大数据ETL开发之图解Kettle工具入门到精通(经典转载)
大数据ETL开发之图解Kettle工具(入门到精通)
置顶
袁袁袁袁满
文章目录
第0章 ETL简介
第1章 Kettle简介
1.1 Kettle是什么
1.2 Kettle的两种设计
1.3 Kettle的核心组件
1.4 Kettle的特点
第2章 Kettle安装部署
2.1 Kettle 下载
2.1.1 下载地址
2.1.2 Kettle目录说明
2.1.2 Kettle 文件说明
2.2 Kettle 安装部署
2.2.1 概述
2.2.2 安装
2.3 Kettle 界面介绍
2.3.1 主界面
2.3.2 转换
2.3.3 作业
2.4 Kettle转换初次体验
2.5 Kettle 核心概念
2.5.1 可视化编程
2.5.2 转换
2.5.3 步骤
2.5.4 跳(Hop)
2.5.5 元数据
2.5.6 数据类型
2.5.7 并行
2.5.8 作业
第3章 Kettle的转换
3.1 Kettle输入控件
3.1.1 CSV文件输入
3.1.2 文本文件输入
3.1.3 Excel文件输入
3.1.4 XML输入
3.1.5 JSON输入
3.1.6 表输入
3.2 Kettle输出控件
3.2.1 Excel输出
3.2.2 文本文件输出
3.2.3 SQL文件输出
3.2.4 表输出
3.2.5 更新&插入/更新
3.2.6 删除
3.3 Kettle转换控件
3.3.1 Concat fields
3.3.2 值映射
3.3.3 增加常量&增加序列
3.3.4 字段选择
3.3.5 计算器
3.3.6 字符串剪切&替换&操作
3.3.7 排序记录&去除重复记录
3.3.8 唯一行(哈希值)
3.3.9 拆分字段
3.3.10 列拆分为多行
3.3.11 行扁平化
3.3.12 列转行
3.3.13 行转列
3.4 Kettle应用控件
3.4.1 替换NULL值
3.4.2 写日志
3.5 Kettle流程控件
3.5.1 Switch/case
3 .5.2 过滤记录
3.5.3 空操作
3.5.3 中止
3.6 Kettle查询控件
3.6.1 数据库查询
3.6.2 流查询
3.7 Kettle连接控件
3.7.1 合并记录
3.7.2 记录集连接
3.8Kettle统计控件
3.8.1 分组
3.9 Kettle映射控件
3.9.1 映射
3.10 Kettle脚本控件
3.10.1执行SQL脚本
第4章 Kettle作业
4.1 作业简介
4.1.1作业项
4.1.2 作业跳
4.2 作业初体验
第5章 Kettle使用案例
5.1 转换案例
5.2 作业案例
第6章 Kettle资源库
6.1 数据库资源库
第7章 Kettle调优
第八章 案例数据
第0章 ETL简介
ETL (Extract-Transform-Load 的缩写,即数据抽取、转换、装载的过程),对于企业或行业应用来说,我们经常会遇到各种数据的处理,转换,迁移,所以了解并掌握一种ETL工具的使用,必不可少。
市面上常用的ETL工具有很多,比如Sqoop,DataX, Kettle, Talend 等,作为一个大数据工程师,我们最好要掌握其中的两到三种,这里我们要学习的ETL工具是Kettle!
第1章 Kettle简介
1.1 Kettle是什么
Kettle是一款国外开源的ETL工具,纯java编写,可以在Window、Linux、 Unix.上运行,绿色无需安装,数据抽取高效稳定。
Kettle中文名称叫水壶,该项目的主程序员MATT希望把各种数据放到一个壶里,然后以一种指定的格式流出。
Kettle这个ETL工具集,它允许你管理来自不同数据库的数据,通过提供一个图形化的用户环境来描述你想做什么,而不是你想怎么做。
Kettle中有两种脚本文件,transformation 和 job,transformation 完成针对数据的基础转换,job则完成整个工作流的控制。
Kettle(现在已经更名为PDI, Pentaho Data Integration Pentaho数据集成)
1.2 Kettle的两种设计
简述:
Transformation (转换) :完成针对数据的基础转换。
Job (作业) :完成整个工作流的控制。
区别:
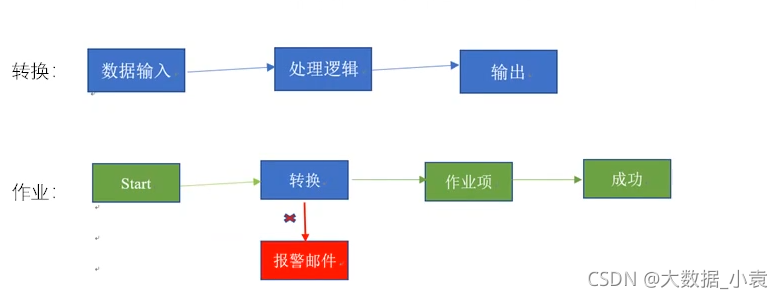
(1) 作业是步骤流,转换是数据流。这是作业和转换最大的区别。
(2)作业的每一个步骤,必须等到前面的步骤都跑完了,后面的步骤才会执行;而转换会一次性把所有控件全部先启动(一个控件对应启动一个线程),然后数据流会从第一个控件开始,一条记录、一条记录地流向最后的控件;
1.3 Kettle的核心组件
Spoon.bat / spoon.sh(重点):是一个图形化界面,可以让我们用图形化的方式开发转换和作业(Windows选择Spoon.bat;Linux选择Spoon.sh)
Pan.bat / pan.sh:利用Pan可以用命令行的形式执行由Spoon编辑的转换和作业
Kitchen.bat / kitchen.sh:利用Kitchen可以使用命令调用由Spoon编辑好的Job
Carte.bat / Carte.sh:Carte是一个轻量级的Web容器,用于建立专用、远程的ETL Server
1.4 Kettle的特点
第2章 Kettle安装部署
2.1 Kettle 下载
2.1.1 下载地址
官网:官网地址
下载地址:各版本下载链接
百度网盘:百度网盘地址 ,提取码:g5nq
2.1.2 Kettle目录说明
2.1.2 Kettle 文件说明
2.2 Kettle 安装部署
2.2.1 概述
在实际企业开发中,都是在本地Windows环境下进行 kettle 的 job 和 Transformation 开发的,可以在本地运行,也可以连接远程机器运行
2.2.2 安装
1)安装 jdk,版本建议1.8及以上
2)下载kettle压缩包,因kettle为绿色软件,解压缩到任意本地路径即可
3)双击Spoon.bat,启动图形化界面工具,就可以直接使用了
2.3 Kettle 界面介绍
2.3.1 主界面
2.3.2 转换
2.3.3 作业
2.4 Kettle转换初次体验
体验案例:将 csv 文件用 Kettle 转换成 excel 文件
1)在 Kettle 中新建一个转换,然后选择转换下面的 “csv文件输入” 和 “excel文件输出” 拖至工作区
2)双击CSV文件输入文件控件,在弹出的设置框里找到对应的csv文件(test.csv).然后点击下面的获取字段按钮,将我需要的字段加载到kettle中
3)按住键盘 shift 键,并且点击鼠标左键将两个控件链接起来,链接时选择 “主输出步骤”
4)双击Excel输出控件,在弹出的设置框里设置文件输出路径和文件名称,然后点击上的字段框,依次点击下面的获取字段和最小宽度,获取到输出字段
5)点击运行,启动,查看转换好的文件
转换成功:
2.5 Kettle 核心概念
2.5.1 可视化编程
Kettle可以被归类为可视化编程语言,因为Kettle可以使用图形化的方式定义复杂的ETL程序和工作流。
可视化编程一直是Kettle里的核心概念,它可以让你快速构建复杂的ETL作业和减低维护工作量。它通过隐藏很多技术细节,使IT领域更贴近于商务领域。
Kettle里的代码就是转换和作业。
2.5.2 转换
转换(transaformation)负责数据的输入、转换、校验和输出等工作。Kettle 中使用转换完成数据 ETL 全部工作。转换由多个步骤(Step)组成,如文本文件输入,过滤输出行,执行SQL脚本等。各个步骤使用跳(Hop)(连接箭头) 来链接。跳定义了一个数据流通道,即数据由一个步骤流(跳)向下一个步骤。在 Kettle中数据的最小单位是数据行(row),数据流中流动其实是缓存的行集(RowSet)
2.5.3 步骤
步骤(控件)是转换里的基本的组成部分,快速入「]的案例中就存在两个步骤,“CSV文件输入” 和 “Excel输出”。
一个步骤有如下几个关键特性:
1.步骤需要有一个名字,这个名字在同一个转换范围内唯一
2.每个步骤都会读、写数据行(唯一例外是 “生成记录”步骤,该步骤只写数据
3.步骤将数据写到与之相连的一个或多个输出跳(hop),再传送到跳的另一端的步骤。
4.大多数的步骤都可以有多个输出跳。–个步骤的数据发送可以被设置为分发和复制,
分发是目标步骤轮流接收记录,复制是所有的记录被同时发送到所有的目标步骤
2.5.4 跳(Hop)
跳就是步骤之间带箭头的连线,跳定义了步骤之间的数据通路
跳实际上是两个步骤之间的被称之为行集的数据行缓存,行集的大小可以在转换的设置里定义。当行集满了,向行集写数据的步骤将停止写入,直到行集里又有了空间。当行集空了,丛行集读取数据的步骤停止读取,直到行集里又有可读的数据行
2.5.5 元数据
每个步骤在输出数据行时都有对字段的描述,这种描述就是数据行的元数据。
通常包含下面一些信息:
名称:数据行里的字段名是唯一的。
数据类型:字段的数据类型。
格式:数据显示的方式,如 Integer 的 #、0.00
长度:字符串的长度或者 BigNumber 类型的长度。
精度:BigNumber数据类型的十进制精度。
货币符号:¥
小数点符号:十进制数据的小数点格式。不同文化背景下小数点符号是不同的,一般是点“.”或 逗号“,”
分组符号:数值类型数据的分组符号,不同文化背景下数字里的分组符号也是不同的,一般是点“.”或逗号“,”或单引号 ’
2.5.6 数据类型
数据以数据行的形式沿着步骤移动。一个数据行是零到多个字段的集合,字段包含下面几种数据类型。
String:字符类型数据
Number:双精度浮点数。
Integer:带符号长整型(64位)。
BigNumber:任意精度数据。
Date:带毫秒精度的日期时间值。
Boolean:取值为true和false的布尔值。
Binary:二进制字段可以包含图像、声音、视频及其他类型的二进制数据。
2.5.7 并行
跳的这种基王行集缓在的规则允许每个步骤都是由一个独立的线程运行,这样并发程度最高。这一规则也允许数据以最小消耗内存的数据流的方式来处理。在数据仓库里,我们经常要处理大量数据,所以这种高并发低消耗的方式也是 ETL 工具的核心需求。
对于 kettle 的转换,不能定义一个执行顺序,因为所有步骤都以并发方式执行:当转换启动后,所有步骤都同时启动,从它们的输入跳中读取数据,并把处理过的数据写到输出跳,直到输入跳里不再有数据,就中止步骤的运行。当所有的步骤都中止了,整个转换就中止了。
如果你想要一个任务沿着指定的顺序执行,那么就要使用下面所讲的“作业”!
2.5.8 作业
作业(Job),负责定义一个完成整个工作流的控制,比如将转换的结果发送邮件给相关人员。因为转换(transformation) 以并行方式执行,所以必须存在一个串行的调度工具来执行转换,这就是Kettle 中的作业。
第3章 Kettle的转换
3.1 Kettle输入控件
输入是转换里面的第一个分类, 输入控件也是转换中的第一大控件, 用来抽取数据或者生成数据。输入是ETL里面的E (Extract),主要做数据提取的工作。
由于Kettle中自带的输入控件比较多,本文只挑出开发中经常使用的几个输入控件来进行讲解,详情如下图:
3.1.1 CSV文件输入
CSV 文件是一个用逗号分隔的固定格式的文本文件,这种文件后缀名为.csv,可以用Excel或者文本编辑器打开。在企业里面一般最常见的 ETL 需求就是将 csv 文件转换为 excel 文件,如果用 Kettle 来做这个 ETL工作,就需要用到本章节讲解的CSV文件输入控件。
任务:熟悉CSV文件输入控件,并尝试将CSV文件转换成Excel文件(可参考上面的快速体验案例)。
步骤名称:可以修改,但是在同一个转换里面要保证唯一 性, 见名知意
文件名:选择对应的csv文件
列分隔符:默认是逗号(不用改)
封闭符:结束行数据的读写(不用改)
NIO 缓存大小:文件如果行数过多,需要调整此参数
包含列头行:意思是文件中第一行是字段名称行,表头不进行读写
行号字段:如果文件第一行不是字段名称或者需要从某行开始读写,可在此输入行号。
并发运行? :选择并发,可提高读写速度
字段中有回车换行? :不要选择,会将换行符做数据读出
文件编码:如果预览数据出现乱码,可更换文件编码
3.1.2 文本文件输入
提取服务器上的日志信息是公司里 ETL开发很常见的操作,日志信息基本上都是文本类型,因此文本文件输入控件是kettle中常用的一个输入控件。
任务:熟悉文本文件输入控件,并新建转换,将txt日志文件转换为Excel文件
使用文本文件输入控件步骤:
1) 添加需要转换的日志文件
2)按照日志文件格式,指定分隔符
3)获取下字段,并给字段设置合适的格式(数字类型的数据尽量选Integer,因为number类型有两位小数点)
4)最后点下预览记录,看看能否读到数据
3.1.3 Excel文件输入
Excel输入控件也是很常用的输入控件,一般企业里会用此控件对大量的Excel文件进行ETL操作。
任务:两张sheet表合二为一
使用Excel输入控件步骤如下:
原始数据:
1)按照读取的源文件格式指定对应的表格类型为 xls 还是 xlsx
2)选择并添加对应的excel文件
3)获取excel的sheet工作表
4)获取字段,并给每个字段设置合适的格式
5)预览数据
3.1.4 XML输入
1)XML简介
XML可扩展标记语言eXtensible MarkupLanguage,由W3C组织发布,目前推荐遵守的是W3C组织于2000年发布的XML1.0规范。XML用来传输和存储数据,就是以一个统一的格式,组织有关系的数据,为不同平台下的应用程序服务。
2)XPath简介
XPath即为XML路径语言(XML Path Language),它是一种用来确定XML文档中某部分位置的语言。XPath基于XML的树状结构,提供在数据结构树中找寻节点的能力。XPath使用路径表达式在XML文档中选取节点。下面列出了最有用的路径表达式
3)XML输入控件
了解XML和XPath概念以后,我们要开始学习Kettle的XML输入控件,企业里经常用此控件进行XML文件的ETL操作。
任务:熟悉XML输入控件,将XML文件的学生数据写到excel文件中
1.浏览获取xml文件,将xml文件添加到kettle中
2.获取 xml文档的所有路径,设置合适的循环读取路径
3.获取字段,获得自己想要读取的所有字段,并且设置适当的格式
4.预览数据,看看能否读取到自己想要的数据
3.1.5 JSON输入
1)JSON介绍
JSON(JavaScript Object Notation,JS对象简谱)是一种轻量级的数据交换格式。JSON对象本质上就是一个JS对象,但是这个对象比较特殊,它可以直接转换为字符串,在不同语言中进行传递,通过工具又可以转换为其他语言中的对象。
JSON核心概念:
数组:[]
对象:{}
属性:key:value
2)JSON Path
JSONPath 类似于 XPath 在 xml 文档中的定位,JsonPath 表达式通常是用来路径检索或设置Json的。其表达式可以接受“dot - notation”(点记法)和“bracket -notation”(括号记法)
格式:
点记法:$.store.book[0]title
括号记法:$[‘store’][‘book’ ][0][ ‘ title’ ]
3)JSON 输入控件
了解JSON格式和JSON Path以后,我们要学习使用JSON输入控件,JSON控件也是企业里做ETL常用的控件之一
任务:获取到JSON文件里面的id,field,value字段,写到excel文件中
原始数据:
1.浏览获取JSON文件(注意文件路径不能有中文),将json文件获取到kettle中
2.根据JSON Path点记法,获取到需要的字段,并且设置合适格式
3)新建JSON输入控件2
第二步的数据内容为:
3.1.6 表输入
表输入可以说是kettle中用到最多的一种输入控件, 因为企业中大部分的数据都会存在数据库中。kettle可以连接市面上常见的各种数据库,比如Oracle,Mysql, SqlServer等。但是在连接各个数据库之前,我们需要先配置好对应的数据库驱动,本教程以mysql为例,给大家讲解kettle连接mysql数据库的过程。
1)创建数据库连接
MySQL驱动下载(一定要下载对应数据库版本):官网下载地址
首先我们要将对应版本的mysql连接驱动放到kettle 安装目录下面的lib文件夹下,然后重启kettle 的客户端Spoon
重启Spoon客户端以后,我们就可以创建对应的数据库连接了,在转换视图的主对象树目录下,有个DB连接,右键然后选择新建,在打开数据库连接框里,填写正确的数据库信息,然后测试,测试无误后,可以保存此数据库连接。
数据库连接默认只对本转换有效,换一个转换以后,这个连接就没法用了,还需要新建数据库连接,所以我们需要将建好的这个数据库连接进行共享下,共享以后,其他的转换也能用我们提前建好的这个数据库连接了。
2)表输入
创建好数据库连接以后,我们就可以使用表输入控件了,双击表输入控件,选择刚刚创建的数据库连接,然后在SQL框里输入合适的查询语句,然后点击预览按钮,看能否预览到我们期望的数据
3.2 Kettle输出控件
输出是转换里面的第二个分类,输出控件也是转换中的第二大控件,用来存储数据。输出是ETL里面的L(Load),主要做数据加载的工作。
由于Kettle中自带的输出控件比较多,本文只挑出开发中经常使用的几个输出控件来进行讲解,详情如下图
3.2.1 Excel输出
Kettle中自带了两个Excel输出,一个Excel输出,另一个是Microsoft Excel输出。Excel输出只能输出xls文件(适合Excel2003),Microsoft Excel输出可以输出xls和xlsx文件(适合Excel2007及以后)
Excel输出大家已经很熟悉了,本章不再赘述,接下来给大家讲下Microsoft Excel输出。
1)选择合适的扩展名
2)点击浏览,补全输出文件的路径已经文件名
3.2.2 文本文件输出
文本文件输出控件,顾名思义,这是一个能将数据输出成文本的控件,比较简单,在企业里面也比较常用。
1.设置对应的目录和文件名
2.设置合适的扩展名,比如txt,csv等
3.在内容框里设置合适的分隔符,比如分号,逗号,TAB等
4.在字段框里获取字段,并且给每个字段设置合适的格式
3.2.3 SQL文件输出
SQL文件输出一般跟表输入做连接,然后将数据库表的表结构和数据以sql文件的形式导出,然后做数据库备份的这么一个工作。(Kettle里面没varchar类型尽量少用)
1.选择合适的数据库连接
2.选择目标表
3.勾选增加创建表语句和每个语句另起一行
4.填写输出文件的路径和文件名
5.扩展名默认为sql,这个不需要更改
3.2.4 表输出
表输出控件可以将kettle数据行中的数据直接写入到数据库中的表中,企业里做ETL工作会经常用到此控件。
1.选择合适的数据库连接
2.选择目标表,目标表可以提前在数据库中手动创建好,也可以输入一个数据库不存在的表,然后点击下面的SQL按钮,利用kettle现场创建
3.如果目标表的表结构和输入的数据结构不一致,还可以自己指定数据库字段
3.2.5 更新&插入/更新
更新和插入/更新,这两个控件是kettle提供的将数据库已经存在的记录与数据流里面的记录进行对比的控件。企业级ETL 经常会用到这两个控件来进行数据库更新的操作
两者区别:
更新是将数据库表中的数据和数据流中的数据做对比,如果不同就更新,如果数据流中的数据比数据库表中的数据多,那么就报错。
插入/更新的功能和更新一样,只不过优化了数据不存在就插入的功能,因此企业里更多的也是使用插入/更新。
步骤:
1.选择正确的数据库连接
2.选择目标表
3.输入两个表来进行比较的字段,一般来说都是用主键来进行比较
4.输入要更新的字段
3.2.6 删除
删除控件可以删除数据库表中指定条件的数据,企业里一般用此控件做数据库表数据删除或者跟另外一个表数据做对比,然后进行去重的操作。
1.选择数据库连接
2.选择目标表
3.设置数据流跟目标表要删除数据的对应字段
3.3 Kettle转换控件
转换控件是转换里面的第四个分类,转换控件也是转换中的第三大控件,用来转换数据。转换是ETL里面的T(Transform),主要做数据转换,数据清洗的工作。ETL整个过程中,Transform的工作量最大,耗费的时间也比较久,大概可以占到整个ETL的三分之二。
由于Kettle中自带的转换控件比较多,本文只挑出开发中经常使用的几个转换控件来进行讲解,详情如下图。
3.3.1 Concat fields
转换控件Concat fields,顾名思义,就是将多个字段连接起来形成一个新的字段
任务:将staff表的firstname和lastname拼接起来,形成name字段,然后再将数据插入到新表emp中
原始数据:
3.3.2 值映射
值映射就是把字段的一个值映射(转换)成其他的值。在数据质量规范上使用非常多,比如很多系统对应性别sex字段的定义不同。所以我们需要利用此控件,将同一个字段的不同的值,映射转换成我们需要的值。
任务:将staff表的sex字段,映射成男or女,然后再插入到emp表中
原始数据:
1.选择映射的字段
2.还可以自定义映射完以后的新字段名
3.可以设置不匹配时的默认值
4.设置映射的值
3.3.3 增加常量&增加序列
增加常量就是在本身的数据流里面添加一列数据,该列的数据都是相同的值。
增加序列是给数据流添加一个序列字段,可以自定义该序列字段的递增步长。
任务:给表staff的数据加一列固定值slary和一个递增的number序列,在控制台预览下数据即可,不用输出
3.3.4 字段选择
字段选择是从数据流中选择字段、改变名称、修改数据类型。
任务:在上一章节的转换之后,添加字段选择控件,移除掉firstname字段,并且将lastname重命名为name,将slary重命名为money,然后再次预览数据,查看数据的变化
3.3.5 计算器
计算器是一个函数集合来创建新的字段,还可以设置字段是否移除(临时字段)。我们可以通过计算器里面的多个计算函数对已有字段进行计算,得出新字段。
任务:在上一节的任务基础之上,添加计算器控件对money和number字段进行相乘,得出新字段acount,然后预览数据
执行结果:
3.3.6 字符串剪切&替换&操作
转换控件中有三个关于字符串的控件,分别是剪切字符串,字符串操作,字符串替换
剪切字符串是指定输入流字段裁剪的位置剪切出新的字段
字符串替换是指定搜索内容和替换内容,如果输入流的字段匹配上搜索内容就进行替换生成新字段
字符串操作是去除字符串两端的空格和大小写切换,并生成新的字段
执行结果:
3.3.7 排序记录&去除重复记录
去除重复记录是去除数据流里面相同的数据行。但是此控件使用之前要求必须先对数据进行排序,对数据排序用的控件是排序记录,排序记录控件可以按照指定字段的升序或者降序对数据流进行排序。因此排序记录+去除重复记录控件常常配合组队使用。
任务:利用excel输入控件读取input目录下的06_去除重复记录.xlsx,然后对里面重复的数据进行按照id排序并去重
原始数据:
执行结果:
3.3.8 唯一行(哈希值)
唯一行(哈希值)就是删除数据流重复的行。此控件的效果和(排序记录+去除重复记录)的效果是一样的,但是实现的原理不同。排序记录+去除重复记录对比的是每两行之间的数据,而唯一行(哈希值)是给每一行的数据建立哈希值,通过哈希值来比较数据是否重复,因此唯一行(哈希值)去重效率比较高,也更建议大家使用。
任务:利用唯一行(哈希值)控件对06_去除重复记录.xlsx去重,并且查看最后输出的数据跟上个任务有何区别
执行结果:
3.3.9 拆分字段
拆分字段是把字段按照分隔符拆分成两个或多个字段。需要注意的是,字段拆分以后,原字段就会从数据流中消失。
任务:将拆分字段.xlsx里面的NBA球星的姓名,拆分成姓跟名
文件内容:
执行结果:
3.3.10 列拆分为多行
列拆分为多行就是把指定字段按指定分隔符进行拆分为多行,然后其他字段直接复制。具体效果如下图:
任务:对08_列拆分为多行.xlsx的数据按照hobby字段进行拆分为多行,然后将新数据输出到excel文件中,查看数据
原始数据:
1.选择要拆分的字段
2.设置合适的分割符
3.设置分割以后的新字段名
4.选择是否输出新数据的排列行号,行号是否重置
执行结果:
3.3.11 行扁平化
行扁平化就是把同一组的多行数据合并成为一行,可以理解为列拆分为多行的逆向操作
但是需要注意的是行扁平化控件使用有两个条件:
1)使用之前需要对数据进行排序
2)每个分组的数据条数要保证一致,否则数据会有错乱
任务:将09_行扁平化.xlsx的数据按照hobby字段进行扁平化
原始数据:
1.选择扁平化的字段
2.填写目标字段,字段个数跟每个分组的数据一致
3.3.12 列转行
列转行,顾名思义多列转一行,就是如果数据一列有相同的值,按照指定的字段,将其中一列的字段内容变成不同的列,然后把多行数据转换为一行数据的过程。具体效果如下图
:
注意:列转行之前数据流必须按照分组字段进行排序,否则数据会错乱!
任务:将input目录下的10_列转行.xlsx的数据进行列转行,熟悉列转行控件的使用
原始数据:
1.关键字段:从数据内容变成列名的字段
2.分组字段:列转行,转变以后的分组字段
3.目标字段:增加的列的列名字段
4.数据字段:目标字段的数据字段
5.关键字值:数据字段查询时的关键字,也可以理解为key
6.类型:要给目标字段设置合适的类型,否则会报错
执行结果:
3.3.13 行转列
行转列,一行转多列,就是把数据字段的字段名转换为一列,把数据行变为数据列。我们也可以简单理解为行转列控件是列转行控件的逆向操作。具体如下图:
任务:将行转列.xlsx用excel控件输入,然后行转列,熟悉行转列控件的使用。
原始数据:
1.Key字段:行转列,生成的列名字段名
2.字段名称:原本数据流中的字段名
3.Key值:Key字段的值,这个是自己自定义的,一般都跟前面的字段名称一样
4.Value字段:对应的Key值的数据列的列名
执行结果:
3.4 Kettle应用控件
应用是转换控件里面的第五个分类,这个分类下是Kettle给我们自带的一些工具类
3.4.1 替换NULL值
替换NULL值,顾名思义就是将数据里面的null值替换成其他的值,此控件比较简单,但是在企业里面也会经常用到。
1.可以选择替换数据流中所有字段的null值
2.也可以选择字段,在下面的字段框里面,根据不同的字段,将null值替换成不同的值
任务:替换excel数据12_替换NULL值.xlsx的bonus列的null值为0
原始数据:
执行结果:
3.4.2 写日志
写日志控件主要是调试的时候使用,此控件可以将数据流的每行数据打印到控制台,方便我们调试整个程序。
1.选择日志级别
2.可以输入自定义输出的语句
3.选择要输出打印的字段
任务:在上个任务的基础之上,添加写日志控件,在控制台输出查看数据
执行结果:
3.5 Kettle流程控件
流程是转换里面的第六个分类,流程分类下的控件主要用来控制数据流程和数据流向。
3.5.1 Switch/case
Switch/case控件,最典型的数据分类控件,可以利用某一个字段的数据的不同的值,让数据流从一路到多路。
任务:将excel:13_Switch-Case.xlsx的数据按照部门字段进行分类,将同一个部门的数据输出到一个excel中
原始数据:
1.选择需要判断的字段
2.选择判断字段的值的类型
3.填写分类数据的判断条件和目标步骤
执行结果:
3 .5.2 过滤记录
和Switch/case做对比的话,过滤记录相当于if-else,可以自定义输入一个判断条件,然后将数据流中的数据一路分为两路
任务:将数据按照工资字段进行判断,将工资在20000及以上的数据输出到一个excel中,将工资小于20000的输出到另外一个excel中
原始数据:
1.在下面先填写数据的判断条件
2.然后再上面选择下判断条件为true或者false的输出步骤
执行结果:
3.5.3 空操作
空操作,顾名思义就是什么也不做,此控件一般作为数据流的终点。
任务:修改上节的转换任务,将工资大于等于20000的数据输出,小于20000的数据直接丢弃,熟悉空操作控件的使用。
3.5.3 中止
中止是数据流的终点,如果有数据流到此控件处,整个转换程序将中止,并且在控制台输出报错信息。此控件一般用来校验数据,或者调试程序。
任务:使用中止控件判断上节任务中是否有人的工资低于20000,如果发现有人的工资低于20000的话,中止程序,并在控制台输出信息。
3.6 Kettle查询控件
查询是转换里面的第九个分类,查询控件是用来查询数据源里面的数据,并合并到主数据流中。
3.6.1 数据库查询
数据库查询就是从数据库里面查询出数据,然后跟数据流中的数据进行左连接的一个过程。左连接的意思是数据流中原本的数据全部有,但是数据库查询控件查询出来的数据不一定全部会列出,只能按照输入的匹配条件来进行关联。
任务:利用表输入控件获取到staff表的数据,然后利用数据库查询控件查询到department表的数据,然后对两个表按照dept_id字段进行左连接,并预览数据
原始数据:
1.选择合适的数据库链接
2.输入要去数据库里面查询的表名
3.输入两个表进行左连接的连接条件
4.获取返回字段,得到查询表返回的值
执行结果:
3.6.2 流查询
流查询控件就是查询两条数据流中的数据,然后按照指定的字段做等值匹配。注意:流查询在查询前把数据都加载到内存中,并且只能进行等值查询。
任务:用流查询控件,将staff和department的数据按照dept_id字段进行关联起来
1.输入查询的数据流
2.输入两个流进行匹配的字段(等值匹配)
3.输入查询出的字段
执行结果:
3.7 Kettle连接控件
连接是转换里面的第十个分类,连接分类下的控件一般都是将多个数据集通过关键字进行连接起来,形成一个数据集的过程。
3.7.1 合并记录
合并记录是用于将两个不同来源的数据合并,这两个来源的数据分别为旧数据和新数据,该步骤将旧数据和新数据按照指定的关键字匹配、比较、合并。注意旧数据和新数据需要事先按照关键字段排序,并且旧数据和新数据要有相同的字段名称。
合并后的数据将包括旧数据来源和新数据来源里的所有数据,对于变化的数据,使用新数据代替旧数据,同时在结果里用一个标示字段,来指定新旧数据的比较结果。
任务:利用合并记录控件比较合并记录-新旧excel的数据,并预览数据,查看标志字段的内容
原始数据:
1.旧数据源:选择旧数据来源的步骤
2.新数据源:选择新数据来源的步骤
3.标志字段:设置标志字段的名称,标志字段用于保存比较的结果,比较结果有下列几种:
①“identical” – 旧数据和新数据一样
②“changed” – 数据发生了变化;
③“new” – 新数据中有而旧数据中没有的记录
④“deleted” –旧数据中有而新数据中没有的记录
4.关键字段:用于定位判断两个数据源中的同一条记录的字段。
5.比较字段:对于两个数据源中的同一条记录,指定需要比较的字段
执行结果:
3.7.2 记录集连接
记录集连接可以对两个步骤中的数据流进行左连接,右连接,内连接,外连接。此控件功能比较强大,企业做ETL开发会经常用到此控件,但是需要注意在进行记录集连接之前,需要对记录集的数据进行排序,并且排序的字段还一定要选两个表关联的字段,否则数据错乱,出现null值。
任务:使用记录集连接控件对数据库表satff和department按照部门id分别进行内连接,左连接,右连接,外连接,查看数据的不同
原始数据:
注意:两个表进行排序记录的时候,排序的字段一定要选择部门id,否则数据会不正确
1.选择需要连接的两个数据流的步骤
2.选择连接类型,一共有四个:INNER,LEFT OUTER,RIGHT OUTER,FULL OUTER
3.从两个数据流步骤里面选出连接字段
执行结果:
3.8Kettle统计控件
统计是转换里面的第十三个分类,统计控件可以提供数据的采样和统计功能。
3.8.1 分组
分组控件的功能类似于GROUP BY,可以按照指定的一个或者几个字段进行分组,然后其余字段可以按照聚合函数进行合并计算。注意,在进行分组之前,数据最好先进行排序。
任务:给表staff的数据按照部门进行分组,求出各部门人数以及各部门员工的平均年龄。
原始数据:
1.选择分组字段
2.给其余字段选择合适的聚合函数进行计算
执行结果:
3.9 Kettle映射控件
映射是转换里面的第十八个分类,映射可以用来定义子转换,方便代码封装和重用。
3.9.1 映射
映射(子转换)是用来配置子转换,对子转换进行调用的一个步骤。
映射输入规范是输入字段,由调用的转换输入。
映射输出规范是向调用的转换输出所有列,不做任何处理
任务:封装一个子转换能够通过dept_id求出dept_name,然后使用另外一个转换调用此子转换,求出数据库staff表id=3的员工的姓名,年龄,部门id,部门姓名,并输出到控制台。
执行结果:
3.10 Kettle脚本控件
脚本是转换的第七个分类,脚本就是直接通过写程序代码完成一些复杂的操作。
3.10.1执行SQL脚本
执行sql脚本控件就是连接到数据库里面,然后执行自己写的一些sql语句
任务:利用执行sql脚本控件将student表数据的atguigu的年龄更新为18
1.选择合适的数据库连接
2.填入要执行的sql语句
第4章 Kettle作业
4.1 作业简介
大多数ETL项目都需要完成各种各样的维护工作。例如,如何传送文件;验证数据库表是否存在等等。而这些操作都是按照一定顺序完成。因为转换以并行方式执行,就需要一个可以串行执行的作业来处理这些操作。
一个作业包含一个或者多个作业项,这些作业项以某种顺序来执行。作业执行顺序由作业项之间的跳(job hop)和每个作业项的执行结果来决定。
4.1.1作业项
作业项是作业的基本构成部分。如同转换的步骤,作业项也可以使用图标的方式图形化展示。
但是,作业项和转换步骤有下面几点不同:
1.转换步骤与步骤之间是数据流,作业项之间是步骤流。
2.转换启动以后,所有步骤一起并行启动等待数据行的输入,而作业项是严格按照执行顺序启动,一个作业项执行完以后,再执行下一个作业项。
3.在作业项之间可以传递一个结果对象(result object)。这个结果对象里面包含了数据行,它们不是以数据流的方式来传递的。而是等待一个作业项执行完了,再传递个下一个作业项。
4.因为作业顺序执行作业项,所以必须定义一个起点。有一个叫“开始”的作业项就定义了这个点。一个作业只能定一个开始作业项。
4.1.2 作业跳
作业的跳是作业项之间的连接线,他定义了作业的执行路径。作业里每个作业项的不同运行结果决定了做作业的不同执行路径。
作业跳一共分为下面三种情况:
①无条件执行:不论上一个作业项执行成功还是失败,下一个作业项都会执行。这是一种蓝色的连接线,上面有一个锁的图标。
②当运行结果为真时执行:当上一个作业项的执行结果为真时,执行下一个作业项。通常在需要无错误执行的情况下使用。这是一种绿色的连接线,上面有一个对钩号的图标。
③当运行结果为假时执行:当上一个作业项的执行结果为假或者没有成功执行是,执行下一个作业项。这是一种红色的连接线,上面有一个红色的停止图标。
在图标上单击就可以对跳进行设置。
4.2 作业初体验
作业案例:将3.10.1章节的转换嵌入作业中执行,执行成功或者失败都发送邮件提醒
1)点击左上角的文件,新建一个作业
2)按照下图设置作业项和作业跳
3)转换作业项设置,选择要嵌入的转换文件
4)发送邮件作业项设置
5)分别尝试作业执行成功和失败,查看kettle发送的邮件信息
第5章 Kettle使用案例
5.1 转换案例
案例一:把stu1的数据按id同步到stu2,stu2有相同id则更新数据
(1) 在mysql中创建两张表
mysql> create database kettle;
mysql> use kettle;
mysql> create table stu1(id int,name varchar(20),age int);
mysql> create table stu2(id int,name varchar(20));
1
2
3
4
(2) 往两张表中插入一些数据
mysql> insert into stu1 values(1001,'zhangsan',20),(1002,'lisi',18), (1003,'wangwu',23);
mysql> insert into stu2 values(1001,'wukong');
1
2
(3) 在kettle中新建转换
(4) 分别在输入和输出中拉出表输入和插入/更新
(5) 双击表输入对象,填写相关配置,测试是否成功
(6) 双击 更新/插入对象,填写相关配置
(7) 保存转换,启动运行,去mysql表查看结果
执行结果:
5.2 作业案例
案例二:使用作业执行上述转换,并且额外在表stu2中添加一条数据,整个作业运行成功的话发邮件提醒
(1)新建一个作业
(2) 按图示拉取组件
(3) 双击Start编辑Start
(4) 双击转换,选择案例1保存的文件
(5) 双击SQL,编辑SQL语句
(6) 双击发送邮件,编辑发送邮件的设置信息
(7) 保存作业并执行,然后去mysql查看结果和邮件信息
第6章 Kettle资源库
6.1 数据库资源库
数据库资源库是将作业和转换相关的信息存储在数据库中,执行的时候直接去数据库读取信息,很容易跨平台使用
1)点击右上角connect,选择Other Resporitory
-
选择Database Repository
-
建立新连接
-
填好之后,点击finish,会在指定的库中创建很多表,至此数据库资源库创建完成
-
连接资源库,默认账号密码为admin
-
将之前做过的转换导入资源库
(1)选择从xml文件导入
(2)随便选择一个转换
(3)点击保存,选择存储位置及文件名
(4)打开资源库查看保存结果
第7章 Kettle调优
1、调整JVM大小进行性能优化,修改Kettle根目录下的Spoon脚本。
参数参考:
-Xmx2048m:设置JVM最大可用内存为2048M。
-Xms1024m:设置JVM促使内存为1024m。此值可以设置与-Xmx相同,以避免每次垃圾回收完成后JVM重新分配内存。
-Xmn2g:设置年轻代大小为2G。整个JVM内存大小=年轻代大小 + 年老代大小 + 持久代大小。持久代一般固定大小为64m,所以增大年轻代后,将会减小年老代大小。此值对系统性能影响较大,Sun官方推荐配置为整个堆的3/8。
-Xss128k:设置每个线程的堆栈大小。JDK5.0以后每个线程堆栈大小为1M,以前每个线程堆栈大小为256K。更具应用的线程所需内存大小进行调整。在相同物理内存下,减小这个值能生成更多的线程。但是操作系统对一个进程内的线程数还是有限制的,不能无限生成,经验值在3000~5000左右。
2、 调整提交(Commit)记录数大小进行优化,Kettle默认Commit数量为:1000,可以根据数据量大小来设置Commitsize:1000~50000
3、尽量使用数据库连接池;
4、尽量提高批处理的commit size;
5、尽量使用缓存,缓存尽量大一些(主要是文本文件和数据流);
6、Kettle是Java做的,尽量用大一点的内存参数启动Kettle;
7、可以使用sql来做的一些操作尽量用sql;Group , merge , stream lookup,split field这些操作都是比较慢的,想办法避免他们.,能用sql就用sql;
8、插入大量数据的时候尽量把索引删掉;
9、尽量避免使用update , delete操作,尤其是update,如果可以把update变成先delete, 后insert;
10、能使用truncate table的时候,就不要使用deleteall row这种类似sql合理的分区,如果删除操作是基于某一个分区的,就不要使用delete row这种方式(不管是deletesql还是delete步骤),直接把分区drop掉,再重新创建;
11、尽量缩小输入的数据集的大小(增量更新也是为了这个目的);
12、尽量使用数据库原生的方式装载文本文件(Oracle的sqlloader, mysql的bulk loader步骤)。
第八章 案例数据
案例数据下载地址:https://pan.baidu.com/s/1_lzc93xprEaJt6IyflxcZg?pwd=ydao,提取码:ydao
本文根据尚硅谷视频学习写的博客笔记,如有侵权联系删除
袁袁袁袁满
微信公众号
商务合作 | 交流学习 | 资料领取
————————————————
版权声明:本文为CSDN博主「袁袁袁袁满」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/yuan2019035055/article/details/120409547

 浙公网安备 33010602011771号
浙公网安备 33010602011771号