「特征工程」与「表示学习」
https://mp.weixin.qq.com/s/au-U7oNkS0FWNtkHcRsrcw
1.表示学习
当我们学习一个复杂概念时,总想有一条捷径可以化繁为简。机器学习模型也不例外,如果有经过提炼的对于原始数据的更好表达,往往可以使得后续任务事倍功半。这也是表示学习的基本思路,即找到对于原始数据更好的表达,以方便后续任务(比如分类)。
举个简单的例子,假设我们有 \{{x,y\}} ,想要寻找x与y之间的关系。
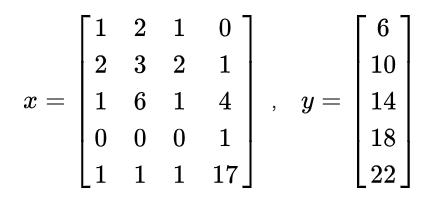
如果单用肉眼看的话,x这个矩阵其实还是比较复杂的,无法直接发现与y间的关系。但如果我们非常幸运,发现x每行相加后的结果 [4,8,12,16,20]^T ,就可以直接看出x与y之间的关系是 y=x+2 。这个例子是为了说明:同样的数据的不同表达,会直接决定后续任务的难易程度,因此找到好的数据表示往往是机器学习的核心任务。值得注意的是,在现实情况中我们所提炼的到表示往往是很复杂的,往往对于高维矩阵提取到特征也是高维矩阵。这个例子仅供抛砖引玉之用,表示学习不等于维度压缩或者特征选择。
2. 特征工程与表示学习:人工 vs. 自动
正因为数据表示的重要性,机器学习一般有两种思路来提升原始数据的表达:
特征学习(feature learning),又叫表示学习(representation learning)或者表征学习,一般指的是自动学习有用的数据特征
特征工程(feature engineering),主要指对于数据的人为处理提取,有时候也代指“洗数据”
不难看出,两者的主要区别在于前者是“学习的过程”,而后者被认为是一门“人为的工程”。用更加白话的方式来说,特征学习是从数据中自动抽取特征或者表示的方法,这个学习过程是模型自主的。而特征工程的过程是人为的对数据进行处理,得到我们认为的、适合后续模型使用的样式。根据这个思路,机器学习模型对于数据的处理可以被大致归类到两个方向:
1. 表示学习:模型自动对输入数据进行学习,得到更有利于使用的特征(*可能同时做出了预测)。代表的算法大致包括:
深度学习,包括大部分常见的模型如CNN/RNN/DBN等
某些无监督学习算法,如主成分分析(PCA)及自编码器(autoencoder)通过对数据转化而使得输入数据更有意义
某些树模型可以自动的学习到数据中的特征并同时作出预测
2. 特征工程:模型依赖人为处理的数据特征,而模型的主要任务是预测,比如简单的线性回归期待良好的输入数据(如离散化后的数据)
至于更加深入的对于数据表示学习的科普,可以参考:微调:人工智能(AI)是如何处理数据的?(https://www.zhihu.com/question/264417928/answer/283087276)
3. 模型选择
回归到问题的本质,就要谈谈什么时候用「手工提取」什么时候用「表示学习」。一种简单的看法是,要想自动学习到数据的良好表达,就需要大量的数据。这个现象也解释了为什么「特征工程」往往在中小数据集上表现良好,而「表示学习」在大量复杂数据上更有用武之地。
而一切的根本,其实在于假设。比如我们会假设数据分布,会假设映射函数的性质,也会假设预测值与输入值间的关系。这一切假设其实并非凭空猜想,而是基于我们对于问题的理解,从某种角度来看,这是一种先验,是贝叶斯模型。在中小数据集上的机器学习往往使用的就是强假设模型(人类知识先验)+一个简单线性分类器。当数据愈发复杂,数据量逐渐加大后,我们对于数据的理解越来越肤浅,做出的假设也越来越倾向于随机,那么此时人工特征工程往往是有害的,而需要使用摆脱了人类先验的模型,比如深度学习或者集成模型。
换句话说,模型选择的过程其实也是在衡量我们对于问题及数据的理解是否深刻,是在人类先验与数据量之间的一场博弈。从这个角度来看,深度学习首先革的是传统机器学习模型的命:最先被淘汰的不是工人,而是特定场景下的传统机器学习模型。
但话说回来,在很多领域数据依然是稀缺的,我们依然需要人工的手段来提炼数据。而这样的尝试其实并不罕见,我也写过一篇「Stacking」与「神经网络」(https://zhuanlan.zhihu.com/p/32896968)介绍如何模拟神经网络在中小数据集上无监督的抽取特征,并最终提升数据的表示。另一个相关的问题是,到底多少数据才算多?可以参考这篇文章:「机器学习」到底需要多少数据?(https://zhuanlan.zhihu.com/p/34523880)。
4. 总结
从这个方向推广出去可以联想到很多热门的话题,比如在问题A上学到的数据表达可以在问题B上使用(迁移学习),抛弃和合并冗余特征(维度压缩与特征选择等)。从本质上来看,这些都是在挖掘数据中的核,即最关键的浓缩信息。
然而,相同的数据对于不同的任务也要求不同的数据表达,最优的数据表示并非是绝对的。类比来看,人类是由细胞组成的,器官也是由细胞组成的。在器官层面来看,细胞是很好的表达。而从人类角度来看,器官是比较好的表达,因为我们可以通过身高体重来区分人,而无法直观地通过细胞来区分人。然而再往前看一步,每个人的细胞携带不同的遗传信息,因此也可以被认为是一种很强的数据表达。讲这个故事的目的是说明,什么是好的数据表达,其实是非常模棱两可的问题,在不同语境下可能大不相同。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号