
test20230912
写在前面的话
考场估分
fprintf(stderr,"%.3lf MB",(&Med-&Mbe)/(1.0*1024*1024));
希望自己以后不要犯这种低级错误。
本场比赛在改完题之后觉得难度为
题目描述
现在有一个长度为
思路点拨
题目非常的简洁,我提供一种自己的做法,不同于
首先十分显然的,对于另个元素
我们想一下,如果知道了我们需要交换
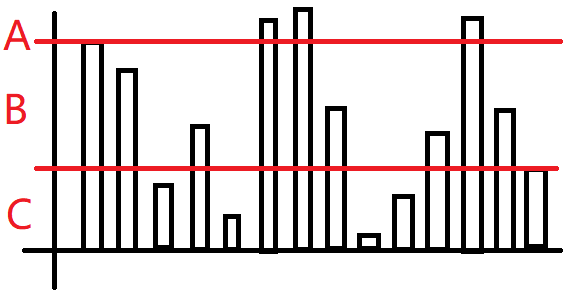
我们将这些数划分为三个部分:
-
-
-
首先,不在这个区间内的元素的逆序对关系并不会边,我们就只需要大胆的考虑这个区间内产生的变化。对于
总体来说,贡献就是
这样的结论显然是不足以写出正解,但是注意到交换
考虑什么样的左上角是有意义的。如果对于一个左上角 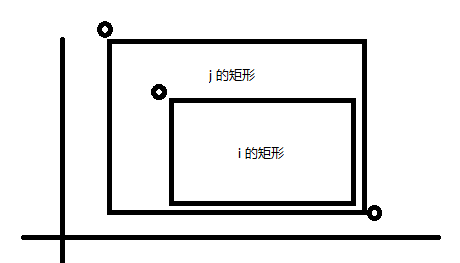
所以谁更加牛逼一目了然吧。我们继续考虑对于右下角有需要满足什么条件。如果存在节点
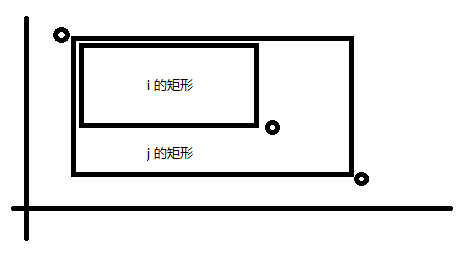
所以我们成功的缩小了左右端点的范围。接下来我们所说的左右端点只考虑这些有用的左右端点。
我们接下来考虑这些有用的左右端点会是什么样的呢?就拿左端点来举例子吧,如果有
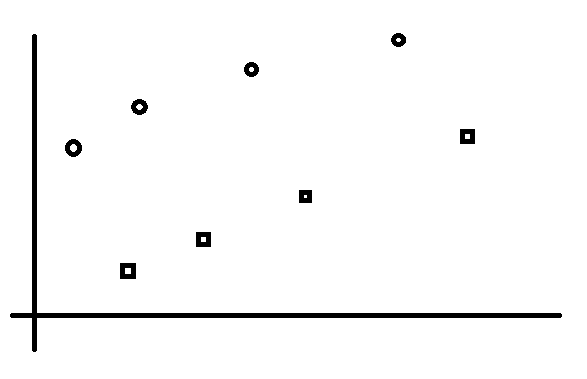
接下来,我们发现,一个元素对一些右下角端点做出贡献,并且这些右下角端点是一段连续的端点:
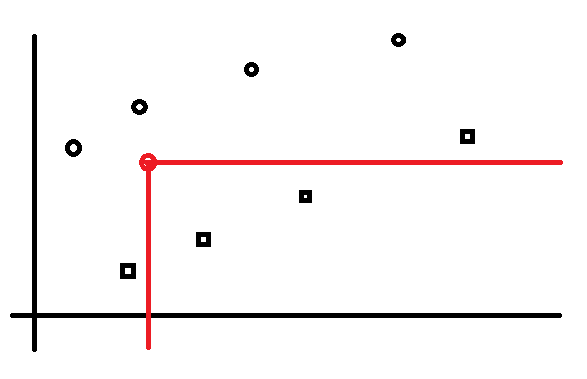
红色的部分就是可以产生贡献的左端点,显然是连续的。为什么会这样,这是因为右下角端点的单调性导致的,可以使用反证。可以感性理解一下,相信还是比较好懂的。同理,我们也就知道了,对于一个左上角来说,他可以使用的右下角是一段连续的区间。对于每一个节点(不论是否有效),我们都可以使用二分法求出那些左端点可以产生贡献,可以使用二分来求。
还是讲一下怎么来二分求吧。我们先对数组
mn[n+1]=n+1;
for(int i=n;i;i--) mn[i]=min(mn[i+1],a[i]);
while(l<r){
int mid=(l+r)/2+1;
if(mn[mid]<i) l=mid;
else r=mid-1;
}
我们假设有一个数组
我们先求出
接下来,我们考虑
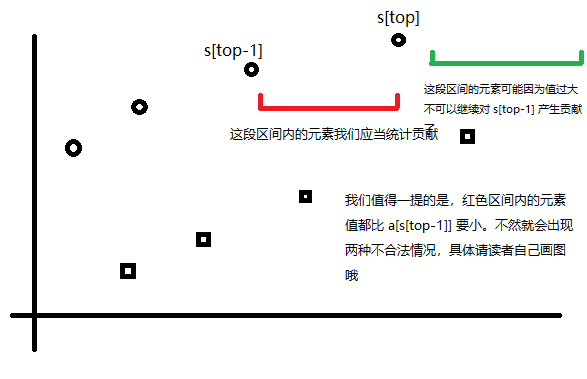
可以看见,我们就是剩下两个区间的内容需要统计,我们分开讨论:
- 红色部分
这一部分十分简单,我们直接暴力枚举每一个元素,然后再线段树上加入他的贡献就可以了。不会出现数值比
- 绿色部分
我们可以维护一个大根堆,按照
去除影响包含两个部分,一个是需要在线段树上删除对左端点的贡献;另一个是记得从堆中删除。由于每一个元素只会进入堆一次,出去一次,所以时间复杂度是有保障的。
最后,在加入红色部分的元素的时候也需要记得加入堆中。
现在我们知道了
总体时间复杂度
本题还是比较抽象,具体需要结合代码理解:
#include<bits/stdc++.h>
using namespace std;
inline int read(){
int x=0,f=1;
char ch=getchar();
while(ch<'0'||ch>'9'){
if(ch=='-') f=-f;
ch=getchar();
}
while(ch>='0'&&ch<='9'){
x=x*10+ch-'0';
ch=getchar();
}
return x*f;
}
const int MAXN=2e6+10;
int n,a[MAXN];
int mx[MAXN],mn[MAXN],tmp[MAXN];
int t[MAXN<<2],tag[MAXN<<2];
inline void pushup(int i){
t[i]=max(t[i<<1],t[i<<1|1]);
}
inline void pushdown(int i){
t[i<<1]+=tag[i],t[i<<1|1]+=tag[i];
tag[i<<1]+=tag[i],tag[i<<1|1]+=tag[i];
tag[i]=0;
}
inline int query(int i,int l,int r,int L,int R){
if(L<=l&&r<=R) return t[i];
if(l>R||r<L) return 0;
int mid=(l+r)>>1;
pushdown(i);
int ans=max(query(i<<1,l,mid,L,R),query(i<<1|1,mid+1,r,L,R));
pushup(i);
return ans;
}
inline void update(int i,int l,int r,int L,int R,int w){
if(L<=l&&r<=R){
t[i]+=w,tag[i]+=w;
return ;
}
if(l>R||r<L) return ;
int mid=(l+r)>>1;
pushdown(i);
update(i<<1,l,mid,L,R,w);
update(i<<1|1,mid+1,r,L,R,w);
pushup(i);
}
int s[MAXN],top,suc[MAXN];
int temp[MAXN],cnt;
struct cmp{
bool operator()(const int &a,const int &b){
return a<b;
}
};
priority_queue<int,vector<int>,cmp> S;
signed main(){
freopen("2457.in","r",stdin);
freopen("2457.out","w",stdout);
n=read();
for(int i=1;i<=n;i++) a[i]=read(),tmp[a[i]]=i;
for(int i=1;i<=n;i++) mx[i]=max(mx[i-1],a[i]);
mn[n+1]=n+1;
for(int i=n;i;i--) mn[i]=min(mn[i+1],a[i]);
for(int i=1;i<=n;i++){
int l=tmp[i],r=n;
while(l<r){
int mid=(l+r)/2+1;
if(mn[mid]<i) l=mid;
else r=mid-1;
}
suc[i]=l;
}
for(int i=1;i<=n;i++)
if(mx[i-1]<a[i]) s[++top]=i;
for(int i=n;i>=s[top];i--){
update(1,1,n,tmp[a[i]],suc[a[i]],1);
S.push(a[i]);
}
int ans=0;
for(int i=top;i;i--){
int pos=s[i];
while(!S.empty()){
int it=S.top();
if(it>=a[pos]){
update(1,1,n,tmp[it],suc[it],-1);
S.pop();
}
else break;
}
ans=max(ans,query(1,1,n,pos,suc[a[pos]])*2-1);
for(int j=s[i];j>=s[i-1];j--){
update(1,1,n,j,suc[a[j]],1);
S.push(a[j]);
}
}
cout<<ans;
return 0;
}
这道题目让我大大的震撼,与
不得不承认这的确是一道十分优秀的好题
题目描述
现在有一个长度为
思路点拨
我们发现,对于
但是最后我们有两种情况:
没错,此时后面两个元素刚好是有序的,这样子我们就不需要处理了。
但是毒瘤的是最后两个元素不一定是有序的:
这样看起来没有什么头绪,但是是有解的,我们考虑一个更加简单的情况
现在就可以处理出来了。这样操作的前提是存在两个相同切相邻的元素,如果
我们可以移动
接下来按照类似于
最后我们有将
就完成了排序。
还是比较抽象,给出一份代码:
#include<bits/stdc++.h>
#define int long long
using namespace std;
inline int read(){
int x=0,f=1;
char ch=getchar();
while(ch<'0'||ch>'9'){
if(ch=='-') f=-f;
ch=getchar();
}
while(ch>='0'&&ch<='9'){
x=x*10+ch-'0';
ch=getchar();
}
return x*f;
}
const int MAXN=1e3+10,inf=1e10;
int n,a[MAXN];
int s[MAXN*MAXN],top;
void tran(int i,int j,int k){
int x=a[i],y=a[j],z=a[k];
a[i]=y,a[j]=z,a[k]=x;
}
void solve(int pos){
int now=n-1;
while(now-1>pos)
s[++top]=--now;
s[++top]=now-1,s[++top]=now-2;
s[++top]=now-2,s[++top]=now-1;
s[++top]=now-1,s[++top]=now-2;
for(int i=now;i<n-1;i++)
s[++top]=i,s[++top]=i;
}
signed main(){
freopen("2458.in","r",stdin);
freopen("2458.out","w",stdout);
srand(time(0));
n=read();
for(int i=1;i<=n;i++)
a[i]=read();
for(int i=1;i<=n-2;i++){
int mn=inf,pos;
for(int j=i;j<=n;j++)
if(a[j]<mn)
mn=a[j],pos=j;
while(pos>i){
if(pos==i+1) tran(pos-1,pos,pos+1),s[++top]=pos-1;
else tran(pos-2,pos-1,pos),s[++top]=pos-2;
pos--;
}
}
bool flag=0;
for(int i=1;i<=3;i++){
if(a[n-2]<=a[n-1]&&a[n-1]<=a[n]){
flag=1;
break;
}
s[++top]=n-2;
tran(n-2,n-1,n);
}
if(!flag){
for(int i=1;i<=n;i++)
if(a[i]==a[i+1]){
solve(i+1);
flag=1;
break;
}
}
if(!flag) cout<<-1;
else{
cout<<top<<endl;
for(int i=1;i<=top;i++)
cout<<s[i]<<" ";
}
return 0;
}
题目简述
给定一个长度为
我们定义一个排列
求全部排列的价值和。
思路点拨
我们令
-
-
对于
-
对于
对于第
现在我们定义状态
答案就是
转移的时候分两类讨论,对于一个集合,当
for(int i=1;i<(1<<n);i++){
if(sum[i]<0){
for(int j=0;j<n;j++)
if(i&(1<<j))
f[i]=(f[i]+f[i^(1<<j)])%mod;
}
else{
for(int j=0;j<n;j++)
if(i&(1<<j))
g[i]=(g[i]+g[i^(1<<j)])%mod;
}
}
时间复杂度
题目描述
现在给出
对于
对于
思路点拨
如果我们元素
我们定义状态
为什么会是
至于阶乘,因为


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 周边上新:园子的第一款马克杯温暖上架
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!