
贪心,构造学习笔记
贪心构造不会
黄题绿题懵逼
横批:依托答辩
题目描述
有一些点,每一个点有一个点权
思路点拨
我们连出来的图一定可以被划分为一个二分图。不然就会存在奇环,而不论你怎么构造,奇环上就是会有一条路径不满足条件。
所以我们可以枚举一个值域的划分,假设枚举
但是还存在一种极端的情况,就是划分不出来一个二分图使得左部和右部都非空,也就是说,全部的值都相等。这个时候,我们发扬人类智慧,让最终的图不存在长度为
#include<bits/stdc++.h>
#define int long long
using namespace std;
const int MAXN=2e5+10;
int T,n,a[MAXN];
signed main(){
cin>>T;
while(T--){
cin>>n;
for(int i=1;i<=n;i++) cin>>a[i];
sort(a+1,a+n+1);
int ans=0;
for(int i=1;i<n;i++)
if(a[i]!=a[i+1])
ans=max(ans,i*(n-i));
cout<<max(ans,n/2)<<endl;
}
return 0;
}
题目描述
有一个飞行表演持续
思路点拨
我们考虑对于一种特技假设他出现位置的序列为
我们猜一个结论,我们按照
for(int i=1;i<=k;i++) cin>>a[i];
sort(a+1,a+k+1,cmp);
int ans=0;
for(int l=1,r=n,pos=1;l<r;l++,r--)
ans+=(r-l)*a[pos++];
但是为什么是对的呢?我们考虑使用交换法来证明。假设存在两个下表
因为
题目描述
有一个包含
有
对于连续空位的解释:例如,下图中箭头所指位置左边连续空位为
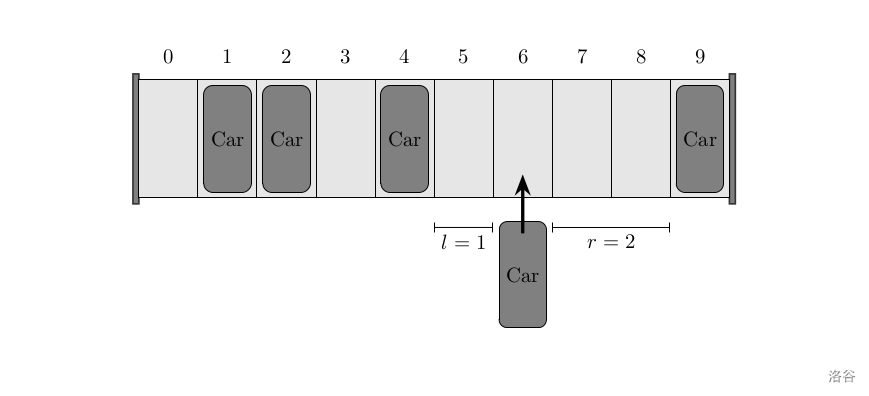
请依次确定每一辆车停入的位置,使得停入所有车所需时间最小。
思路点拨
结论:每一次对于一辆车,如果
正确性的话,每一次,我们可以让当前的车贡献最大,并且还可以让目前的车位连续,为后面的车达到最大贡献提供条件。
所以这是一个巧妙的安排方式,一举两得。
#include<bits/stdc++.h>
#define int long long
using namespace std;
const int MAXN=2e5+10;
int n,w[MAXN],l[MAXN],r[MAXN];
signed main(){
cin>>n;
for(int i=1;i<=n;i++) cin>>w[i];
for(int i=1;i<=n;i++) cin>>l[i];
for(int i=1;i<=n;i++) cin>>r[i];
int ans=0;
for(int i=1;i<=n;i++)
ans+=w[i]-(n-i)*max(l[i],r[i]);
cout<<ans;
return 0;
}
题目描述
给定一个长度为
你可以进行一些修改,每次你可以将一个
但 zbw 认为太过简单,于是他规定,你可以在修改前进行无限次如下操作:交换
求最小的花费。
思路点拨
我们考虑如果
我们考虑如何构造那个序列,我们维护一个集合,每一次我们加入一个数
-
加入到一条链的底部
-
加入到一条链的顶部
-
加入到一条新链
这三种操作我们可以使用并查集维护,因为数组开不下(
最后我们就获得了这个序列。
考虑答案的计算,有两种方式:
第一种
我们将原来的序列
分别从小到大排序,每一次计算答案就是
第二种
我们在在线维护这个并查集的时候,我们的一个元素
接下来考虑加入权值
这样子我们的答案不会变(都是
最终,我们将如上述方法得出的
时间复杂度
代码:
#include<bits/stdc++.h>
#define int long long
using namespace std;
const int MAXN=1e6+10;
inline int read(){
int x=0,f=1;
char ch=getchar();
while(ch<'0'||ch>'9'){
if(ch=='-') f=-f;
ch=getchar();
}
while(ch>='0'&&ch<='9'){
x=x*10+ch-'0';
ch=getchar();
}
return x*f;
}
void print(__int128 x){
if(x<10) putchar(x+'0');
else{
print(x/10);
putchar(x%10+'0');
}
}
int n,a[MAXN],b[MAXN];
int fa[MAXN],temp[MAXN];
int find(int x){
if(fa[x]==x) return x;
return fa[x]=find(fa[x]);
}
map<int,int> vis;
bool cmp(int x,int y){
return x>y;
}
signed main(){
n=read();
for(int i=1;i<=n;i++) a[i]=read();
for(int i=1;i<=n;i++) b[i]=read();
sort(a+1,a+n+1,cmp);
for(int i=1;i<=n;i++){
int w=a[i];
if(!vis[a[i]]){
vis[a[i]]=i;
fa[i]=i;
}
else{
int dad=find(vis[a[i]]);
a[i]=a[dad]+1;
vis[a[i]]=i;
fa[dad]=fa[i]=i;
}
if(vis[a[i]+1]) fa[i]=vis[a[i]+1];
temp[i]=a[i]-w;
}
sort(b+1,b+n+1);
sort(temp+1,temp+n+1,cmp);
__int128 ans=0;
for(int i=1;i<=n;i++)
ans=ans+temp[i]*b[i];
__int128 mod=1;
for(int i=1;i<=64;i++) mod=mod*2;
print(ans%mod);
return 0;
}
题目描述
有一台计算器,使用

由于奇怪的特性,如果两个变量在相加时得到的结果在
为了防止这样的事情发生,一个变通的方法是更改
不过,可能不存在一种方案,使得计算出这
对于全部数据,保证
思路点拨
我们发现,数据保证
当我们的和大于
我们希望找到最多的数满足他们的和在
我们可以按照我们之前的构造方案,我们会选正数从小到大排序的前缀和,我们会选负数从大到小排序的后缀和,因为数据比较小,我们可以直接枚举。
#include<bits/stdc++.h>
#define int long long
using namespace std;
const int MAXN=1e3+10;
int N,k;
int n,a[MAXN],m,b[MAXN];
bool cmp(int x,int y){
return x>y;
}
signed main(){
cin>>N>>k;
for(int i=1,w;i<=N;i++){
cin>>w;
if(w<0) b[++m]=w;
else a[++n]=w;
}
sort(a+1,a+n+1);
sort(b+1,b+m+1,cmp);
for(int i=1;i<=n;i++) a[i]+=a[i-1];
for(int i=1;i<=m;i++) b[i]+=b[i-1];
int ans=0;
for(int i=0;i<=n;i++)
for(int j=0;j<=m;j++)
if(a[i]+b[j]<pow(2,k-1)&&a[i]+b[j]>=-pow(2,k-1))
ans=max(ans,i+j);
cout<<ans;
return 0;
}
题目描述
哆来咪·苏伊特参加了
如果哆来咪选择在第
- 如果
- 否则,什么都不会改变。
如果她选择不参加比赛,一切都不会改变。哆来咪想参加尽可能多的比赛。请给哆来咪一个解决方案。
思路点拨
我们考虑操作的逆操作,就是我初始的
显然,我们倒叙的话肯定是能选就选呗。当我们的
#include<bits/stdc++.h>
#define int long long
using namespace std;
inline int read(){
int x=0,f=1;
char ch=getchar();
while(ch<'0'||ch>'9'){
if(ch=='-') f=-f;
ch=getchar();
}
while(ch>='0'&&ch<='9'){
x=x*10+ch-'0';
ch=getchar();
}
return x*f;
}
const int MAXN=1e5+10;
int T,n,q,a[MAXN];
bool vis[MAXN];
signed main(){
T=read();
while(T--){
n=read(),q=read();
for(int i=1;i<=n;i++) a[i]=read();
int cnt=0,pos=0;
memset(vis,0,sizeof(vis));
for(int i=n;i;i--){
if(a[i]>cnt) cnt++;
if(cnt==q){
pos=i;
break;
}
}
for(int i=1;i<pos;i++)
if(a[i]<=q) vis[i]=1;
for(int i=pos;i<=n;i++)
vis[i]=1;
for(int i=1;i<=n;i++) cout<<vis[i];
cout<<endl;
}
return 0;
}
题目描述
定义长度为
思路点拨
我们可以简化问题,由于对于
-
对于
-
对于
为什么拆分成两个子问题还是可以满足操作次数最小呢?因为对于
那么我们就分别讲解两个子问题的解法。但是因为两个子问题是镜像的,学会一个就会另一个,这里拿子问题
我们考虑什么时候
也就是说,对于每一个
#include<bits/stdc++.h>
#define int long long
using namespace std;
inline int read(){
int x=0,f=1;
char ch=getchar();
while(ch<'0'||ch>'9'){
if(ch=='-') f=-f;
ch=getchar();
}
while(ch>='0'&&ch<='9'){
x=x*10+ch-'0';
ch=getchar();
}
return x*f;
}
const int MAXN=1e6+10;
int T,n,m,a[MAXN];
struct cmp1{
bool operator()(int a,int b){
return a<b;
}
};
struct cmp2{
bool operator()(int a,int b){
return a>b;
}
};
priority_queue<int,vector<int>,cmp1> q1;
priority_queue<int,vector<int>,cmp2> q2;
signed main(){
T=read();
while(T--){
n=read(),m=read();
for(int i=1;i<=n;i++)
a[i]=read();
if(n==1){
cout<<0<<endl;
continue;
}
int ans=0;
while(!q1.empty()) q1.pop();
while(!q2.empty()) q2.pop();
int cnt=0;
for(int i=m;i>1;i--){
cnt+=a[i];
q1.push(a[i]);
if(cnt>0){
cnt-=q1.top()*2;
q1.pop();
ans++;
}
}
cnt=0;
for(int i=m+1;i<=n;i++){
cnt+=a[i];
q2.push(a[i]);
if(cnt<0){
cnt-=q2.top()*2;
q2.pop();
ans++;
}
}
cout<<ans<<endl;
}
return 0;
}
题目描述
小 C 是一个算法竞赛爱好者,有一天小 C 遇到了一个非常难的问题:求一个序列的最大子段和。
但是小 C 并不会做这个题,于是小 C 决定把序列随机打乱,然后取序列的最大前缀和作为答案。
小 C 是一个非常有自知之明的人,他知道自己的算法完全不对,所以并不关心正确率,他只关心求出的解的期望值,现在请你帮他解决这个问题,由于答案可能非常复杂,所以你只需要输出答案乘上
注:最大前缀和的定义:
对于
思路点拨
我也不知道为什么
我们考虑状态压缩动态规划,一般的状态不好转移,因为转移需要利用到最大值。但是,我们发现这样的最大值只有
-
-
-
-
转移的话,
最终统计答案即可。本题的难点在于将一个数放进序列的首部转移并没有那般好像,并且
#include<bits/stdc++.h>
#define int long long
using namespace std;
inline int read(){
int x=0,f=1;
char ch=getchar();
while(ch<'0'||ch>'9'){
if(ch=='-') f=-f;
ch=getchar();
}
while(ch>='0'&&ch<='9'){
x=x*10+ch-'0';
ch=getchar();
}
return x*f;
}
const int MAXN=20,mod=998244353;
int n,a[MAXN];
int sum[1<<20],f[1<<20],g[1<<20]={1};
signed main(){
n=read();
for(int i=0;i<n;i++) a[i]=read();
for(int i=1;i<(1<<n);i++)
for(int j=0;j<n;j++)
if(i&(1ll<<j)) sum[i]+=a[j];
for(int i=0;i<n;i++) f[1<<i]=1;
for(int i=1;i<(1<<n);i++){
if(sum[i]>=0){
for(int j=0;j<n;j++)
if(!(i&(1ll<<j)))
f[i|(1ll<<j)]=(f[i]+f[i|(1ll<<j)])%mod;
}
else{
for(int j=0;j<n;j++)
if(i&(1ll<<j)) g[i]=(g[i]+g[i^(1ll<<j)])%mod;
}
}
int ans=0,all=(1<<n)-1;
for(int i=1;i<(1<<n);i++)
ans=(ans+f[i]*g[all^i]%mod*(sum[i]+mod))%mod;
cout<<ans;
return 0;
}


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现
· 25岁的心里话