聊一聊激活函数
聊一聊激活函数
https://mp.weixin.qq.com/s/Gm4Zp7RuTyZlRWlrbUktDA
Why激活函数?
引入激活函数是为了引入非线性因素,以此解决线性模型所不能解决的问题,让神经网络更加powerful!
以下解释部分可以自行选择跳过哦~
如果没有激活函数,那么神经网络将会是这样子

深入了解后我们会神奇的发现,咦?这样一个神经网络组合起来,它的输出居然无论如何都还是一个线性方程哎!

纳尼?那也就是说,就算我组合了一万个神经元,构建了一个看起来相当了不起的神经网络,其效力还是等同于一个线性方程,其效力等同于输入的线性组合。
呃,这样的神经网络未免也太 powless 了。
这个时候就轮到拯救地球的激活函数上场了。
我们在每一个神经元后面加一个激活函数,如σ-函数,如下图所示,这样它就变成非线性的啦~
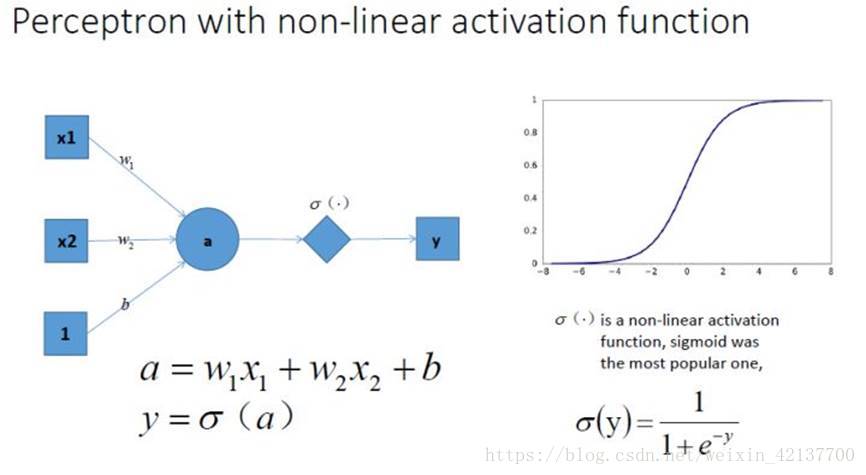
将多个像这样有激活函数的神经元组合起来,我们就可以得到一个相当复杂的函数,复杂到谁也不知道它是什么样的。

引入了非线性激活函数以后, 神经网络的表达能力更加强大了~
注:一般来说,我们说的激活函数都是非线性激活函数,而不是线性激活函数(或称为恒等激活函数)g(z) = z
σ-函数
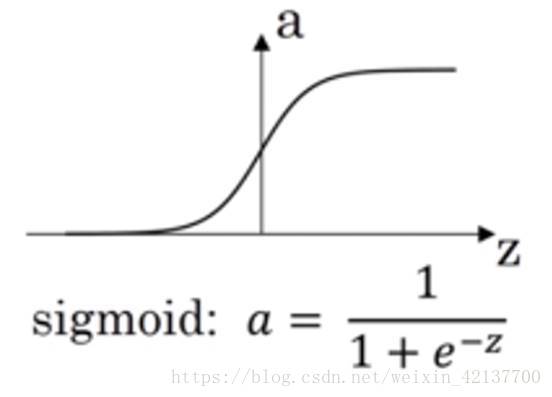
它把输入映射到0-1区间,一般用在输出结果为二分类的输出层。
tanh函数
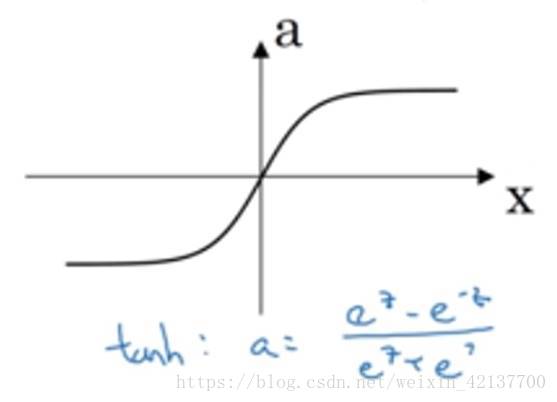

tanh函数它是一个双曲正切函数,仔细一看,你会发现它其实是σ-函数的平移版。
tanh函数总是比σ-函数来得好。因为它介于-1到1之间,激活函数的平均值接近于0,这就有类似数据中心化的效果,使得数值均值为0,而不是0.5。因此,对于非输出层的隐藏层,一般都会选择用tanh函数而不是σ-函数。
ReLU
ReLU的全称是Rectified Linear Unit,修正线性单元。它是最受欢迎的一个激活函数,几乎已经成了隐藏层的默认选项。

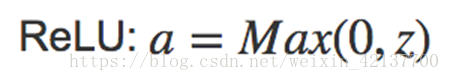
比起σ-函数和tanh函数,ReLU的梯度下降速度快很多。因为它不存在斜率接近于0,学习效率减慢的情况。
Leaky ReLU
ReLU虽好,也存在一个小缺点:当z<0时,导数为0,虽然这在实践过程中并不会带来什么问题。
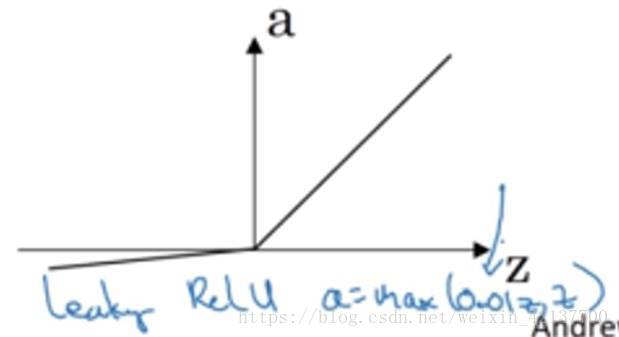
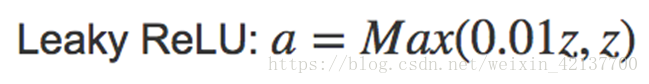
但也催生了另一个版本的ReLU,叫Leaky ReLU。当z<0时,斜率非常平缓,一般表达式为a=max(0.01z, z)。
如何选择激活函数
1.σ-函数一般用在输出结果为二分类的输出层。一般隐藏层选用tanh函数或是ReLU,最常用的是ReLU,具有梯度下降速度快的优点
2.ReLU虽好,但也存在当z为负时,导数为0的小缺点,虽然这在实践过程中并不会带来什么问题,但也可以用Leaky ReLU达到更好的效果,虽然目前Leaky ReLU还是比较少用。
3.凡事无绝对,具体选用什么激活函数还需看情况而定。
参考:
知乎 - 神经网络激励函数的作用是什么?有没有形象的解释?
吴恩达 - 神经网络和深度学习 - 激活函数

 浙公网安备 33010602011771号
浙公网安备 33010602011771号