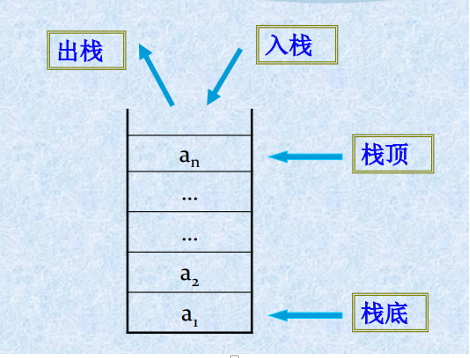
栈的特点
后进先出(Last In First Out,简称LIFO)。
又称栈为后进先出表(简称LIFO结构)。
栈的定义
栈是一种特殊的线性表,其插入和删除操作均在表的一端进行,是一种运算受限的线性表
栈的术语
栈顶是栈中允许插入和删除的一端。
栈底是栈顶的另一端
抽象数据类型栈的定义
ADT Stack { 数据对象: D={ ai | ai ∈ElemSet, i=1,2,...,n, n≥0 } 数据关系:R1={ | ai-1 , ai∈D, i=2,...,n } 约定an 端为栈顶,a1 端为栈底。 基本操作: 如下。 } ADT Stack
栈的基本操作
InitStack(&S) //初始化栈DestroyStack(&S) //销毁栈StackEmpty(S)//判断栈是否空StackLength(S) //求栈长度GetHead(S,&e) //取队头元素ClearStack(&S) //清空队列EnStack(&S) //入栈DeStack(&S) //出栈 StackTravers(S,visit()) //遍历栈
3.2 栈的表示和实现
3.2.0 前言

3.2.1 顺序栈

1.顺序表示的实现
2.顺序栈的C语言实现
3.栈初始化过程演示
4.栈初始化算法
5.入栈操作演示
6.出栈操作演示
7.其他栈操作讨论
3.2.2 链栈
1.链栈的实现与链表的实现基本相同,头结点作为栈顶位置。
2.链栈的C语言类型定义
3.链栈初始化
4.入栈操作
5.出栈操作
6.讨论链栈基本操作的实现
栈的顺序存储表示
#define STACK_INIT_SIZE 100;//栈容量#define STACKINCREMENT;//栈增量//stack 栈;increment 增量;typedef struct{ SElemType *base; //基地址:在栈构造之前和销毁之后,base的值为NULL SElemType *top; //栈顶指针:栈顶指针减去基地址就可以得到栈里元素的个数 int stacksize; //栈容量}SqStack;Sqstack S;
栈的初始化算法
Status InitStack(SqStack &S){ //status 地位,状态;init 初始化;//构造一个空栈SS.base=(SElemType*)malloc(STACK_INIT_SIZE*sizeof(SElem Type));if(!S.base)exit(OVERFLOW) //存储分配失败S.top=S.base;S.stacksize=STACK_INIT_SIZE;Return ok;}
入栈操作演示
//如果栈满,给栈增加容量 if(S.top-S.base >= S.stacksize){ S.base=(SElemTpye*)realloc( S.base,(S.sracksize+STACKINCREMENT)*sizeof(SElemTpye) ); if(!S.base){ exit(OVERFLOW)}; //存储分配失败 S.top=S.base+S.stacksize; S.stacksize+=STACKINCREMENT; }//将数据存入栈顶位置,栈顶后移一位 *S.top=e; S.top++; Status Push(Sqstack &S,Selem Tpye e){ if(S.top - S.base >= S.stacksize + STACKINCREMENT)*sizeof(Elem Tpye)); if(!S.base){ exit(OVERFLOW); //存储分配失败 *S.top++=e; return OK; }//如果栈空,返回 if(S.top==S.base) return error;//否则:记录栈顶前面
出栈操作演示
//1.如果栈空,返回 if(S.top==S.base) return error;//2.否则:记录栈顶前面位置的值,栈顶位置减1 e=*(S.top-1); S.top--;Status Pop(SqStack&S,SElemType&e){ if(S.top==S.base) return error; else{ e=*(S.top-1); S.top--; return OK; }}
链栈的C语言类型定义
Typrdef struct Snode{ SelemType data; //数据域 struct Snode *next; //链域}Snode,*LinkStack;
链栈的初始化
LinkStack S;void InitStack(LinkStack &S){ S = (Snode*)malloc(sizeof(SNode)); if(!S) exit(OVERFLOW); //存储分配失败 S->next = NULL;}
链栈的入栈操作
void Push(LinkStack &S,SelemType e){ p = (Snode*)malloc(sizeof(SNode)); p->data = e; p->next = S->next; S->next = p;}//链栈的入栈操作与头插法建立单链表的方式一致
链栈的出栈操作
void Pop(LinkStack &S,SElemType &e){ if(S->next==NULL) return error; p = S->next; e = p->data; S->next = p->next; free(p);}//链栈的出栈操作等于删除单链表的哪一个元素?
队列的基本操作
InitQueue(&Q) //初始化队列DestroyQueue(&Q) //销毁队列QueueEmpty(Q)//判断队列是否空QueueLength(Q) //求队列长度GetHead(Q,&e) //取队头元素ClearQueue(&Q) //清空队列EnQueue(&Q) //入队列Dequeue(&Q) //出队列QueueTravers(Q,visit()) //遍历队列
3.3 栈的应用举例
数制转换
进制转换原理
10进制数N转换成8进制的算法
括号匹配的检验
问题描述
问题讨论
算法过程
括号匹配检验算法
行编辑程序问题
迷宫求解
问题描述
用栈实现迷宫路径求解的过程
四周墙壁解决办法如图
从某一点 [x] [y] 出发搜索其四周的邻点
表达式求值
问题描述
表达式求值
算法求解过程
第三章 栈和队列(队列PART)
3.4 队列
3.4.1 抽象数据类型队列的定义
队列示意图
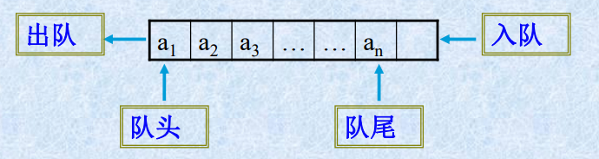
队列的特点
先进先出(First In First Out ,简称FIFO)。
又称队列为先进先出表(简称FIFO结构)。
队列的定义
队列是一种运算受限的特殊的线性表,它只允许在表的一端进行插入,而在表的另一端进行删除。
队列的术语
队尾(rear)是队列中允许插入的一端。
队头(front)是队列中允许删除的一端。
抽象数据类型队列
ADT Queue { 数据对象:D = {ai | ai∈ElemSet,i=1,2,…,n,n≥0}数据关系:R1={<ai-1,ai> | ai-1,ai∈D,i=2,…,n} //约定其中 a1 端为队列头,an 端为队列尾 基本操作 }ADT Queue
队列基本操作
InitQueue(&Q) //初始化队列DestroyQueue(&Q) //销毁队列QueueEmpty(Q) //判断队列是否空QueueLength(Q) //求队列长度GetHead(Q,&e) //取队头元素ClearQueue(&Q) //清空队列EnQueue(&Q) //入队列DeQueue(&Q) //出队列QueueTravers(Q,visit()) //遍历队列
3.4.2 链队列
链队列结点实现
typedef struct QNode{ //结点类型 QElemType data; struct QNode *next;}QNode,*QueuePtr;
链队列数据类型实现
typedef struct{ //链队列类型 QueuePtr front; //队头指针 QueuePtr rear; //队尾指针}LinkQueue;
//为什么链队列常用两个指针?
带头结点的链队列示意图
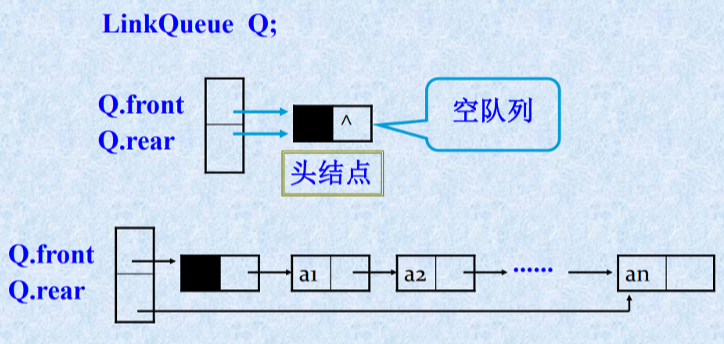
带头结点的链队列初始化

带头结点的链队列入队算法示意图
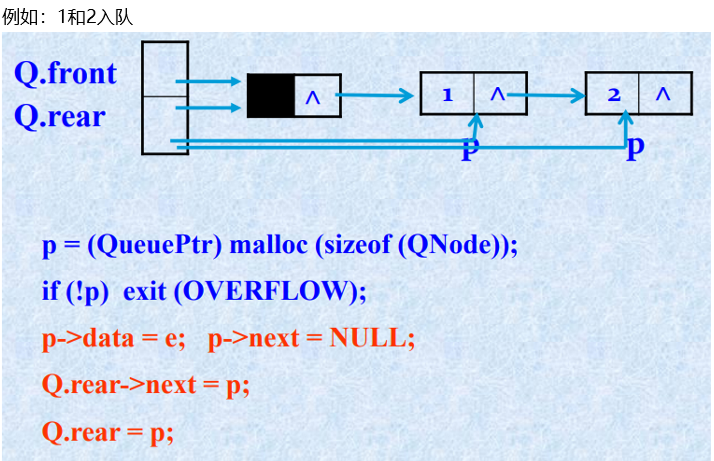
带头结点的链队列入队算法

带头结点的链队列出队算法示意图
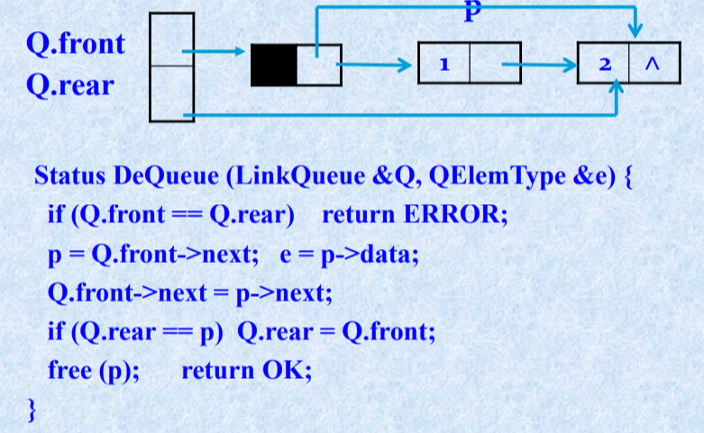
3.4.3 循环队列
顺序队列数据类型实现

顺序队列讨论
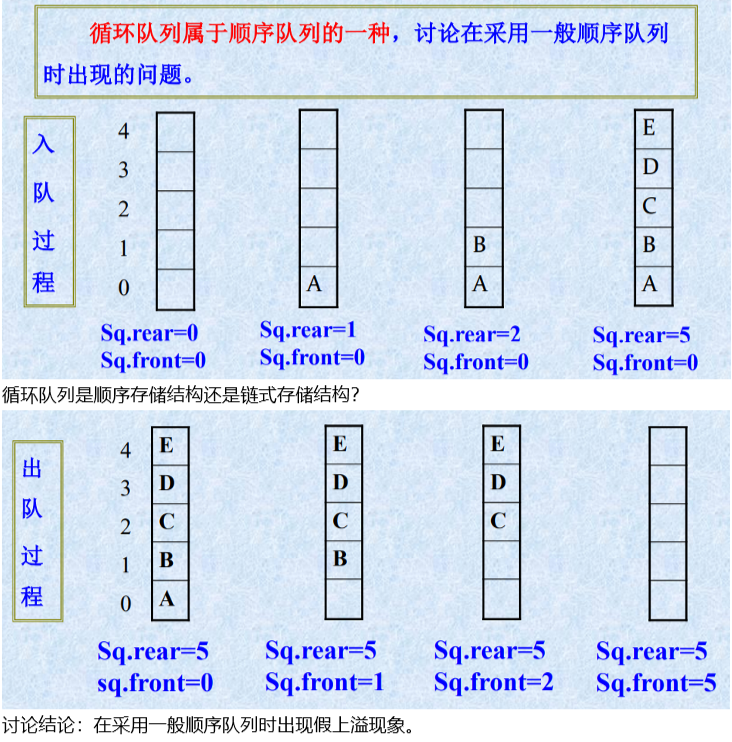
循环队列数据类型实现

循环队列的定义
循环队列是顺序队列的一种特例,它是把顺序队列构造成一个首尾相连的循环表。
指针和队列元素之间关系不变。
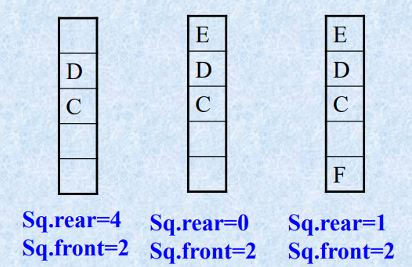
循环队列空状态和满状态的讨论
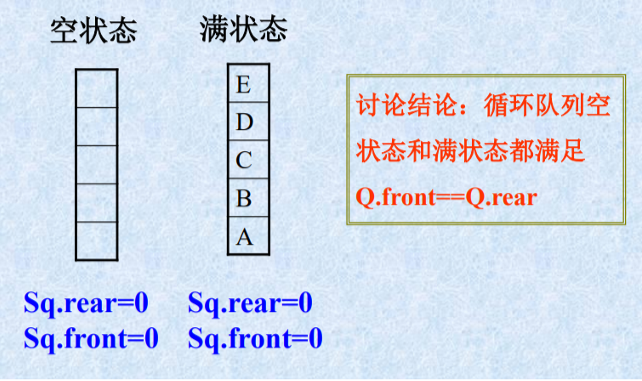
循环队列空状态和满状态的判别

队列初始化算法

入队列算法

出队列算法

求队列长度算法
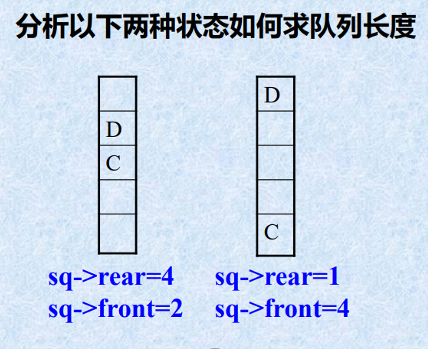
int QueueLength(SqQueue Q){ return (Q.rear - Q.front + MaxSize)%MaxSize;}
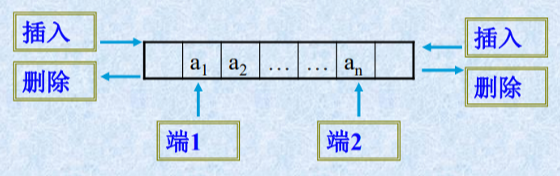
3.4.4 双端队列
双端队列的引入

双端队列定义
双端队列是一种特殊的线性表,特殊在限定插入和删除操作只能在表的两端进行。
双端队列示意图
第四章 串(模式匹配算法PART)
4.2 串的表示和实现
定长顺序存储表示
串的顺序存储C语言实现
#define MAXSTRLEN 255 // 用户可在255以内定义最大串长typedef unsigned char Sstring[MAXSTRLEN+1] (存疑) // 0号单元存放串的长度Sstring S;
堆分配存储表示
堆分配存储表示的C语言实现
typedef struct{ char *ch; // 若是非空串,则按串长分配存储区;否则ch为NULL int length; // 串长度} Hstring;
串的块链存储表示
01 链表存储字符串的讨论

02 串的快链存储的C语言实现
#define CHUNKSIZE 80typedef struct Chunk{ //结点结构 char ch[CHUNKSIZE]; srtuct Chunk *next;}Chunk;typedef struct{ //串的链表结构 Chunk *head,*tail; //串的头和尾指针 int curlen; //串的当前长度}Lstring;
4.3 串的模式匹配算法
4.3.1 串匹配(查找)的定义
串的模式匹配算法
串匹配(查找)的定义INDEX(S,T,pos)初始条件: 串S和T存在,T是非空串, 1<=pos<=StrLength(S)操作结果: 若主串S中存在和串T值相同的子串返回它在主串S中第pos个字符之后第一次出现的位置; 否则函数值为0
模式匹配简单算法
int Index(SString S, SString T, int pos) { int i = pos,j = 0; while (i < strlen(S) && j < strlen(T)) { if (S[i] == T[j]) { ++i; ++j; } // 继续比较后继字符 else{ i = i-j+2; j = 1; } // 指针回溯重新开始匹配 } if ( j>T[0] ) { return i-T[0]; } else return 0;} // Index
模式匹配KMP算法(textbook)
int Index_KMP(SString S,SString T,int pos ){ i=pos;j=1; while(i<=S[0] && j<=T[0]) if(j==0 || S[i]==T[j]){ i++;j++} else { j=next[j]; } //i不变,j后退 if(j>t[0]) return i-t[0]; //匹配成功 else return 0; //返回不匹配标志}
求next函数算法
void get_next(SString T,int next[]){ int j=1,k=0; next[1]=0; while(j<T[0]){ if(k==0 || T[j]==T[k]) { ++j; next[j]; } /* next[++j] = ++k */ else k=next[k]; /*T[j] != T[k]时,k跳转到next[k]*/ }}//初值j=1,k=0:表示一开始就匹配不上,是迭代计算next值的基础。/*代码中if的含义就是在 next[j]=k 的情况下,如果 T[j]==T[k] ,则 next[j+1]=k+1 或者 k=0时,让next[j+1]=1,表示 j>1 时候不存在相同的最长前后缀串即 ++k 后 k=1 即next公式的其他情况*/
第五章 数组广义表
三元组顺序表的实现
#define MAXSIZE 12500typdef struct{ int i,j; //该非零元的行下标和列下标 ElemType e; //该非零元的值}Triple; //三元组类型typedef struct{ Triple data[MAXSIZE+1]; //data[0]未用 int mu,nu,tu;}TSMatrix; //稀疏矩阵类型TSMatrix;
三元组顺序表的转值算法详解
Status TransposeSMaxtrix(TSMatrix M,TSMatrix &T){ int p,q,col; T.mu=M.nu; T.nu=M.mu; T.tu=M.tu; if(T.tu){ q=1; for(col=1;col<=M.nu;++col) for(p=1;p<=M.tu;++p) if(M.data[p].j==col){ T.data[q].i=M.data[p].j; T.data[q].j=M.data[p].i; T.data[q].e=M.data[P].e; ++q; } } return OK;}
广义表的头尾链表存储表示
typedef enum{ATOM,LIST}ELemTag;typedef struct GLNode{ ElemTag tag; union{ AtomType atom; struct{struct GLNode *hp,*tp;}ptr; }}*Glist;
扩展头尾指针结点结构
typedef enum {ATOM,LIST}ElemTag;typedef struct GLNode{ ElemTag tag; union{ AtomTpye atom; struct GLNode*hp; }; struct GLNode *hp;}
第六章 树和二叉树
6.1 树的类型定义
6.1.1 树的类型定义
数据对象D
D是具有相同特性的数据元素的集合。
数据关系R
若D为空集,则称为空树 。
否则:
1.在D中存在唯一的称为根的数据元素root;
2.当n>1时,其余结点可分为m (m>0)个互不相交的有限集T1 , T2 , …, Tm,
其中每一棵子集本身又是一棵符合本定义的树,称为根root的子树。
6.1.2 基本术语
结点
数据元素+若干指向子树的分支
结点的度
分支的个数
树的度
树中所有结点的度的最大值
叶子结点
度为零的结点
分支结点
度大于零的结点
路径
(从根到结点的)路径:由从根到该结点所经分支和结点构成
孩子结点、双亲结点
兄弟结点、堂兄弟结点
祖先结点、子孙结点
结点的层次
假设根结点的层次为1,第l层的结点的子树根结点的层次为l+1
树的深度
树中叶子结点所在的最大层次
森林
是m(m>=0)棵互不相交的树的集合
根结点和子树森林
任何一棵非空树是一个二元组
Tree = ( root , F )
其中:root被称为根结点;F被称为子树森林
6.1.3 对比树型结构和线性结构的结构特点
| 线性结构 | 树型结构 |
|---|---|
| 第一个数据元素 (无前驱) |
根结点 (无前驱) |
| 最后一个数据元素 (无后继) |
多个叶子结点 (无后继) |
| 其它数据元素 (一个前驱、一个后继) |
其它数据元素 (一个前驱、多个后继) |
6.2 二叉树的类型定义
6.2.1 二叉树的类型定义
二叉树或为空树。或是由一个根结点加上两棵分别称为左子树和右子树的、互不交的二叉树组成。
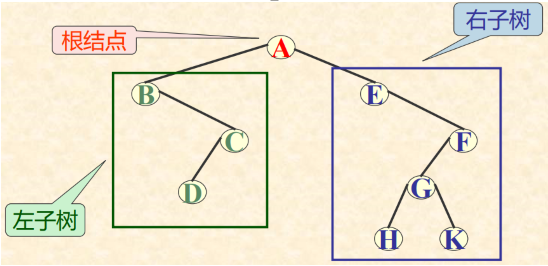
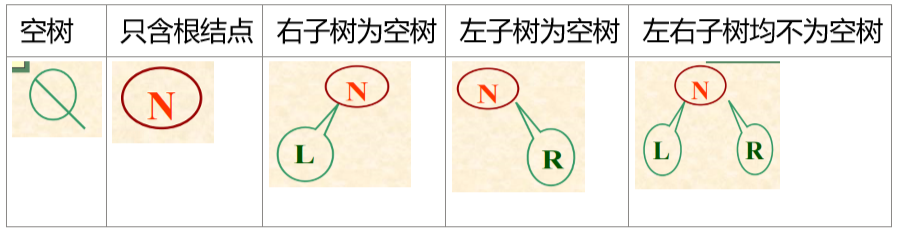
6.2.2 二叉树的五种基本形态
空树、只含根结点、右子树为空树、左子树为空树、左右子树均不为空树
6.2.3 树的主要基本操作
/*查找类操作-----------------------------------------------------------------*/Root(T);//初始条件:树T存在//操作结果:返回T的根Value(T,e);//初始条件:树T存在,e为T中某个结点//操作结果:返回e的值Parent(T,e);//初始条件:树T存在,e为T中某个结点//操作结果:返回e的双亲(若e是根结点,则函数值为“空”)LeftChild(T,e);//初始条件:树T存在,e为T中某个结点//操作结果:返回e的最左孩子(若e是叶子结点,则返回为“空”)RightChild(T,e);//初始条件:树T存在,e为T中某个结点//操作结果:返回e的最右孩子(若e是叶子结点,则返回为“空”)LeftSibling(T,e);//初始条件:树T存在,e为T中某个结点//操作结果:返回e的左兄弟(若e没有左兄弟,则函数值为“空”)RightSibling(T,e);//初始条件:树T存在,e为T中某个结点//操作结果:返回e的右兄弟(若e没有右兄弟,则函数值为“空”)BiTreeEmpty(T,e);//初始条件:树T存在//操作结果:若树T为空树,则返回TRUE;否则返回FALSEBitreeDepth(T,e);//初始条件:树T存在//操作结果:返回树的深度PreOrderTraverse(T,Visit());//初始条件:二叉树T存在,Visit是对结点操作的应用函数//操作结果:先序遍历T,对每个结点调用函数Visit一次且仅一次。一旦Visit()失败,则操作失败InOrderTraverse(T,Visit());//初始条件:二叉树T存在,Visit是对结点操作的应用函数//操作结果:中序遍历T,对每个结点调用函数Visit一次且仅一次。一旦Visit()失败,则操作失败PostOrderTraverse(T,Visit());//初始条件:二叉树T存在,Visit是对结点操作的应用函数//操作结果:后序遍历T,对每个结点调用函数Visit一次且仅一次。一旦Visit()失败,则操作失败LevelOrderTraverse(T,Visit());//初始条件:二叉树T存在,Visit是对结点操作的应用函数//操作结果:层序遍历T,对每个结点调用函数Visit一次且仅一次。一旦Visit()失败,则操作失败/*插入类操作---------------------------------------------------------------*/InitBiTree(&T);//操作结果:构造空二叉树TAssign(T,&e,value);//初始条件:二叉树T存在,e是T中某个结点//操作结果:结点e赋值为valueCreateBiTree(&T,definition);//初始条件:definition给出二叉树T的定义//操作结果:按definition构造二叉树TInsertChild(T,p,LR,c);//初始条件:二叉树T存在,p指向T中某个结点,LR为0或1,非空二叉树c与T不相交且右子树为空//操作结果:根据LR为0或1,插入c为T中p所指结点的左或右子树。p所指结点的原有左或右子树则称为c的右子树/*删除类操作----------------------------------------------------------------*/ClearBiTree(&T);//初始条件:二叉树T不存在//操作结果:将二叉树T清为空树DestroyBiTree(&T);//初始条件:二叉树T存在//操作结果:销毁二叉树TDeleteChild(T,p,LR);//初始条件:二叉树T存在,p指向T中某个结点,LR为0或1//操作结果:根据LR为0或1,删除c为T中p所指结点的左或右子树
6.2.4 二叉树的重要特性
性质1
在二叉树的第 i 层上至多有 2^(i-1)个结点。 (i≥1)
性质2
深度为 k 的二叉树上至多含 2^(k -1)个结点。(k≥1)
性质3
对任何一棵二叉树,若它含有n0 个叶子结点、n2 个度为2的结点,则必存在关系式:n0 = n2+1
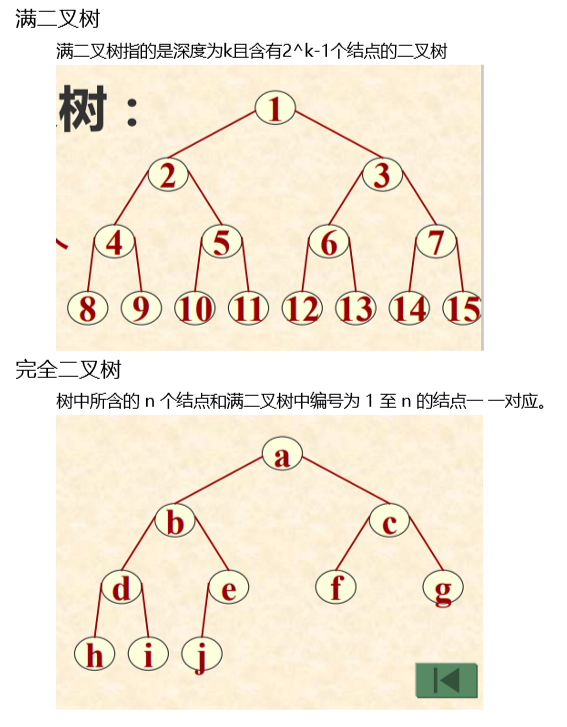
两类特殊的二叉树
性质4
具有 n 个结点的完全二叉树的深度为 [log2n] +1 。
性质5
若对含 n 个结点的完全二叉树从上到下且从左至右进行 1 至 n 的编号,
则对完全二叉树中任意 一个编号为 i 的结点:
1.若 i = 1 ,则该结点是二叉树的根,无双亲;
否则,编号为 [i/2] 的结点为其双亲结点。
2.若 2i > n ,则该结点无左孩子;
否则,编号为 2i 的结点为其左孩子结点。
3.若 2i+1 > n ,则该结点无右孩子结点;
否则,编号为 2i+1 的结点为其右孩子结点。
6.3 二叉树的存储结构
6.3.1 二叉树的顺序存储
#define MAX_TREE_SIZE 100 // 二叉树的最大结点数typedef TElemType SqBiTree[MAX_TREE_SIZE]; // 0号单元存储根结点SqBiTree bt;
6.3.2 二叉树的链式存储表示
二叉链表
二叉链表-C语言的类型描述
typedef struct BiTNode{ TElemType data; struct BiTNode *lchild ,*rchild; //左右孩子指针}BiTNode,*BiTree;
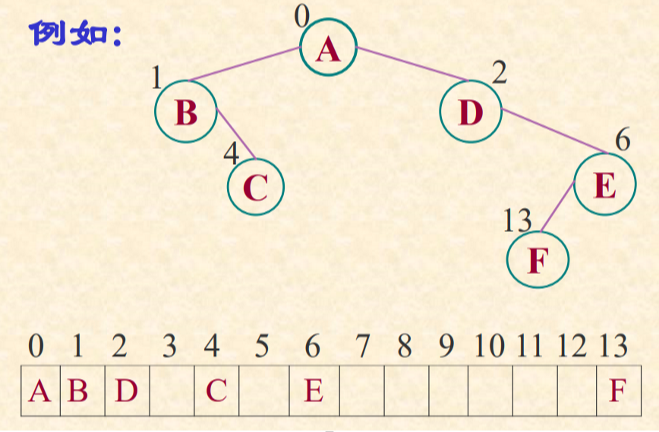
双亲链表
双亲链表-C语言的类型描述
typedef struct BPTNode{ //结点结构 TElemType data; int *parent; //指向双亲的指针 char LRTag; //左、右孩子标志域}BPTNodetypedef struct BPTree{ //树结构 BPTNode nodes[MAX_TREE_SIZE]; int num_node; //结点数目 int root; //根结点的位置}BPTree
三叉链表
三叉链表-C语言的类型描述
typedef struct TriTNode{ TElemType data; struct BiTNode *lchild ,*rchild; //左右孩子指针 struct TriTNode *parent; //双亲指针}BiTNode,*BiTree;
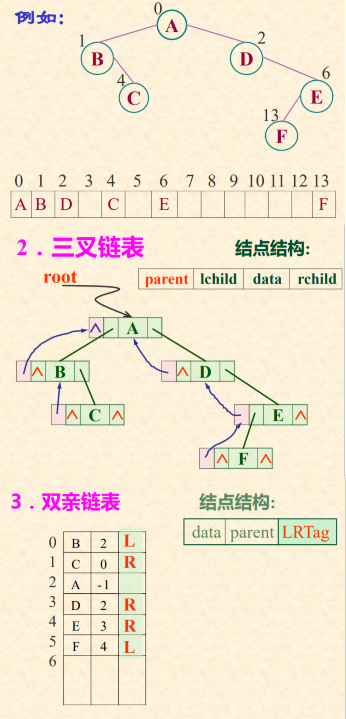
三种链表的图示
1.二叉链表
线索链表
6.4 二叉树的遍历
6.4.1 问题的提出
顺着某一条搜索路径巡防二叉树中的结点,使得每个结点均被访问一次,而且仅被访问一次。
// “访问”的含义可以很广,如:输出结点的信息等。
对“二叉树”而言,可以有三条搜索路径:
01 先上后下的按层次遍历。
02 先左后右的遍历。
03 先有后左的遍历。
6.4.2 先左后右的遍历算法
一、先序的遍历算法
若二叉树为空树,则空操作;
否则:
(1)访问根结点。
(2)先序遍历左子树。
(3)先序遍历右子树。
二、中序的遍历算法
若二叉树为空树,则空操作;
否则:
(1)中序遍历左子树。
(2)访问根结点。
(3)中序遍历右子树。
三、后序的遍历算法
若二叉树为空树,则空操作;
否则:
(1)后序遍历左子树。
(2)后序遍历右子树。
(3)访问根结点。
6.4.3 算法的递归描述
void Preorder(BiTree T,void(*visit)(TElemType& e)){ // 先序遍历二叉树 if(T){ visit(T->data); // 访问结点 Preorder(T->lchild,visit); // 遍历左子树 Preorder(T->rchild,visit); // 遍历右子树 }}
6.4.4 中序遍历算法的非递归描述
BiTNode *GoFarLeft(BiTree T, Stack *S){ if (!T ) return NULL; while (T->lchild ){ Push(S, T); T = T->lchild; } return T;}------------------------------------------void Inorder_I(BiTree T, void (*visit) (TelemType& e)){ Stack *S; t = GoFarLeft(T, S); // 找到最左下的结点 while(t){ visit(t->data); if (t->rchild) t = GoFarLeft(t->rchild, S); else if( !StackEmpty(S) ) // 栈不空时退栈 t = Pop(S); else t = NULL; // 栈空表明遍历结束 }//while}//Inorder_I
先序遍历算法的递归描述
void Preorder(BiTree T,void(*visit)(TElemType&e)){ //先序遍历二叉树 if(T){ visit(T->data); //访问结点 Predorder(T->lchild,visit); //遍历左子树 Predorder(T->rchild,visit); //遍历右子树 }}
6.4.5 遍历算法的应用举例
一、统计二叉树中叶子结点的个数(先序遍历)
算法基本思想
先序(或中序或后序)遍历二叉树,在遍历过程中查找叶子结点,并计数。由此,需在遍历算法中增添一个“计数” 的参数,并将算法中“访问结点”的操作改为:若是叶子,则计数器增1。
算法实现
void CountLeaf (BiTree T, int& count){ if (T) { if ( (!T->lchild) && (!T->rchild) ) count++; // 对叶子结点计数 CountLeaf( T->lchild, count); CountLeaf( T->rchild, count); } // if} // CountLeaf
二、求二叉树的深度(后序遍历)
算法基本思想
首先分析二叉树的深度和它的左、右子树深度之间的关系。从二叉树深度的定义可知,二叉树的深度应为其左、右子树深度的最大值加1。由此,需先分别求得左、右子树的深度,算法中“访问结点”的操作为:求得左、右子树深度的最大值,然后加 1 。
算法实现
int Depth (BiTree T ){ // 返回二叉树的深度 if (!T) depthval = 0; else{ depthLeft = Depth( T->lchild ); depthRight= Depth( T->rchild ); depthval = 1 + (depthLeft > depthRight ? depthLeft : depthRight); } return depthval;}
三、复制二叉树(后序遍历)
算法基本思想
其基本操作为:生成一个结点。生成一个二叉树的结点(其数据域为item,左指针域为lptr,右指针域为rptr)
算法实现
BiTNode *GetTreeNode(TElemType item, BiTNode *lptr , BiTNode *rptr){ if(!(T = (BiTNode*)malloc(sizeof(BiTNode)))) exit(1); T-> data = item; T-> lchild = lptr; T-> rchild = rptr; return T;}BiTNode *CopyTree(BiTNode *T) { if (!T ) return NULL; if(T->lchild ) newlptr = CopyTree(T->lchild);//复制左子树 else newlptr = NULL; if (T->rchild ) newrptr = CopyTree(T->rchild);//复制右子树 else newrptr = NULL; newT = GetTreeNode(T->data, newlptr, newrptr); return newT;} // CopyTree
四、建立二叉树的存储结构
不同的定义方法相应有不同的存储结构的建立算法
4-1:以字符串的形式 根-左子树-右子树 定义一棵二叉树
例如:空树——以空白字符“■”表示只含一个根结点的二叉树——以空白串“A ■ ■”表示▲ Ⓐ Ⓑ Ⓓ◯ Ⓒ ◯ ◯ —— A(B(■,C(■,■)),D(■,■))--------------------------------------------------Status CreateBiTree(BiTree &T){ scanf(&ch); if(ch==' ') T = NULL; else{ if(!(T = (BiTNode*)malloc(sizeof(BiTNode)))) exit(OVERFLOW); T->data = ch; // 生成根结点 CreateBiTree(T->lchild); // 构造左子树 CreateBiTree(T->rchild); // 构造右子树 } return OK;} // CreateBiTree
4-2:按给定的表达式建相应二叉树
01 由先缀表示式建树 例如:已知表达式的先缀表示式——> -×+ a b c / d e02 由原表达式建树 例如:已知表达式——> (a+b)×c – d/e 对应先缀表达式——> -×+ a b c / d e的二叉树 特点:操作数为叶子结点;运算符为分支结点--------------------------------------------------由先缀表达式建树的算法的基本操作: scanf(&ch); if ( In(ch, 字母集)) 建叶子结点; else{ 建根结点; 递归建左子树; 递归建右子树; }由原表达式建树的算法的基本操作: scanf(&ch); if (In(ch,字母集)){ 建叶子结点; 暂存; } else if(In(ch, 运算符集)){ 和前一个运算符比较优先数; 若当前的优先数“高”,则暂存;否则建子树; }--------------------------------------------------void CrtExptree(BiTree &T, char exp[] ){ InitStack(S); Push(S,'#'); InitStack(PTR); p = exp; ch = *p; while(!(GetTop(S)== '#' && ch=='#')){ if (!IN(ch, OP)) CrtNode(t,ch); // 建叶子结点并入栈 else{......} if( ch != '#'){ p++; ch = *p; } } // while Pop(PTR, T);} // CrtExptree--------------------------------------------------switch (ch) { case '(' : Push(S, ch);break; case ')' : Pop(S, c); while (c != '(' ){ CrtSubtree(t, c); // 建二叉树并入栈 Pop(S,c) } break; defult : ...... } // switch --------------------------------------------------while(Gettop(S, c) && ( precede(c,ch))) { CrtSubtree(t,c); Pop(S,c);}if ( ch!= '#' ) Push(S,ch);break;--------------------------------------------------建叶子结点的算法为:void CrtNode(BiTree& T,char ch){ T=(BiTNode*)malloc(sizeof(BiTNode)); T->data = ch; T->lchild = T->rchild = NULL; Push( PTR, T );}--------------------------------------------------建子树结点的算法为:void CrtSubtree (Bitree& T, char c){ T=(BiTNode*)malloc(sizeof(BiTNode)); T->data = c; Pop(PTR, rc); T->rchild = rc; Pop(PTR, lc); T->lchild = lc; Push(PTR, T);}--------------------------------------------------
4-3:由二叉树的先序和中序序列建树
仅知二叉树的先序序列“abcdefg” 不能唯一确定一棵二叉树,如果同时已知二叉树的中序序列 “cbdaegf”,则会如何?二叉树的先序序列:根-左子树-右子树二叉树的中序序列:左子树-根-右子树--------------------------------------------------void CrtBT(BiTree& T, char pre[], char ino[], int ps, int is, int n ){ /* 已知pre[ps..ps+n-1]为二叉树的先序序列, ino[is..is+n-1]为二叉树的中序序列, 本算法由此两个序列构造二叉链表 */ if (n==0) T=NULL; else { k=Search(ino, pre[ps]); //在中序序列中查询 if (k== -1) T=NULL; else{ ...... } } //} // CrtBT --------------------------------------------------T=(BiTNode*)malloc(sizeof(BiTNode));T->data = pre[ps];if (k==is) T->Lchild = NULL;else CrtBT(T->Lchild, pre[], ino[], ps+1, is, k-is );if (k=is+n-1) T->Rchild = NULL;else CrtBT(T->Rchild, pre[], ino[], ps+1+(k-is), k+1, n-(k-is)-1 );
五、二叉树的层次遍历
Status LevelOrderTraverse(BiTree T){ Queue Q;InitQueue(Q); if (T) Enqueue(Q,T); while(!QueueEmpty(Q)){ DeQueue(Q,&E); visit(E); if (E->lchild) EnQueue(Q,E->lchild); if (E->rchild) EnQueue(Q,E->rchild); } // while} // Status
6.5 线索二叉树
6.5.1 何谓线索二叉树?
遍历二叉树的结果是,求得结点的一个线性序列
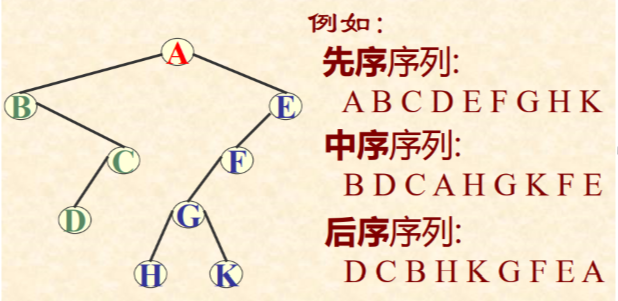
线索二叉树的概念
指向该线性序列中的“前驱”和“后继”的指针,称作“线索”。

包含“线索”的存储结构,称作“线索链表”。
与其相应的二叉树,称作“线索二叉树”。
并不是每个节点都加前驱和后继信息,线索化二叉树是在二叉树的基础上来构成的。
那么前驱后继指针加在哪里呢?
利用空链域:
前驱加在左子树为空的时候;
后继加在右子树为空的时候,
n个结点的二叉树有n+1个空链域,
用这n+1个空链域来存线索。
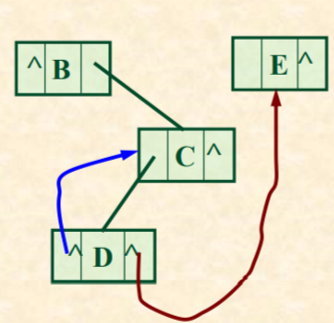
对线索链表中结点的约定
在二叉链表的结点中,指针共用,增加两个标志域
[ lchild | LTag | data | RTag | rchild ]
若该结点的左子树不空, 则lchild域的指针指向其左子树,且左标志域的值为“指针Link”; 否则,lchild域的指针指向其“前驱”且左标志的值为“线索Thread”。若该结点的右子树不空, 则rchild域的指针指向其左子树,且左标志域的值为“指针Link”; 否则,rchild域的指针指向其“前驱”且左标志的值为“线索Thread”。
如此定义的二叉树的存储结构称作“线索链表”。
线索链表的类型描述
typedef enum { Link, Thread } PointerThr; // Link==0:指针,Thread==1:线索typedef struct BiThrNod { TElemType data; struct BiThrNode *lchild, *rchild; // 左右指针 PointerThr LTag, RTag; // 左右标志} BiThrNode, *BiThrTree;
6.5.2 如何建立线索链表
在中序遍历过程中修改结点的左、右指针域,以保存当前访问结点的“前驱”和“后继”信息。遍历过程中,附设指针pre和p,p指向当前访问的结点,pre指向p的前驱。
通过pre和p方便获取当前结点的前驱和后继。然后修改左右子树有为空的域,不空的不改。
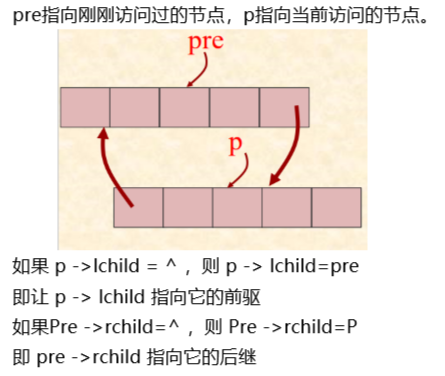
线索化算法
void InThreading(BiThrTree p) { if (p){ // 对以p为根的非空二叉树进行线索化 InThreading(p->lchild); // 左子树线索化 if (!p->lchild){ // 建前驱线索 p->LTag = Thread; p->lchild = pre; } if (!pre->rchild){ // 建后继线索 pre->RTag = Thread; pre->rchild = p; } pre = p; // 保持 pre 指向 p 的前驱 InThreading(p->rchild); // 右子树线索化 } // if} // InThreading
中序线索化算法
Status InOrderThreading(BiThrTree &Thrt, BiThrTree T) { // 构建中序线索链表 if (!(Thrt = (BiThrTree)malloc (sizeof( BiThrNode)))) exit (OVERFLOW); Thrt->LTag = Link; Thrt->RTag =Thread; Thrt->rchild = Thrt; // 添加头结点 ...... return OK;} // InOrderThreadingif (!T) Thrt->lchild = Thrt; else { Thrt->lchild = T; pre = Thrt; InThreading(T); pre->rchild = Thrt; // 处理最后一个结点 pre->RTag = Thread; Thrt->rchild = pre;}
6.5.3 线索链表的遍历算法
由于在线索链表中添加了遍历中得到的 “前驱”和“后继”的信息,省去了栈 (递归栈或非递归栈),因为前后关系已经通过存储结构解决。从而简化了遍历的算法。
for( p = firstNode(T) ; p ; p = Succ(p) ) Visit(p);
每次访问完p都指向他的后继,然后继续访问。省略了栈!
例如:对中序线索化链表的遍历算法
01 中序遍历的第一个结点?
左子树上处于“最左下”(没有左子树)的结点。
02 在中序线索化链表中结点的后继?
若无右子树,则为后继线索所指结点;
否则为对其右子树进行中序遍历时访问的第一个结点。
void InOrderTraverse_Thr(BiThrTree T, void (*Visit)(TElemType e)) { p = T->lchild; // p指向根结点 while (p != T){ // 空树或遍历结束时,p==T while (p->LTag==Link) p = p->lchild; // 第一个结点 if(!Visit(p->data)) return ERROR;//访问找到的第一个结点 while (p->RTag==Thread && p->rchild!=T){ p = p->rchild; Visit(p->data); // 访问后继结点 } // while p = p->rchild; // p进至其右子树根 } //while} // InOrderTraverse_Thr
6.6 树和森林的表示方法
6.6.0 树的三种存储结构
一、双亲表示法
二、孩子链表表示法
三、树的二叉链表(孩子-兄弟)存储表示法
6.6.1 双亲表示法
图示
C语言的类型描述
#define MAX_TREE_SIZE 100// 结点结构:[ data | parent ]typedef struct PTNode{ Elem data; int parent; //双亲位置域}PTNode;// 树结构typedef struct{ PTNode nodes[MAX_TREE_SIZE]; int r,n; //根结点的位置和结点个数}PTree;
6.6.2 孩子链表表示法
图示
C语言的类型描述
#define MAX_TREE_SIZE 100// 孩子结点结构:[ child | next ]typedef struct CTNode{ int child; struct CTNode *next;} *ChildPtr;// 双亲结点结构:[ data | firstchild ]typedef struct { Elem data; ChildPtr firstchild; //孩子链的头指针}// 树结构typedef struct{ CTBox nodes[MAX_TREE_SIZE]; int n,r; // 结点数和根结点的位置} CTree;
6.6.3 树的二叉链表(孩子-兄弟)存储表示法
图示
C语言的类型描述
#define MAX_TREE_SIZE 100// 结点结构:[ firstchild | parent | nextsibling ]typedef struct CSNode{ Elem data; struct CSNode; *firstchild,*nextsibling;}CSNode,*CSTree;
6.6.4 森林和二叉树
森林和二叉树对应关系
设森林 F = ( T1, T2, …, Tn ); T1 = (root,t11, t12, …, t1m);二叉树 B =( LBT, Node(root), RBT );
由森林转换成二叉树的转换规则为:
若 F = Φ,则 B = Φ;否则, 由 ROOT( T1 ) 对应得到 Node(root); 由 (t11, t12, …, t1m ) 对应得到 LBT; 由 (T2, T3,…, Tn ) 对应得到 RBT。
由二叉树转换为森林的转换规则为:
若 B = Φ, 则 F = Φ;否则, 由 Node(root) 对应得到 ROOT( T1 ); 由 LBT 对应得到 ( t11, t12, …,t1m); 由 RBT 对应得到 (T2, T3, …, Tn)。
由此,树的各种操作均可对应二叉树的操作来完成。
应当注意的是,和树对应的二叉树,其左、右子树的概念已改变为: 左是孩子,右是兄弟。
6.7 树和森林的遍历
6.7.1 树的遍历
6.7.2 森林的遍历
6.7.3 树的遍历的应用
6.8 哈夫曼树与哈夫曼编码
第七章 图
7.1 图的定义和术语
7.1.1 图的定义
图G由两个集合构成,记作G = < V , E >
V 是顶点的非空有限集合,
E 是边的有限集合
边是顶点的无序对或有序对集合
7.1.2 图的术语
无向图和有向图
无向完全图和有向完全图
邻接点及关联边
顶点的度、顶点的入度和出度
顶点数、边数e和度数D(v)之间的关系
无向图的路径、回路
无向图G=(V,E)中的顶点序列v1 ,v2 ,… ,vk ,若 (vi ,vi+1) ∈ E ( i=1,2,…k-1), 则称该序列是从顶点v到顶点u的路径(v =v1 , u =vk)若v=u,则称该序列为回路。
简单路径和简单回路
简单路径
在一条路径中,若除起点和终点外,所有顶点各不相同,则称该路径为02 简单路径
简单回路
由简单路径组成的回路称为简单回
路连通图和强连通图
连通图
在无向图G=< V, E >中,若对任何两个顶点 v、u 都 存在从 v 到 u 的路径,则称G是连通图。 // 针对 无向图
强连通图
在有向图G=< V, E >中,若对任何两个顶点 v、u 都存在从v 到 u 的路径,则称G是强连通图。 // 针对 有向图
子图
设有两个图G=(V,E)、G1 =(V1,E1),若V1 ⊆ V ,E1 ⊆ E ,E1关联的顶点都在V1中,则称 G1 是 G 的子图 // 子图的顶点是原图顶点的子集 子图的边都是原图边的子集 子图的边都关联到子图的顶点
连通分量和强连通分量
连通分量
无向图中的极大联通子图。
极大连通子图
1.子图 必须是子图2.联通 任意两点都是相通的3.极大 “极大”是指边数极大,是原图的边中的极大 子图里面已经包括了原图中所有和子图中顶点有关的边 “极大”而不是“最大”,因为不一定只有一个连通分量 类似于 数学中极大值和最大值的区别
强连通分量
有向图中的极大强连通子图。
网络(边带权图)
权
某些图的边具有与它相关的数, 称之为权。
网络
这种带权图叫做网络。
生成树
生成树的定义
连通图的一个子图如果是一棵包含G的所有顶点的树,则该子图称为G的生成树
生成树的充要条件
T是G的生成树 当且仅当 T满足如下条件:(1)T是G的连通子图(2)T包含G的所有顶点(3)T中无回路
7.1.3 图的抽象数据类型
ADT Graph{数据对象V:V是具有相同特征的数据元素的集合,称为顶点集。数据关系R:R={VR} VR={<v,w>|v,w∈V 且 P(v,w)}基本操作}ADT Graph
7.2 图的存储结构
7.2.1 前言
图的存储结构至少要保存两类信息:
1.顶点的数据信息;2.顶点间的关系信息
约定
7.2.2 数组表示法
邻接矩阵
定义
G的邻接矩阵是满足如下条件的n阶矩阵
举例:无向图的邻接矩阵
(1)无向图的邻接矩阵有什么特点? 是对称矩阵 对角线元素都是零(2)无向图中第i个顶点的度在邻接矩阵中如何体现? 第i行(或第i列)的非零元素个数之和(3)图的总度数怎么求? 非零元个数之和(4)边数怎么求? 边数为总度数的一半
举例:有向图的邻接矩阵
(0)有向图中第i个顶点的出度和入度在邻接矩阵中如何体现? 边数是多少? 第i行的非零元个数之和; 第i列的非零元个数之和; 边数为非零元的个数。
网络的邻接矩阵
邻接矩阵的类型实现
图的类型实现
建立无向网络(边带权图)G的算法概要
首先读入 顶点数 G.vexnum ,边数 G.arcnum ,图的种类 G.kind 1、给顶点域赋值: G.vexs[i];2、给边域赋值: ① 边域初始化:G.arcs[i][j].adj=INFINITY; ② 读入边及权重i, j, w, G.arcs[i][j].adj=w; G.arcs[j][i].adj=w。
建立无向网络(边带权图)G的算法详解
邻接矩阵的特点
1.空间复杂度O(n^2)
2.操作特点
(1)边或弧的删除和插入操作容易。
(2)顶点的插入删除操作不容易。
7.2.3 邻接表
邻接表的举例
1.无向图的邻接表 示例
讨论: (1)如何求无向图邻接表中第i个顶点的度? 第i个顶点的边链表结点个数之和。 (2)图的总度数? 所有边链表结点个数之和。 (3)边数? 所有边链表结点个数之和的一半。
2.有向图的邻接表 示例
讨论: (1)求有向图邻接表中第i个顶点的出度? 第i个顶点的边链表结点个数之和。 (2)入度? 遍历所有边链表 (3)图的边数? 所有边链表结点个数之和。
3.有向图的逆邻接表 示例
讨论: (1)求有向图邻接表中第i个顶点的出度? 遍历所有边链表。 (2)入度? 第i个顶点的边链表结点个数之和。 (3)图的边数? 所有边链表结点个数之和。
邻接表的定义
0.邻接表的定义分两部分:边链表、顶点表
1.边链表
与顶点V关联的所有边组成一个链表,称为顶点V的边链表。在边链表中,其结点结构如下:
2.顶点表
用顺序存储方式存储图的顶点表 v1 ,v2 ,v3 ,…vn,每个顶点的结构。
3.邻接表
由 顺序存储的顶点表 和 链接存储的边链表 构成的 图的存储结构 被称为邻接表。
邻接表的存储实现
#define MAX_VERTEX_NUM 20//1.边表的存储类型typedef struct ArcNode { int adjvex; // 该弧所指向的顶点的位置 struct ArcNode *nextarc; // 指向下一条弧的指针 InfoType *info; // 该弧相关信息的指针} ArcNode;//2.顶点表的存储类型typedef struct vnode { vertextype data; // 顶点信息 Arcnode *firstarc; // 指向第一条依附该顶点的弧}vnode, adjlist[MAX_VERTEX_NUM]; //3.图的邻接表存储类型typedef struct { adjlist vertices; int vexnum, arcnum; int kind; // 图的种类标志} ALGraph;ALGraph G;
建立无向图G的邻接表的算法概要
1.给顶点表中顶点域赋值,指针域赋值 G.vertices[i].dat a= getchar(); G.vertices[i].firstarc = NULL; 2.读入边的邻接顶点编号i,j: (1)生成结点s; 前插法建表; s->nextarc = G.vertices[i].firstarc; G.vertices[i].firstarc = s; (2)生成结点s; 前插法建表;…………. 3、重复第二步。
建立无向图G的邻接表的算法详解
邻接表的特点
1.对于顶点多边少的图采用邻接表存储节省空间;
空间复杂度O(n+e)。
2.容易找到任一顶点的第一个邻接点。
7.2.4 十字链表
7.2.5 邻接多重表
7.2.6 图的存储结构总结
在不同的存储结构下,实现各种操作的效率可能是不同的。
所以在求解实际问题时,要根据求解问题所需操作,选择合适的存储结构。
当一个图的边数比较少时,选择哪种存储结构?
7.3 图的遍历
7.3.1 图的遍历
从图的某一顶点出发访问图中的所有顶点,且每个顶点仅访问一次。
7.3.2 深度优先搜索
7.3.3 广度优先搜索
7.4 图的连通性问题
7.4.1 无向图的连通分量和生成树
连通分量求解过程
深度优先搜索和广度优先搜索在基于一点的搜索过程中,
能访问到该顶点所在的最大连通子图的所有顶点,即一个连通分量。
通过变换搜索顶点,可求得无向图的所有连通分量。
深度优先搜索实现找图的连通分量
7.4.2 最小生成树
最小生成树的定义
对于边带权图(网)来说,
在所有的 生成树中,各边的权值(边长)总和最小 的生成树称作最小生成树。
最小生成树的性质(MST性质)
假设 G = ( V , E ) 是一个连通网,U是顶点集V的一个非空子集。
若(u,v)是一条具有最小权值 (代价) 的边,其中u∈U,v∈V-U,
则必存在一棵包含边 ( u , v ) 的最小生成树。
7.4.3 最小生成树算法:普里姆(Prim)算法
普里姆算法思想
设G=(V,E)是连通网,用T来记录G上最小生成树边的集合。
(1)算法开始时,U={ 1 | 1 ∈ V } (选一个初始顶点), T={ };
(2)找到满足 min { weight ( u,v ) | u∈U,v∈V-U } 的边( ui , vi ),
把它并入集合T中,同时vi并入U;
(3)反复执行(2),直到U=V时终止算法。
普里姆算法示例演示
普里姆算法详解
普里姆算法分析
(1)时间复杂性 主要体现在 两层循环 上,复杂性是 O(n^2)
(2)空间复杂性 主要体现在 两个辅助数组 ,复杂性是 O(n)
7.4.4 最小生成树算法:克鲁斯卡尔(Kruskal)算法
克鲁斯卡算法 示例演示
克鲁斯卡尔算法思想
设G=(V,E)是连通网,用T来记录G上最小生成 树边的集合。 (1)从G中取最短边e,如果边e所关联的两个顶 点不在T的同一个连通分量中,则将该边加入T;(2)从G中删除边e; (3)重复(1)和(2)两个步骤,直到T中有 n-1 条边。
卡鲁斯卡尔算法概要
输入:连通图G=(V,E),其中V={1,2,…,n}, 输出:一颗最小生成树: void Kruskal(V,T) { T=V; ncomp=n; //连通分量 while( ncomp > 1) { 从E中取出删除权最小的边(v,u); if(v和u属于T中不同的连通分量) {T=T∪{(v,u)}; ncomp--;} } }
7.4.5 最小生成树算法:普里姆算法和克鲁斯卡尔算法比较
克鲁斯卡尔算法一般先按边权重对边进行排序,对于e条边来说,排序的最好时间复杂度是O(eloge)
7.5 有向无环图的应用(拓扑排序+关键路径)
7.6 最短路径
7.6.1 问题的提出
路径长度
路径上边的权值之和
最短路径
两结点间权值之和最小的路径
交通咨询系统、通讯网、计算机网络常要寻找两结点间最短路径;
计算机网发送Email节省费用, A到B沿最短路径传送。
最短路径并非传统意义上的路径最短。例如:如果权重是道路上的拥挤程度,最短路径 就是最畅通的路径。
7.6.2 单源最短路径
什么是单源最短路径
给定有向图G和源点vi,求 vi到G中其余各顶点的最短路径。
Dijkstra算法思想
Dijkstra提出按路径长度的递增次序,逐步产生最短路径。
首先求出离源点路径长度最短的点,再参照它求出离源点次短的点,依次类推。
讨论
求单源最短路径的Dijkstra算法边权值能否为负值?
答案
不能
是边权值为负值没意义吗?->不是,是Dijkstra算法本身不允许
Dijkstra算法要点
(1)设源点为v0,顶点集合分成两部分:
S:已经求出最短路径的顶点集合
V-S:未求出最短路径的顶点集合
初值:S={v0},V-S={v1,v2,v3,v4}
第二个加入S中的点必然是与v0邻接而且与v0之间的边长最短的顶点。
如图是v2,v2加入S
(2)S={v0, v2},V-S={v1, v3,v4}
设第三个加入S中的点是w ∈ V-S,
则w到v0的最短路径的特点是:
w是V-S中满足:v0->w和v0->v2->w中最短的. w是v1
(3)S={v0, v2, v1},V-S={v3,v4}
设第四个加入S中的点是w ∈ V-S,
则w到v0的最短路径必然是:
v0->w
v0->v2->w
v0->v2->v1->w中最短的,………
Dijkstra算法示例演示
Dijkstra算法存储结构
原来的邻接矩阵存储结构:
typedef struct ArcCell { // 弧的定义 VRType adj; InfoType *info; // 该弧相关信息的指针 } ArcCell, AdjMatrix[MAX_VERTEX_NUM] [MAX_VERTEX_NUM];typedef struct { // 图的定义 VErtexType vexs[MAX_VERTEX_NUM]; AdjMatrix arcs; // 弧的信息 int vexnum, arcnum; // 顶点数,弧数 GraphKind kind; // 图的种类标志} MGraph; MGraph G;
实际存储结构:
typedef struct { // 图的定义 VErtexType vexs[MAX_VERTEX_NUM]; float arcs[MAX_VERTEX_NUM][MAX_VERTEX_NUM]; // 弧的信息 int vexnum, arcnum; // 顶点数,弧数} MGraph; MGraph G;
Dijkstra算法概要
(1)引入一个辅助数组D[ ], D[i]表示当前所找到的 源点到每个终点i的最短路径长度。 最短路径的初值即为有向边的权值: D[i]=G.arcs[v0][i] 引入辅助数组final[ ],final[i]=1表示顶点i的最短路径已求出, final[i]=0表示顶点i的最短路径还没有求出。 初始状态:final[v0](源点)标志为1,其它为0。 引入数组P[ ]来记录路径。(2) 选择D[ ]中路径最小值的顶点v(已求出最短路的顶点除外) , v就是当前求得的一条从v出发的最短路径的终点。 修改 final[v]=1。(3) 修改未求出最短路径的顶点的最短路径长度,如果: D[v]+G.arcs[v][w]<D[w] 则修改D[w]为: D[w]=D[v]+G.arcs[v][w] 同时修改P[w]=v; (4) 重复操作(2)、(3)n-1次。 求得从v0到图上其余各顶点的最短路径长度递增序列。
Dijkstra算法详解
Dijkstra算法分析
(1)时间复杂性主要体现在求 每个顶点的最短路径时 ,需要修改距离值和求最小值,时间复杂性O(n2 ) (2)空间复杂性主要体现在 两个辅助数组 ,空间复杂性是O(n)。
Dijkstra算法功能
(1)求一个顶点到其余各顶点的最短路 求各顶点之间的最短路。(2)判断任意两顶点 i, j 之间是否有路。(3)判断有没有包括任意两顶点 i, j 的环路。
7.6.3 每一对顶点之间的最短路径
依次把有向网络的每个顶点作为源点,重复执行Dijkstra算法n次,即可求得每对顶点之间的最短路径。 是否能直接求出所有顶点之间的最短路径?
——弗洛伊德(Floyd)算法
Floyd算法的思想
对顶点进行编号,设顶点为0, 1, ... , n-1,算法仍采用 邻接矩阵G.arcs[n][n] 表示有向网络.D(-1) [n][n] 表示中间不经过任何点的最短路径;它就是 邻接距阵G.arcs[n][n] ;D(0) [n][n] 中间只允许经过“0”号顶点的最短路径;D(1) [n][n]中间只允许经过“0”号和“1”号的最短路径;D(n-1) [n][n] 中间可经过所有顶点的最短路径。
Floyd算法实例分析
Floyd算法要点
迭代设 D(k)[n][n] ,中间只允许经过 0,...k-1,k 的最短路径已经求出; 求D(k+1) [n][n],中间只允许经过 0,...k-1,k,k+1 的最短路径;D(k+1) [i][j]是i与j间只可能经过 1,2,…,k+1 的最短路径。如果i与j经过k+1,则可以写成如下形式: i……k+1……j D(k)[i][k+1]+ D(k)[k+1][j] 比较D(k)[i][k+1]+ D(k)[k+1][j]与D(k)[i][j]的大小,把小值写进 D(k+1) [i][j]。
Floyd算法详解
Floyd算法分析
(1)时间复杂性主要体现在三重循环, 时间复杂性为O(n^3 ) (2)空间复杂性主要体现在利用了一个二维数组,空间复杂性为O(n2 )讨论 权值是否可以是负值?答案 权值可以是负值,但不能有长度 是负值的环路。
Floyd算法功能
(1)求出了任意两点i,j之间的最短路径。 (2)可以判断任意两点之间是否有路。 可以判断是不是强连通图。(3)可以判断有向图经过任意两点是否有环路。
7.8 第七章总结
图的基本操作
CreatGraph(&G) //建立图DestroyGraph(&G) //销毁图InsertVex(&G, v) //插入顶点DeleteVex(&G, v) //删除顶点InsertArc(&G, v, w) //插入弧DeleteArc(&G, v, w) //删除弧DFSTraverse(G, v, Visit()) //深度优先搜索BFSTraverse(G, v, Visit()) //广度优先搜索FirstAdjVex(G, v) //返回v的“第一个邻接点”NextAdjVex(G, v, w) //返回v的(相对于w的)下一个邻接点LocateVex(G, u) //返回u在G中的位置GetVex(G, v) //返回v的值。PutVex(&G, v, value) //对v赋值valueInsertArc(&G, v, w) //增加边<v,w>,无向图还要增加<w,v>DeleteArc(&G, v, w) //删除边<v,w>,无向图还要删除<w,v>
邻接矩阵的类型实现
#define INFINITY INT_MAX //最大值。表示无穷大#define MAX_VERTEX_NUM 100 //最大顶点个数typedef enum {DG,DN,UDG,UDN} GraphKind;typedef struct ArcCell{ //弧的定义 VRType adj; //VRType是顶点关系类型 // 对无权图,用1或0表示是否相邻 // 对带权图,则为权值类型 InfoType *info; // 该弧相关信息的指针}ArcCell,AdjMatrix[MAX_VERTEX_NUM][MAX_VERTEX_NUM]
图的类型实现
typedef struct { //图的类型定义 VertexType vexs[MAX_VERTEX_NUM]; //顶点信息 AdjMatrix arcs; // 弧的信息 int vexnum, arcnum; //顶点数,弧数 GraphKind kind; //图的种类标志 }MGraph;MGraph G;
建立无向网络(边带权图)G的算法详解
void Creatgraph(MGraph &G){ int i, j, k; float w; scanf(“%d,%d,%d”,G.vexnum, G.arcnum, G.kind); for(i=1;i<=G.vexnum;i++) G.vexs[i] = getchar(); for(j=1;j<=G.vexnum;j++){ G.arcs[i][j].adj = INFINITY; G.arcs[i][j].info = NULL; } for(k=1;k<=G.arcnum;k++){ scanf(“%d,%d,%f”,&i,&j,&w); G.arcs[i][j].adj = w; G.arcs[j][i].adj = w; }}
建立无向图G的邻接表的算法详解
void Creatadilist(ALGraph &G){ int i,j,k; ArcNode *s; scanf(“%d,%d,%d”,G.vexnum,G.arcnum,G.kind); for(i=1;i<=G.vexnode;i++){ G.vertices[i].data = getchar(); G.vertices[i].firstarc = NULL; } for(k=0;k<G.arcnum;k++){ scanf(“%d%d”,&i,&j); s = (ArcNode *)malloc(sizeof(ArcNode)); s->adjvex = j; s->info=NULL; s->nextarc = G.vertices[i].firstarc; G.vertices[i].firstarc = s; ………… }}
十字链表的存储实现
#define MAX_VERTEX_NUM 20 //1.边表的存储类型: typedef struct ArcBox { int tailvex, headvex; // 该弧的尾和头位置 struct ArcBox *hlink, *tlink; // 分别为弧头相同和弧尾相同的弧的链域 InfoType *info; // 该弧相关信息的指针 } ArcBox;//2.顶点表的存储类型:typedef struct Vexnode { VertexType data; // 顶点信息 ArcBox *firstin, *firstout; // 分别指向下一个入边和出边} Vexnode;//3.图的十字链表存储类型typedef struct { VexNode xlist[MAX_VERTEX_NUM]; int vexnum, arcnum; // 节点个数,边个数 } OLGraph; OLGraph G;
深度优先搜索算法详解
void DFS(Graph G, int v) {// 从顶点v出发,深度优先搜索遍历连通图 G visited[v] = TRUE; VisitFunc(v); //访问v for( w=FirstAdjVex(G, v) ; w!=0 ; w = NextAdjvex(G,v,w) ) if (!visited[w]) // 对v的尚未访问的邻接顶点w DFS(G, w); // 递归调用DFS} // DFS/*----------------------------------------------*/void DFS(Graph G, int v) { // 从顶点v出发,深度优先搜索遍历连通图 Gvisited[v] = TRUE;printf(“%c”, G.vexs[v]); //访问vfor(w=0;w<G.vexnum;w++)if (G.arcs[v][w].adj!=0&&!visited[w])// 对v的尚未访问的邻接顶点wDFS(G, w); // 递归调用DFS} // DFS/*----------------------------------------------*/void DFSTraverse(Graph G, Status (*Visit)(int v) ) { // 对图 G 作深度优先遍历。 VisitFunc = Visit; int visited[VExnum] ; for (v=0; v<G.VExnum; ++v) visited[v] = FALSE; // 访问标志数组初始化 for (v=0; v<G.VExnum; ++v) if (!visited[v]) { DFS(G, v); } // 对尚未访问的顶点调用DFS}
广度优先搜索算法详解
void BFSTraVErse(Graph G, Status (*Visit)(int v) ){ for (v=0 ; v<G.VExnum ; ++v){ visited[v] = FALSE; //初始化访问标志 } InitQueue(Q); // 置空的辅助队列Q for ( v=0; v<G.VExnum; ++v ) if ( !visited[v]) { // v 尚未访问 ………………… }} // BFSTraVErse//省略部分代码………………… visited[v] = TRUE; Visit(v); //访问uEnQueue(Q, v); //v入队列while (!QueueEmpty(Q)) { DeQueue(Q, u); //队头元素出队并置为u for( w=FirstAdjvex(G, u) ; w!=0 ; w=NextAdjvex(G,u,w) ) if ( ! visited[w] ) { visited[w]=TRUE; Visit(w); EnQueue(Q, w); // 访问的顶点w入队列 }}/*----------------------------------------------*/void BFSTraVErse(Graph G, Status (*Visit)(int v) ){ for (v = 0; v < G.VExnum ; ++v) visited[i] = FALSE; //初始化访问标志 InitQueue(Q); //置空的辅助队列Q for ( v=0; v<G.VExnum; ++v ) if ( !visited[v]) { //v 尚未访问 ………………… }} // BFSTraVErse//省略部分代码………………… visited[v] = TRUE; Visit(v); //访问uEnQueue(Q, v); //v入队列while (!QueueEmpty(Q)) { DeQueue(Q, u); //队头元素出队并置为u for(p = G.vertices[v].firstarc ; p != NULL ; p = p->nextarc) if ( ! visited[p->adjvex]) { visited[w] = TRUE; Visit(w); EnQueue(Q, w); //访问的顶点w入队列 }}
深度优先搜索实现找图的连通分量
void DFSTraVErse(Graph G, Status (*Visit)(int v)){ int i = 1; //对图 G 作深度优先遍历。 VisitFunc = Visit; for (v=0; v<G.VExnum; ++v) visited[v] = FALSE; //访问标志数组初始化 for (v=0; v<G.VExnum; ++v) if (!visited[v]){ printf(“第%d个连通分量”,i++); DFS(G, v); }}
普里姆(Prim)算法详解
void MiniSpanTree_P(MGraph G, vertexType u) { k = Locatevex (G, u ); //k是节点u的编号 for ( j=0; j<G.VExnum; ++j ) // 辅助数组初始化 if(j!=k) { closedge[j] = { u, G.arcs[k][j].adj }; } closedge[k].lowcost = 0; // 初始,U={u} for (i=1; i<G.VExnum; ++i) { //继续向生成树上添加顶点 k = minimum(closedge); //求出加入生成树的下一个顶点(k) printf(closedge[k].adjvex, G.vexs[k]); //输出生成树上一条边 closedge[k].lowcost = 0; //第k顶点并入U集 for (j=0; j<G.vexnum; ++j){ //修改其它顶点的最小边 if (G.arcs[k][j].adj < closedge[j].lowcost) closedge[j] = { G.vexs[k], G.arcs[k][j].adj }; } //for2 } //for1} MiniSpanTree
求各顶点入度的算法详解
void FindInDegree(ALGraph G, int indegree[]){ int i; ArcNode *p; for (i=0;i<G.VExnum;i++){ p = G.VErtices[i].firstarc; while(p){ indegree[p->adjvex]++; p = p->next; } }}
拓扑排序算法详解
Status TopologicalSort(ALGraph G) { SqStack S; int count,k,i; ArcNode *p; int indegree[MAX_VERTEX_NUM]; FindInDegree(G, indegree); //对各顶点求入度 InitStack(S); for (i=0; i<G.VExnum; ++i){ //建零入度顶点栈S if (!indegree[i]) { Push(S, i); } //入度为0者进栈 } count = 0; //对输出顶点计数 while (!StackEmpty(S)){ Pop(S, i); printf(i, G.VErtices[i].data); ++count; for (p=G.VErtices[i].firstarc; p; p=p->nextarc){ k = p->adjvex; if (!(--indegree[k])) Push(S, k); } //for } //while if (count<G.vexnum) return ERROR; else return OK;} //TopologicalSort
关键路径算法详解
status TopologicalOrder(ALGraph G, Stack &T){/*有向网G采用邻接表存储结构,求各顶点事件的最早发生时间ve(全局变量)。T为拓扑序列顶点栈,S为零入度顶点栈。若G无回路,则用栈T返回G的一个拓扑序列,且函数值为OK,否则为ERROR.*/ Stack S; int count=0,k; int indegree[vexnum],ve[G.vexnum]={0}; ArcNode *p; InitStack(S); FindInDegree(G, indegree); for (int j=0; j<G.vexnum; ++j){ //建零入度顶点栈S if (indegree[j]==0) { Push(S, j); } //入度为0者进栈 } InitStack(T); //建拓扑序列顶点栈T count = 0; while (!StackEmpty(S)) { Pop(S, j); Push(T, j); ++count; for (p=G.vertices[j].firstarc; p ; p = p->nextarc){ k = p->adjvex; //对j号顶点的每个邻接点的入度减1 if(--indegree[k] == 0) { Push(S, k); } //若入度减为0,则入栈 if (ve[j]+*(p->info) > ve[k]){ ve[k] = ve[j]+*(p->info); } } //for } //while if (count<G.vexnum) return ERROR; else return OK;} //TopologicalOrder/*-------------------------------------------*/Status CriticalPath(ALGraph G) { //G为有向网,输出G的各项关键活动。 Stack T; int a,j,k,el,ee,dut; char tag; ArcNode *p; if (!TopologicalOrder(G, T)) return ERROR; for(a=0; a<G.vexnum; a++) vl[a] = ve[G.vexnum-1]; //初始化顶点事件的最迟发生时间 while (!StackEmpty(T)) //按拓扑逆序求各顶点的vl值 for(Pop(T, j), p = G.vertices[j].firstarc; p ; p = p->nextarc){ k=p->adjvex; dut=*(p->info); //dut<j,k> if (vl[k]-dut < vl[j]) { vl[j] = vl[k]-dut; } } for(j=0; j<G.vexnum; ++j) //求ee,el和关键活动 for (p = G.vertices[j].firstarc; p ; p = p->nextarc){ k=p->adjvex; dut=*(p->info); ee = ve[j]; el = vl[k]-dut; tag = (ee==el) ? '*' : ' '; printf(j, k, dut, ee, el, tag); //输出关键活动 } return OK;} //CriticalPath
单源最短路径算法详解
void ShortestPath_DIJ(MGraph G, int v0,int &P, float &D){ int i=0, j, v, w, min, final[MAX_VERTEX_NUM]; for (v=0; v<G.vexnum; ++v){ final[v] = FALSE; D[v] = G.arcs[v0][v]; P[v] = -1; // 设空路径 if (D[v] < INFINITY) P[v] = v0; } final[v0] = TRUE; P[v0]=-1 for (i=1 ; i<G.vexnum ; ++i) { min = INFINITY; //当前所知离v0顶点的最近距离 for(w=0; w<G.vexnum; ++w) if (!final[w]) //w顶点在V-S中 if (D[w]<min) { v = w; min = D[w]; } final[v] = TRUE; //离v0顶点最近的v加入S集 for (w=0; w<G.vexnum; ++w){ if (!final[w] && (min+G.arcs[v][w]<D[w])){ D[w] = min + G.arcs[v][w].adj; P[w] = v; } //if } //for2 } //for1} //ShortestPath_DIJ//输出v0到各顶点的最小距离值和路径for (i=0;i<=G.vexnum;i++){ printf(“%f\n%d”,D[i],i); pre=p[i]; while(pre!=-1){ printf(“<-%d”,pre); pre=p[pre]; }}
弗洛伊德算法详解
void ShortestPath_FLOYD(MGraph G,PathMatrix P[], DistancMatrix &D){ int v,w,u,i; for(v=0 ; v<G.vexnum ; ++v) for(w=0 ; w<G.vexnum ; ++w) { D[v][w] = G.arcs[v][w]; for (u=0; u<G.vexnum; ++u) { P[v][w][u] = FALSE; } if (D[v][w] < INFINITY){ P[v][w][v] = TURE; P[v][w][w] = TRUE; } //if } //for //初始化算法 for (u=0; u<G.vexnum; ++u) //经过的顶点 for (v=0; v<G.vexnum; ++v) for (w=0; w<G.vexnum; ++w) if (D[v][u]+D[u][w] < D[v][w]) { //从v经u到w的一条路径更短 D[v][w] = D[v][u]+D[u][w]; for (i=0 ; i<G.vexnum ; ++i) P[v][w][i] =(P[v][u][i] || P[u][w][i]); } ///if} //ShortestPath_FLOYD
第八章 查找
8.0 查找预备知识
8.0.1 有关概念
查找表
是由同一类型的数据元素(或记录)构成的集合。
静态查找表
仅作查询和检索操作的查找表。
动态查找表
在查找时包含插入、删除或修改。
主关键字
可以唯一的识别一个记录的数据项(字段)。
次关键字
关联若干项记录的数据项(字段)
查找
查找表中存在满足条件的记录
查找成功
查找表中存在满足条件的记录。
查找不成功
查找表中不存在满足条件的记录。
8.0.2 类型定义
typedef float Keytype; //Keytype定义为浮点数据类型 或者 typedef int Keytype; //Keytype定义为整型数据类型或者 typedef char *Keytype; //Keytype定义为字符指针数据类型数据元素类型定义为:typedef struct{ Keytype key; //关键字 … }ElemType; // ElemType结构体数据类型
8.0.3 宏定义
//数值型关键字的比较 #define EQ(a,b) ((a)==(b)) #define LT(a,b) ((a)<(b))#define LQ(a,b) ((a)<=(b))//字符型关键字的比较#define EQ(a,b) (!strcmp((a),(b)))#define LT(a,b) (strcmp((a),(b))#define LQ(a,b) (strcmp((a),(b)<=0)
8.1 静态查找表
8.1.1 顺序表的查找
8.1.2 有序表的查找
8.1.3 索引顺序表的查找
8.2 动态查找表
8.3 哈希表
顺序查找表存储结构
typedef struct{ ElemType *elem; //数据元素存储空间基址,建表时按实际长度分配,0昊号单元留空 int length; }SSTable; SSTable ST; ST.elem[i].key
顺序查找表的算法与实现
int Search_Seq(SSTable ST,KeyType Key){ /*在顺序表ST中顺序查找其关键字等于key的数据元素。 若找到,则函数值为该元素在表中的位置,否则为0.*/ ST.elem[0].key = key; //“哨兵” for(i = ST.length;ST.elem[i].key != key;--i) //从后往前找 return i; //找不到时,i为0 } //Search_Seq
折半查找表算法与实现
int Search_Bin(SSTable ST,KeyType Key){ low = 1; high = ST.length; //置区间初值 while(low<=high){ mid = (low + high) / 2; if (EQ(Key,ST.elem[mid].key)) return mid; //找到待查元素 else if (LT(key,ST.elem[mid].key)) high = mid - 1; // 继续在前半区间进行查找 else low = mid + 1; //继续在后半区间进行查找 } return 0; //顺序表中不存在待查元素} //Search_Bin
索引表的存储结构
typedef struct{ Keytype key; //本块最大值 int addr; //本块开始地址}indextype;typedef struct{ indextype index[maxblock]; int block;}INtable;INtable IX;
索引顺序表的算法与实现
int SEARCH(SSTable ST, INtable IX, KeyType key){ int i=0,s,e; //s记录在查找表中的开始位置 //e记录在查找表中的结束位置 {在索引表中查找,确定s和e的值} {根据s和e的值在线性表中查找} return -1}while ((key > IX.index[i].key)&&(i < IX.block)) i++;if (i < IX.block){ s = IX.index[i].addr;if (i == IX.block-1) e = ST.length;else e = IX.index[i+1].addr-1;while ( key!=ST.elem[s].key&&(s<=e) ) s=s+1;if (s<=e) return s;}
二叉排序树的存储结构
typedef struct BiTNode{ //结点结构 TElemType data; struct BiTNode *Ichild,*rchild; //左右孩子指针}BiTNode,*BiTree;
二叉排序树的查找算法
BiTree SearchBST(BiTree T,Keytype k){ BiTree p = T; while(p!=NULL){ if (p->data.key==k) return p; if (k < p->data.key) p=p->lchild; else p=p->rchild; } return NULL;}
二叉排序树的插入算法
Status InsertBST(BiTree&T,ElemType e){ BiTree p,s; if(!SearchBST(T,e.key,NULL,p)){ //查找不成功 s = (BiTree)malloc(sizeof(BiTNode)); s->data = e; s->lchild = s->rchild = NULL; if (!p) T = s; //插入s为新的根结点 else if (LT(e.key, p->data.key)) p->lchild=s; else p->rchild = s; //插入s为左孩子,插入s为右孩子 return TRUE; }else return FALSE; //树中已有关键字相同的结点,不再插入} //Insert BST/*------------------------------------------------*///p指向查找路径上的最后一个结点,即插入的位置if(!T){ p = f; return FALSE; }/*对于空树查找的处理,这个地方我们递归下去到某个左子树或右子树为空的时候,我们返回的p = f,f就是p的双亲,代表p的双亲,代表p刚才是从哪个双亲结点下来的。*/
二叉排序树删除结点算法
Status DeleteBST(BiTree &T, KeyType key){ if (!T) return FALSE; else{ if(EQ(key, T->data.key)){ return Delete(T); } else if (LT(key, T->data.key)){ return DeleteBST(T->lchild, key); } else{ return DeleteBST(T->rchild, key); } }} //DeleteBSTStatus Delete(BiTree &p){ /* BiTree &p是对父结点->left or ->right空间的引用, 即该空间是存放的是子结点的地址,这里为要删除结点p的地址。 P是被删除节点,p的值用它双亲节点的左子针或右指针来指向。 因此p的变化,代表着父结点的左右指针的指向改变了。 */ BiTree q, s; if (!p->rchild){ //右子树为空,(左子树:1空,2不空) q = p; p = p->lchild; free(q); } else if (!p->lchild){ //右子树不空,左子树为空 q = p; p = p->rchild; free(q); } else{ //左右子树都不为空的情况 q = p; s = p->lchild; //q是s的双亲,s是p的前驱 while (s->rchild){ q = s; s = s->rchild; } //循环为 找p的左子树的最大,即找p的前驱 p->data = s->data; //把结点s的数据赋给p的数据 if(q != p){ q->rchild = s->lchild; //执行了while } else{ q->lchild = s->lchild; } //while没执行,即p的左子树 s无右子树 free(s);}return TRUE;} // Delete
哈希表存储结构
int hashsize[] = {997,...};typedef struct{ ElemType *elem; int count; //当前数据元素个数 int sizeindex; //hashsize[sizeindex]为当前容量}HashTable;#define SUCCESS 1#define UNSUCCESS 0#define DUPLICATE -1
哈希表的查找算法
Status Search(HashTable H,KeyType K,int &p,int &c){ p = Hash(K); // 求得哈希地址 while ( H.elem[p].key != NULLKEY && !EQ(K, H.elem[p].key)){ collision(p, ++c); //求得下一探查地址 p } if (EQ(K, H.elem[p].key)) { return SUCCESS; //查找成功,返回待查数据元素位置 p }else{ return UNSUCCESS; //查找不成功 }} //SearchHash
第九章 内部排序
9.1 内部排序概述
9.1.1 排序方法的稳定性
当排序的关键字中存在相同的情况时,排序的结果不唯一
排序方法是稳定的
在排序前后,含相等关键字的记录的相对位置保持不变,称这种排序方法是稳定的。
排序方法是不稳定的
在排序前后,含相等关键字的记录的相对位置有可能改变,则称这种排序方法是不稳定的。
9.1.2 内部、外部排序
内部排序
在排序过程中,只使用计算机的内存存放待排序记录,称这种排序为内部排序。
外部排序
排序期间文件的全部记录不能同时存放在计算机的内存中,要借助计算机的外存才能完成排序,称之为“外部排序” 。
影响外部排序速度的主要因素
内外存之间的数据交换次数是影响外部排序速度的主要因素。
9.1.3 存储结构
#define MAXSIZE 1000 // 待排顺序表最大长度 typedef int KeyType; // 关键字类型为整数类型 typedef struct { KeyType key; // 关键字项 InfoType otherinfo; // 其它数据项} RcdType; // 记录类型typedef struct { RcdType r[MAXSIZE+1]; // r[0]闲置 int length; // 顺序表长度} SqList; // 顺序表类型
9.1.4 效率分析
时间复杂度
关键字的比较次数和记录移动次数
空间复杂度
执行算法所需的附加存储空间
稳定算法和不稳定算法
9.2 插入排序
9.2.1 直接插入排序
算法思想
(1)第一个记录是有序的(2)从第二个记录开始,按关键字的大小将每个记录插入到已排好序的序列中(3)一直进行到第n个记录
算法概要
(1)将序列中的第1个记录看成是一个有序的子序列。(2)从第2个记录起按关键字大小逐个进行插入,直至整个序列变成按关键字有序序列为止。 整个排序过程需要进行比较、后移记录、插入适当位置。 从第二个记录到第 n 个记录共需 n-1 趟。
算法讨论
Q: A: Q: A:
算法分析
分情况讨论 性能分析
算法实现
void InsertionSort ( SqList &L ) { // 对顺序表 L 作直接插入排序。 int i, j; for ( i=2; i<=L.length; ++i ) if (L.r[i].key < L.r[i-1].key) { L.r[0] = L.r[i]; // 复制为监视哨 L.r[i]=L.r[i-1]; //在满足if情况下,先直接移动一次 for ( j=i-2; L.r[0].key < L.r[j].key; -- j ) L.r[j+1] = L.r[j]; // 记录后移 L.r[j+1] = L.r[0]; // 插入到正确位置 } } // InsertSort
9.2.2 折半插入排序
算法思想
(1)在直接插入排序进行第 i 个元素时,L.r[1],L.r[2]], …, L.r[i-1] 是一个按关键字有序的序列; (2)可以利用折半查找实现在“L.r[1], L.r[2], …, L.r[i-1]”中查找r[i]的插入位置;(3)称这种排序为折半插入排序。
算法概要
算法讨论
Q: A: Q: A:
算法分析
算法实现
void BiInsertionSort ( SqList &L ){ int i, j; for ( i=2; i<=L.length; ++i ) { if (L.r[i].key < L.r[i-1].key) L.r[0] = L.r[i]; // 将 L.r[i] 暂存到 L.r[0]//在 L.r[1..i-1]中折半查找插入位置; for ( j=i-1; j>=high+1; --j ) L.r[j+1] = L.r[j]; // 记录后移 L.r[high+1] = L.r[0]; // 插入 } // for } // BInsertSortlow = 1; high = i-1;while (low<=high) { m = (low+high)/2; // 折半 if (L.r[0].key < L.r[m].key) high = m-1; // 插入点在低半区 else low = m+1; // 插入点在高半区}
9.2.3 希尔排序
算法思想
(1)对待排记录序列先作“宏观”调整, 再作“微观”调整(2)所谓“宏观”调整,指的是,“跳跃式” 的插入排序
算法概要
(1)将记录序列分成若干子序列,分别对每个子序列进行插入排序。(2)其中,d 称为增量,它的值在排序过程中从大到小逐渐缩小,直至最后一趟排序减为1。
算法讨论
(1)在增量为d时,希尔排序从什么位置开始? 从d+1个记录开始(2)希尔排序完成增量为d的排序后,序列有什么特征? 子序列 L.r[i], L.r[i+d],L.r[i+2d], …, 是有序的,1 <= i <= d(3)设 希 尔 排 序 的 增 量 序 列 为 d1,d2,…,dr, 请问:dr等于多少? 等于1。(4)当希尔排序的增量为1时的排序过程是什么排序?是直接插入排序。
算法分析
(1)稳定性 希尔排序是不稳定的排序方法。(2)算法效率 时间复杂度 平均O( n^1.3 )到平均O( n^1.5 ) 空间复杂度 O(1)
算法实现
void ShellInsert ( SqList &L, int dk ) { int i, j; for ( i=dk+1; i<=L.length; ++i ) if (LT(L.r[i].key, L.r[i-dk].key)) { L.r[0] = L.r[i]; // 暂存在R[0] for (j = i-dk; j > 0 && LT(L.r[0].key, L.r[j].key); j- = dk) L.r[j+dk] = L.r[j]; // 记录后移,查找插入位置 L.r[j+dk] = L.r[0]; // 插入 } }}
9.3 快速排序
9.3.1 冒泡排序
算法思想
(1)从第一个记录开始,两两记录比较,若 L.r[i].key>L.r[i+1].key,则将两个记录交换。 (2)第1趟比较结果将序列中关键字最大的记录放置到最后一个位置,称为“沉底” , 而最小的则上浮一个位置。(3)n个记录比较n-1遍(趟)。
算法概要
算法讨论
Q: A: Q: A:
算法分析
算法实现
void BubbleSort(Elem R[], int n) { i = n; while( i>1 ){ lastExchangeIndex = 1; for( j = 1;j < i;j++ ){ if( R[j+1].key < R[j].key ){ Swap(R[j],R[j+1]); lastExchangeIndex = j; //记下进行交换的记录位置 } //if } i = lastExchangeIndex; //本趟进行过交换的最后一个记录的位置表明i之后是有序的 } //while} //BubbleSort
9.3.2 快速排序
算法思想
基本思想——分治算法目标: 找一个记录,以它的关键字作为“枢轴”, 凡其关键字小于枢轴的记录均移动至该记录之前。反之,凡关键字大于枢轴的记录均移动至该记录之后。致使一趟排序之后,记录的无序序列 R[s..t] 将分割成两部分: R[s..i-1]和R[i+1..t],且 R[j].key ≤ R[i].key ≤ R[j].key (s≤j≤i-1) 枢轴 (i+1≤j≤t)
算法概要
算法讨论
Q: A: Q: A:
算法分析
算法实现
int Partition(SqList &L, int low, int high) { KeyType pivotkey; L.r[0] = L.r[low]; pivotkey = L.r[low].key; while (low < high) { while (low<high && L.r[high].key >= pivotkey) --high; L.r[low] = L.r[high]; while (low < high && L.r[low].key <= pivotkey) ++low; L.r[high] = L.r[low]; } L.r[low] = L.r[0]; //枢轴记录到位 return low; //返回枢轴位置 } // Partitionvoid QSort(SqList &L, int low, int high){ int pivotloc; if (low < high){ pivotloc = Partition(L, low, high); // 将L.r[low..high]一分为二 QSort(L, low, pivotloc-1); // 对低子表递归排序,pivotloc是枢轴位置 QSort(L, pivotloc+1, high); // 对高子表递归排序 }} // QSort
快速排序算法分析-构造栈
QUICKSORT(s,t,A)LIST F;int s,t;{ int i; if(s<t){ i = PARTITION(s,t,A); QUICKSORT(s,i-1,A); QUICKSORT(i+1,t,A); }}
9.4 选择排序
9.4.1 简单选择排序
算法思想
1.第一次从 n 个关键字中选择一个最小值,确定第一个。2.第二次再从剩余元素中选择一个最小值,确定第二个。3.共需 n-1 次选择
算法概要
设需要排序的表是R[n+1](1)第一趟排序是在无序区R[1]到A[n]中选出关键字最小的记录, 将它与R[1]交换,确定最小值。(2)第二趟排序是在R[2]到r[n]中选关键字最小的记录, 将它与R[2]交换,确定次小值。(3)第 i 趟排序是在R[i]到R[n]中选关键字最小的记录, 将它与R[i]交换。(4)共 n-1 趟排序。
算法讨论
Q: A: Q: A:
算法分析
算法实现
void SelectSort (Elem R[], int n ) { //对记录序列R[1..n]作简单选择排序。 for (i=1; i<n; ++i) { //选择第 i 小的记录,并交换到位。 j = SelectMinKey(R,i); //在 R[i..n] 中选择关键字最小的记录。 if (i!=j) { R[i]←→R[j]; } //与第 i 个记录交换 }} //SelectSortvoid SelectSort(SqList L){ int i, j, min; //min存储L.r[i...n]中最小值的下标 for(i=1; i<L.length; i++) { min = i; //min初值为i for(j=i+1; j<=L.length; j++) if(L.r[j].key < L.r[low].key) { min = j; } if(min != i){ //如果min较比初值发生变化,则交换 L.r[0]=L.r[i]; L.r[i]=L.r[low]; L.r[low]=L.r[0]; } }}
9.4.2 堆排序
算法思想
堆排序需解决两个问题:1.由一个无序序列建成一个堆。2.在输出堆顶元素之后,调整剩余元素成为一个新的堆。
算法概要
采用大根堆1.按关键字建立R[1],R[2],…R[n]的大根堆。2.输出堆顶元素,采用堆顶元素R[1]与最后 一个元素R[n]交换,最大元素得到正确的排序位置。3.此时前 n-1 个元素不再满足堆的特性,需重建堆。4.循环执行 1、2 两步,到排序完成。
算法讨论
Q: A: Q: A:
算法分析
算法实现
void HeapSort(HeapType &H) { int i; RcdType temp; for (i=H.length/2; i>0; --i) //建堆 HeapAdjust (H, i, H.length); for (i=H.length; i>1; --i) { temp=H.r[i]; //交换r[1]和r[i] H.r[i]=H.r[1]; H.r[1]=temp; HeapAdjust(H, 1, i-1); //调整,使得1~i-1符合堆的定义 }} // HeapSort
9.4.3 筛选算法
void HeapAdjust(HeapType &H, int s, int m) { int j; RedType rc; rc = H.r[s]; //暂存堆顶r[s]到rc for (j=2*s; j<=m; j*=2) { if (j<m && H.r[j].key<H.r[j+1].key){ //横比,j初值指向左孩子 ++j; /*如果右孩子大于左孩子, j指向右孩子, j指示关键字较大位置*/ } if (rc.key >= H.r[j].key) break; //纵比,如果…,定位成功 H.r[s] = H.r[j]; s = j; /*否则,r[j]上移到s,s变为j, 然后j*=2,进入下一层*/ } H.r[s] = rc; // 将调整前的堆顶记录rc到位置s中} //HeapAdjust
9.5 归并排序
9.5.1 归并概述
归并的定义
归并又叫合并,是指把两个 或两个以上的有序序列合并成一个有序序列。
归并示例演示
归并算法实现
9.5.2 二路归并的递归算法
算法思想
算法概要
算法讨论
Q: A: Q: A:
算法分析
算法实现
9.5.3 三路归并与k路归并
三路归并简介
k路归并简介
9.6 基数排序
算法思想
算法概要
算法讨论
Q: A: Q: A:
算法分析
算法实现

 浙公网安备 33010602011771号
浙公网安备 33010602011771号