
浅谈后缀数组
前置知识 : 后缀(???),基数排序(说通俗一点就是桶子排序),基础倍增。
后缀数组是一种处理字符串问题的利器,可以起到代替后缀树的作用,在码量上具有绝对的优势。正常情况下,大家都会使用后缀数组而非后缀树。虽然后缀数组十分的好写,但是过程难以令人理解。今天我会使用尽量通俗的语言帮助大家理解什么是后缀数组,以及相关的拓展。
在开始之前
我们需要对于一些变量进行定义(别的数字在后边讲到):
那么这两个数组是具有性质:
后缀排序
现在进行了定义,该如何求出这个后缀数组呢?我们讲如下两种方法(最最最最牛逼但是常数和码量极大的
字符串哈希算法
这个算法的时间复杂度是
相比大家知道怎么编写
最简单的做法就是暴力的枚举,但是注意到
最终的时间复杂度就是
倍增算法
字符串哈希的算法并没有那么重要,就是一个优化的好的暴力,这个倍增的做法才是我们的重头戏,他的码量很小,并且实用性是最为广泛的。缺点还是有的,不是很好理解,所以请读者跟紧我的步伐一步步来。
第一步
我们先按照单个字符进行排序,这一部分可以使用单关键字基数排序。同时,我们可以预处理最初的
代码:
for(int i=1;i<=n;i++){
x[i]=s[i];
++temp[x[i]];
}
for(int i=1;i<=S;i++) temp[i]+=temp[i-1];
for(int i=n;i>=1;i--) sa[temp[x[i]]--]=i;
//这里x表示后缀i的排名,但是目前只考虑了每一个下标后第一个字符
//sa就是后缀数组,表示排名为i的后缀是多少
//temp就是一个用来排序的桶子。S表示字符集大小
第二步
我们考虑如果是要将以下标
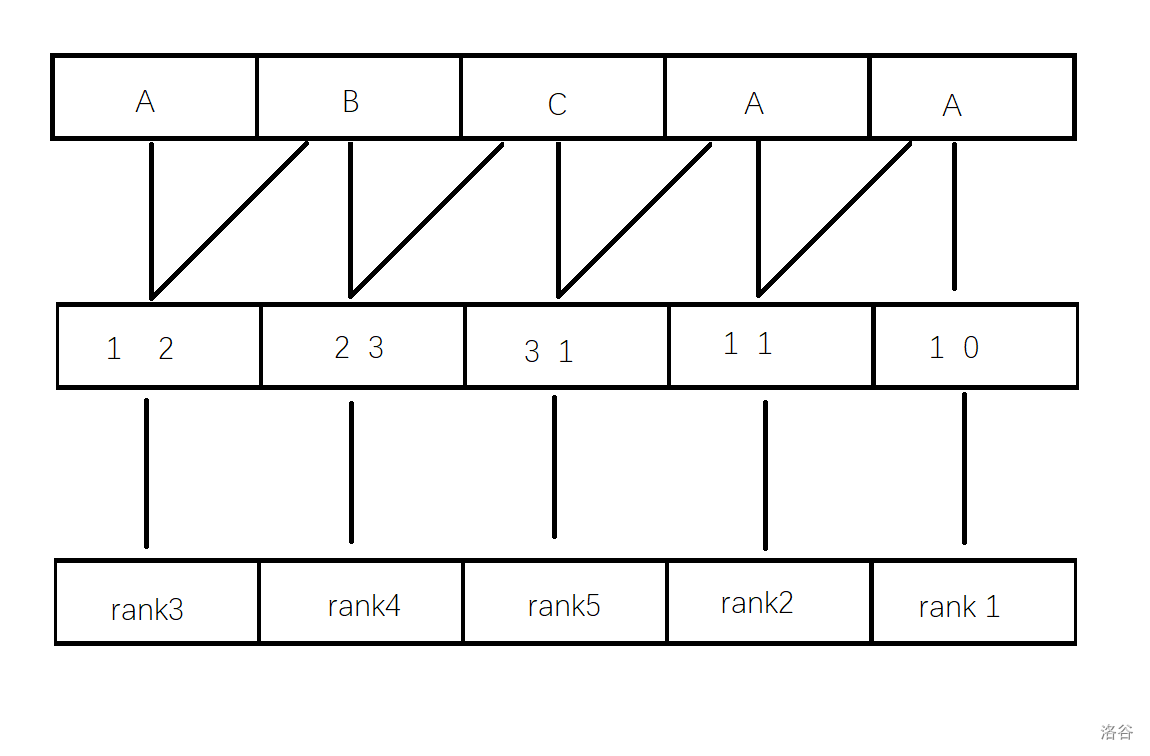
我们在第一步预处理的时候处理出了排名为
双关键字基数排序
单关键字的基数排序十分的简单,而双关键字基数排序的本质就是在单关键字排序的基础上,满足第二关键字有序。
我们可以先按照第二关键字进行第一遍基数排序,再按照第一关键字进行第二遍基数排序。为什么这个会是对的呢?因为基数排序是稳定的,我们在进行第一次基数排序之后,第二关键字有序,那么我们按照第一关键字排序之后,那些第一关键字相同的元素就会按照第二关键字顺序排好。可能比较抽象的解释吧。
那么我们知道了求解
我们可以将一个长度为
那么倍增的次数就是
这就是倍增法的主要思想,理解了思想,就到了最为毒瘤的代码了。
第三步
现在就是实现代码的时间了,我们按照一部分一部分解析代码以及一些常数优化。
假设目前我们倍增到了长度为
首先是预处理,之前讲过了(第一步):
for(int i=1;i<=n;i++){
x[i]=s[i];
++temp[x[i]];
}
for(int i=1;i<=S;i++) temp[i]+=temp[i-1];
for(int i=n;i>=1;i--) sa[temp[x[i]]--]=i;
//这里x表示后缀i的排名,但是目前只考虑了每一个下标后第一个字符
//sa就是后缀数组,表示排名为i的后缀是多少
后文,
int pos=0;
for(int i=n-k+1;i<=n;i++) y[++pos]=i;
//循环到n-k+1的原因就是[n-k+1,n]这些后缀并没有第二关键字,所以排名因该考前
for(int i=1;i<=n;i++)
if(sa[i]>k) y[++pos]=sa[i]-k;
//这一部分在对第二关键字进行排序
//只有 sa[i]>k 才有第一关键字
为什么不需要进行基数排序呢?因为我们知道,第二关键字运用到的
我们进行第二遍基数排序:
for(int i=1;i<=S;i++) temp[i]=0;
for(int i=1;i<=n;i++) temp[x[i]]++;
for(int i=1;i<=S;i++) temp[i]+=temp[i-1];
for(int i=n;i>=1;i--)
sa[temp[x[y[i]]]--]=y[i];
//这一部分函数调用比较复杂,但是可以联想到我们是怎么对s[1]-s[n]是如何基数排序的
//只不过是将i换成了排序完第二关键字的y数组罢了
之后,我们按照原来得
for(int i=1;i<=n;i++) y[i]=0;
swap(x,y);
//更新x数组需要运用到原来的x和原来的sa数组,所以暂时存储在y中
pos=1;
x[sa[1]]=1;
for(int i=2;i<=n;i++){
if(y[sa[i]]==y[sa[i-1]]&&y[sa[i]+k]==y[sa[i-1]+k])
x[sa[i]]=pos;
else x[sa[i]]=++pos;
}
代码还是比较好理解。后面的一部分本质上就是类似于离散化的一个过程。我们的第一,第二关键字都已经排好序了,处理排名就简单了。
我们还可以在最后加上两个优化:
if(pos==n) break;
//以上是一个小优化,就是如果目前所有的后缀都已经分出排名了,我们可以直接跳出
S=pos;
//因为此时x在1-pos这个值域,所以可以缩小值域优化基数排序
总体代码:倍增算法
至此,我们学会了后缀排序。
最长公共前缀(LCP)
谈到后缀数组的运用,一定离不开
我们定义
进而推广:
对于第一个结论,给出如下证明:
我们假设
- 假设
那么
那么
我们定义
有了这个结论,我们就可以在
给出求
for(int i=1;i<=n;i++) rk[sa[i]]=i;
int pos=0;
for(int i=1;i<=n;i++){
if(rk[i]==1) continue;
pos=pos?pos-1:pos;
int j=sa[rk[i]-1];
while(i+pos<=n&&j+pos<=n&&s[i+pos]==s[j+pos]) pos++;
h[rk[i]]=pos;
}
推荐一些题目(我个人可能不是很讲的清楚,难度从低到高):
纯纯板子:
后缀数组
[AHOI2013]差异
[HAOI2016] 找相同字符
并不全是板子:
[SDOI2016] 生成魔咒
[SDOI2008] Sandy 的卡片
[NOI2015] 品酒大会


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 地球OL攻略 —— 某应届生求职总结
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 提示词工程——AI应用必不可少的技术
· .NET周刊【3月第1期 2025-03-02】