
成都集训游记
换个地方被吊打
Day1
今天主要是考试和讲题,但是今天我生病了头痛欲裂,所以没有写什么题,主要是休息吧。晚上吃了一些药,情况稍有改善后改了两道题。
数据结构专题(金天)
Day2
今天上午是自己写题,下午讲解了数据结构。学习的新知识是:
-
ZKW线段树
-
圆方树和点双tarjan
对于一些数据结构的trick有了新的理解。
A - Ice-cream Tycoon
题意:要求维护一个冰激凌集合,支持如下两种操作:
-
加入
-
出售最便宜的
思路点拨:本题比较简单
- 考虑对于全部的询问离线下来后离散化,使用线段树上二分判断是否买得起。十分基础,时间复杂度
B - New Year Tree
给定一棵树,每一个节点有一个颜色。你需要编写一种数据结构,支持如下两种操作:
-
将子树全部的颜色改为
-
询问字数内的颜色有多少种。
数据保证所有颜色的数量不超过
思路点拨:本题比较简单
-
考虑通过 dfs序 将树上问题转化为序列上问题。
-
我们使用一个线段树维护区间上的颜色。对于一个区间的颜色表示,我们使用一个二进制压缩的数表示即可。pushup函数就两个儿子的颜色并。
-
子树颜色赋值就是区间赋值操作,维护一个懒标记。
时间复杂度
C - Ping-Pong
你需要维护一个区间集合,支持如下两种操作:
-
添加一个区间[l,r] ,保证这个区间的长度严格大于之前的全部区间
-
查询第
思路点拨:本题十分困难
-
我们考虑对于第
-
我们考虑维护一种数据结构,通过并查集的方式让每一个区间指向它可以到达的极大区间。我们维护这些极大区间。那么每一次加入一个区间的时候,我们可以将跟这个区间有交的极大区间给合并起来,形成一个新的极大区间。问题是,我们怎么找到有交的区间呢?
-
我们考虑对于每一个线段树的节点维护一个set,那么每一次添加一个区间,我们就将在线段树上被这个区间完全包含的
-
我们考虑计算时间复杂度,每一次我们打上
D - Life as a Monster
题意:平面上有
-
更改一个点的坐标
-
查询某一个点到其余点的切比雪夫距离之和
强制在线,空间比较紧张。
思路点拨:本题难度适中
-
切比雪夫距离转曼哈顿距离。
-
我们考虑一个点距离其余点的曼哈顿距离可以转化为
主要是切比雪夫距离转曼哈顿距离的trick需要知道。
E - Tourists
题意:给定了一个无向图,点有点权。你需要编写一个程序支持如下两种操作:
-
更改一个点的点权
-
查询在
思路点拨:本题难度适中
-
考虑一个联通块什么时候可以在不经过重复点的情况下到达任意点,这是一个点双。
-
我们考虑建立一个圆方树,方点维护这个点双的最小点权。但是每一次更改可能牵扯到多个方点,所以我们钦定一个根,并且让一个方点只管辖它的儿子节点的最小权值,这样的时间是正确的。
-
每一次查询,我们在圆方树上树剖求链上最小值,如果LCA是一个方点,答案就考虑这个方点的父亲节点的点权。
F - New Year and Conference
题意:现在有两个会场,每一个演出会在
思路点拨:本题比较简单。
-
其实 S 的大小我们只要考虑
-
我们考虑枚举重叠的区间的时间靠后的一个区间,双指针扫出哪些与这个区间的另一会场没有时间交集的那些区间,接下来考虑在这些区间中是否存在区间与本区间有交集。这样我们维护一个线段树判断是否有交集就可以了。
Day3
A Roadside Trees(*3000)
题目描述
-
路边有
-
在
-
砍掉从左往右第
-
保证任意时刻不存在两颗高度相同的树。
- 每一次操作后查询最长上升子序列。
思路点拨
我们发现树会长高,十分烦躁。当我们种下一棵树的时候,我们将树的初始高度减去目前的时间
我们考虑到一半的最长上升子序列的转移柿子,对于一个元素
又因为树的高度两两不同,所以对于插入的一颗高度小于等于
时间复杂度
B Noble Knight's Path(*3000)
-
给一棵树,现在有两种询问:
-
标记某个节点
-
找到路径
思路点拨
对于在
特别的,在路径的
时间复杂度
C 区间本质不同子串个数
D Cyclic Distance
太逆天,待补。
E HUD 7144 Treasure
-
给定一张边带权的无向图,每个点有一个颜色和一个权值。保证对于一种颜色,拥有这个颜色的点数不超过 10。现在要求支持以下两种操作
-
增加一个点的权值。
-
询问从一个点出发,不经过边权超过 x 的边,其所有可能到达的点中,每个颜色的最大权值之和。
思路点拨
对于边权限定这一块,考虑使用
那么对于一个节点,我们需要增加权值的话,我们只需要找到从它开始,可以在哪一段路径上成为最大值。这个可以路径修改操作,使用树剖。查询自然不在话下。
时间复杂度
考虑到颜色的数量十分的稀少,所以完全可以建虚树,时间复杂度
G-JOI 稻草人/手办
题目描述
二维平面上有
-
-
不存在
思路点拨
-
离散化后即为给定一个排列,要求找出
-
复杂二元组计数考虑进行分治,固定左侧
-
-
不妨按照大小顺序,从大到小加入
-
通过单调栈维护可能的
-
复杂度
String 专题(冯施源)
[NOI2014]动物园
题目描述
我们给定一个字符串
思路点拨
我们考虑一个暴力,我们可以使用
- 倍增
因为全部的
- 基于树上倍增的进一步优化
实际上,在一般的树上上述的倍增方法已经是足够优秀了,但是这个
#include<bits/stdc++.h>
#define int long long
using namespace std;
inline int read(){
int x=0,f=1;
char ch=getchar();
while(ch<'0'||ch>'9'){
if(ch=='-') f=-f;
ch=getchar();
}
while(ch>='0'&&ch<='9'){
x=x*10+ch-'0';
ch=getchar();
}
return x*f;
}
const int MAXN=1e6+10,mod=1e9+7;
int T,n,p[MAXN],f[MAXN];
string s;
signed main(){
T=read();
while(T--){
cin>>s;n=s.length();
memset(p,0,sizeof(p));
memset(f,0,sizeof(f));
for(int i=1;i<n;i++){
int j=p[i];
while(j&&s[i]!=s[j]) j=p[j];
j+=(s[i]==s[j]);
p[i+1]=j;
}
for(int i=1;i<=n;i++)
f[i]=f[p[i]]+1;
int ans=1,j=0;
for(int i=1;i<n;i++){
while(j&&s[i]!=s[j]) j=p[j];
j+=(s[i]==s[j]);
while(j>(i+1)/2) j=p[j];
ans=ans*(f[j]+1)%mod;
}
cout<<ans<<endl;
}
return 0;
}
BZOJ 1461 (Luogu Cow Patterns G)
题目描述
我们有两个字符串,一个是文本串,另一个是模式串。我们认为两个文本串相等当且仅当两个字符串离散化之后相等。希望直到模式串在文本串中出现的位置。
思路点拨
考虑
具体的正确性证明也十分简单,因为我们的前驱后继是在模式串的基础上定义的而不是在文本串上定义的,所以匹配的时候不会有问题。
#include<bits/stdc++.h>
#define int long long
using namespace std;
inline int read(){
int x=0,f=1;
char ch=getchar();
while(ch<'0'||ch>'9'){
if(ch=='-') f=-f;
ch=getchar();
}
while(ch>='0'&&ch<='9'){
x=x*10+ch-'0';
ch=getchar();
}
return x*f;
}
const int MAXN=1e6+10,mod=1e9+7;
int n,k,S,a[MAXN];
int b[MAXN],pre[MAXN],suc[MAXN];
struct node{
int pos,val;
bool friend operator<(const node &A,const node &B){
if(A.val==B.val) return A.pos<B.pos;
return A.val<B.val;
}
};
set<node> s;
set<node>::iterator it;
bool equal_ofa(int x,int y){//比较 a[x] 和 b[y]
if(pre[y]){
if(b[pre[y]]<b[y]&&a[x-(y-pre[y])]>=a[x]) return 0;
if(b[pre[y]]==b[y]&&a[x-(y-pre[y])]!=a[x]) return 0;
}
if(suc[y]){
if(b[suc[y]]==b[y]&&a[x+(suc[y]-y)]!=a[x]) return 0;
if(b[suc[y]]>b[y]&&a[x+(suc[y]-y)]<=a[x]) return 0;
}
return 1;
}
bool equal_ofb(int x,int y){//比较 b[x]和 b[y]
if(pre[y]){
if(b[pre[y]]<b[y]&&b[x-(y-pre[y])]>=b[x]) return 0;
if(b[pre[y]]==b[y]&&b[x-(y-pre[y])]!=b[x]) return 0;
}
if(suc[y]){
if(b[suc[y]]==b[y]&&b[x+(suc[y]-y)]!=b[x]) return 0;
if(b[suc[y]]>b[y]&&b[x+(suc[y]-y)]<=b[x]) return 0;
}
return 1;
}
int fail[MAXN];
int id[MAXN],cnt;
signed main(){
n=read(),k=read(),S=read();
for(int i=1;i<=n;i++) a[i]=read();
for(int i=1;i<=k;i++){
b[i]=read();
s.insert((node){i,b[i]});
it=s.lower_bound((node){i,b[i]});
it++;
if(b[(*it).pos]>=b[i]&&(*it).pos<i) suc[i]=(*it).pos;
--it;--it;
if(b[(*it).pos]<=b[i]&&(*it).pos<i) pre[i]=(*it).pos;
}
for(int i=2;i<=k;i++){
int j=fail[i-1];
while(j&&!equal_ofb(i,j+1)) j=fail[j];
j+=equal_ofb(i,j+1);
fail[i]=j;
}
for(int i=1,j=0;i<=n;i++){
while(j&&!equal_ofa(i,j+1)) j=fail[j];
j+=equal_ofa(i,j+1);
if(j==k){
++cnt;
id[cnt]=i-k+1;
j=fail[j];
}
}
cout<<cnt<<endl;
for(int i=1;i<=cnt;i++) cout<<id[i]<<endl;
return 0;
}
[POI2005] SZA-Template
题目描述
你打算在纸上印一串字母。
为了完成这项工作,你决定刻一个印章。印章每使用一次,就会将印章上的所有字母印到纸上。
同一个位置的相同字符可以印多次。例如:用 aba 这个印章可以完成印制 ababa 的工作(中间的 a 被印了两次)。但是,因为印上去的东西不能被抹掉,在同一位置上印不同字符是不允许的。例如:用 aba 这个印章不可以完成印制 abcba 的工作。
因为刻印章是一个不太容易的工作,你希望印章的字符串长度尽可能小。
思路点拨
本题具体有两种做法,失配树和动态规划。这里讲述更好理解的失配树做法,想要了解动态规划做法可以看 这里 。
我们考虑建出失配树,然后寻找一些性质。对于一个印章,我们肯定需要在
我们接着想,一个答案什么时候合法?对于一个失配树上的节点
如果我们从
#include<bits/stdc++.h>
#define int long long
using namespace std;
inline int read(){
int x=0,f=1;
char ch=getchar();
while(ch<'0'||ch>'9'){
if(ch=='-') f=-f;
ch=getchar();
}
while(ch>='0'&&ch<='9'){
x=x*10+ch-'0';
ch=getchar();
}
return x*f;
}
const int MAXN=5e5+10,mod=1e9+7;
int n,fail[MAXN];
string s;
int temp[MAXN],top;
int pre[MAXN],suc[MAXN];//双向链表
int mx=1;//最大的邻值之差
vector<int> e[MAXN];//失配树
void erase(int x){
if(x<1||x>n) return ;
mx=max(mx,suc[x]-pre[x]);
suc[pre[x]]=suc[x];
pre[suc[x]]=pre[x];
}
void bfs(int f,int v){
queue<int> q;
q.push(f);
while(!q.empty()){
int x=q.front();
q.pop();
if(x==v) continue;
erase(x);
for(int i=0;i<e[x].size();i++){
int to=e[x][i];
q.push(to);
}
}
}
signed main(){
cin>>s;n=s.length();
s='0'+s;
for(int i=2,j=0;i<=n;i++){
while(j&&s[i]!=s[j+1]) j=fail[j];
j+=(s[i]==s[j+1]);
fail[i]=j;
}//KMP
for(int i=n;i;i=fail[i]) temp[++top]=i;//此时temp中失是降序的
for(int i=1;i<=n;i++){
pre[i]=i-1,suc[i]=i+1;
e[fail[i]].push_back(i);
}//树根为0
for(int i=top;i;i--){
bfs(temp[i+1],temp[i]);
if(mx<=temp[i]){
cout<<temp[i];
return 0;
}
}
cout<<n;
return 0;
}
[BZOJ 2601] Country
题目描述
有
我们保证这些字符串的定义是无环的。现在给定了一个小写字母组成的模式串,问其在某个字符串变量中出现的次数。字符串变量的长度和模式串长度 单个 不超过
思路点拨
当一个字符串变量只有小写字母时,我们只需要做
那么两个
定义状态
定义状态
状态转移是十分显然的。当我们在字符串变量扫到的字母是大写时,递归求解。反之我们直接
#include<bits/stdc++.h>
#define int long long
using namespace std;
inline int read(){
int x=0,f=1;
char ch=getchar();
while(ch<'0'||ch>'9'){
if(ch=='-') f=-f;
ch=getchar();
}
while(ch>='0'&&ch<='9'){
x=x*10+ch-'0';
ch=getchar();
}
return x*f;
}
const int MAXN=1e2+10,S=30;
const int mod=10000;
int n,len[S],fail[MAXN],m;
char s[MAXN];//s1是文本串,s2是待匹配串
char c[S][MAXN],txt[MAXN];
void init(){
scanf("%s",s+1);
m=strlen(s+1);
for(int i=2;i<=m;i++){
int j=fail[i-1];
while(j&&s[i]!=s[j+1]) j=fail[j];
j+=(s[i]==s[j+1]);
fail[i]=j;
}
}
int f[S][MAXN],pos[S][MAXN];
//f[i][j]表示在字符串 i 开始的 j 位匹配模式串的结果
//nxt[i][j]表示在字符串 i 开始的 j 位匹配模式串后的fail指针
void dp(int i,int j){
if(f[i][j]!=-1) return ;
f[i][j]=0;
int id=j;
for(int k=1;k<=len[i];k++){
if('A'<=c[i][k]&&c[i][k]<='Z'){//遇到大写字母,递归求解
dp(c[i][k]-'A',id);
f[i][j]=(f[i][j]+f[c[i][k]-'A'][id])%mod;
id=pos[c[i][k]-'A'][id];
}
else{
while(id&&c[i][k]!=s[id+1])
id=fail[id];
id+=(c[i][k]==s[id+1]);
if(id==m){
f[i][j]=(f[i][j]+1)%mod;
id=fail[id];
}
}
}
pos[i][j]=id;
}
signed main(){
scanf("%lld",&n);
scanf("%s",txt);
for(int i=0;i<n;i++){
scanf("%s",c[i]);
len[i]=strlen(c[i]);
for(int j=2;j<len[i];j++)
c[i][j-1]=c[i][j];
len[i]-=2;
}
init();//预处理fail指针
memset(f,-1,sizeof(f));
dp(txt[0]-'A',0);
cout<<f[txt[0]-'A'][0];
return 0;
}
[NOIP2020] 字符串匹配
题意描述
对于一个字符串
更具体地,我们可以定义
并递归地定义
则小 C 的习题是求
思路点拨
可以发现
时间复杂度
#include<bits/stdc++.h>
#define int unsigned long long
using namespace std;
inline int read(){
int x=0,f=1;
char ch=getchar();
while(ch<'0'||ch>'9'){
if(ch=='-') f=-f;
ch=getchar();
}
while(ch>='0'&&ch<='9'){
x=x*10+ch-'0';
ch=getchar();
}
return x*f;
}
const int base=123;
const int MAXN=2e6+10,N=2e6;
int T,n,pw[MAXN]={1},h[MAXN];
char c[MAXN];
int hsh(int l,int r){
int len=r-l+1;
return h[r]-h[l-1]*pw[len];
}
int cnt[30],pre[MAXN],suc[MAXN];
void init(){
memset(cnt,0,sizeof(cnt));
int sum=0;
for(int i=1;i<=n;i++){
if(cnt[c[i]-'a']&1) sum--;
else sum++;
cnt[c[i]-'a']++;
pre[i]=sum;
}
sum=0;
memset(cnt,0,sizeof(cnt));
for(int i=n;i;i--){
if(cnt[c[i]-'a']&1) sum--;
else sum++;
cnt[c[i]-'a']++;
suc[i]=sum;
}
}
int t[30],ans;
int lowbit(int x){
return x&(-x);
}
void add(int x,int y){
for(int i=x+1;i<=27;i+=lowbit(i))
t[i]+=y;
}
int query(int x){
int sum=0;
for(int i=x+1;i;i-=lowbit(i))
sum+=t[i];
return sum;
}
signed main(){
T=read();
for(int i=1;i<=N;i++) pw[i]=pw[i-1]*base;
while(T--){
scanf("%s",c+1);
n=strlen(c+1);
for(int i=1;i<=n;i++)
h[i]=h[i-1]*base+c[i];
init();
memset(t,0,sizeof(t));
ans=0;
for(int len=1;len<=n;len++){
if(len-1) add(pre[len-1],1);
for(int i=1;i+len-1<=n;i+=len){
if(hsh(i,i+len-1)!=h[len]) break;
if(i+len-1<n) ans+=query(suc[i+len]);
}
}
cout<<ans<<endl;
}
return 0;
}
[NOI2011] 阿狸的打字机
题目描述
阿狸喜欢收藏各种稀奇古怪的东西,最近他淘到一台老式的打字机。打字机上只有 B、P 两个字母。经阿狸研究发现,这个打字机是这样工作的:
- 输入小写字母,打字机的一个凹槽中会加入这个字母(这个字母加在凹槽的最后)。
- 按一下印有
B的按键,打字机凹槽中最后一个字母会消失。 - 按一下印有
P的按键,打字机会在纸上打印出凹槽中现有的所有字母并换行,但凹槽中的字母不会消失。
例如,阿狸输入 aPaPBbP,纸上被打印的字符如下:
a
aa
ab
我们把纸上打印出来的字符串从
思路点拨
多模式串,多文本串的字符串匹配问题,考虑
在线做是比较难的,考虑将询问离线下来。对于一组询问
代买实现比较简单,总体时间复杂度是
#include<bits/stdc++.h>
using namespace std;
inline int read(){
int x=0,f=1;
char ch=getchar();
while(ch<'0'||ch>'9'){
if(ch=='-') f=-f;
ch=getchar();
}
while(ch>='0'&&ch<='9'){
x=x*10+ch-'0';
ch=getchar();
}
return x*f;
}
const int MAXN=1e5+10;
string s;
int n;
int pos[MAXN],trie[MAXN][26],tot;
vector<int> G[MAXN];//字典树
struct node{
int fail,sum,dad;
}t[MAXN];
struct problem{
int u,v,id;//u在v中出现了多少次
//id是问题编号
};
int ans[MAXN];
vector<problem> pb[MAXN];//存储的问题
vector<int> e[MAXN];//fail树
void init(){
int rot=0,cnt=0;
for(int i=0;i<s.length();i++){
if('a'<=s[i]&&s[i]<='z'){
char c=s[i]-'a';
if(!trie[rot][c]){
trie[rot][c]=++tot;
G[rot].push_back(tot);
}
t[trie[rot][c]].dad=rot;
rot=trie[rot][c];
}
else if(s[i]=='P'){
t[rot].sum++;
pos[++cnt]=rot;
}
else rot=t[rot].dad;
}
}
queue<int> q;
void build(){
for(int i=0;i<26;i++)
if(trie[0][i])
q.push(trie[0][i]);
while(!q.empty()){
int u=q.front();
q.pop();
for(int i=0;i<26;i++){
int v=trie[u][i];
if(v){
t[v].fail=trie[t[u].fail][i];
q.push(v);
}
else trie[u][i]=trie[t[u].fail][i];
}
}
for(int i=1;i<=tot;i++)
e[t[i].fail].push_back(i);
}
int res,dfn[MAXN],siz[MAXN];
void dfs1(int x){
dfn[x]=++res;
siz[x]=1;
for(int i=0;i<e[x].size();i++){
int to=e[x][i];
dfs1(to);
siz[x]+=siz[to];
}
}
int bit[MAXN];
int lowbit(int x){
return x&(-x);
}
void add(int x,int y){
for(int i=x;i<=res;i+=lowbit(i))
bit[i]+=y;
}
int query(int x){
int cnt=0;
for(int i=x;i;i-=lowbit(i))
cnt+=bit[i];
return cnt;
}
void dfs2(int x){
add(dfn[x],1);
for(int i=0;i<pb[x].size();i++){
int v=pos[pb[x][i].u];
ans[pb[x][i].id]=query(dfn[v]+siz[v]-1)-query(dfn[v]-1);
}
for(int i=0;i<G[x].size();i++){
int to=G[x][i];
dfs2(to);
}
add(dfn[x],-1);
}
signed main(){
cin>>s;
init();//建立字典树
build();
dfs1(0);
n=read();
for(int i=1;i<=n;i++){
int u=read(),v=read();
pb[pos[v]].push_back((problem){u,v,i});
}
dfs2(0);//这是在字典树上
for(int i=1;i<=n;i++) cout<<ans[i]<<endl;
return 0;
}
Substrings in a String
题目描述
你需要维护一个文本串,支持如下操作:
- 将文本串的第
- 给定一个模式串,查询其在文本串的
思路点拨
我们直接bitset。
#include<bits/stdc++.h>
using namespace std;
inline int read(){
int x=0,f=1;
char ch=getchar();
while(ch<'0'||ch>'9'){
if(ch=='-') f=-f;
ch=getchar();
}
while(ch>='0'&&ch<='9'){
x=x*10+ch-'0';
ch=getchar();
}
return x*f;
}
const int MAXN=1e5+10;
char c[MAXN];
int n,q;
bitset<MAXN> temp;
bitset<MAXN> pos[26];
signed main(){
scanf("%s",c+1);
n=strlen(c+1);
for(int i=1;i<=n;i++)
pos[c[i]-'a'][i]=1;
q=read();
while(q--){
int opt=read();
if(opt==1){
int p=read();
char ch;cin>>ch;
pos[c[p]-'a'][p]=0;
c[p]=ch;
pos[c[p]-'a'][p]=1;
}
else{
int l=read(),r=read();
string s;cin>>s;
int len=s.length();
temp.set();
for(int i=0;i<len;i++)
temp=temp&(pos[s[i]-'a']>>i);
printf("%d\n",(s.length()>r-l+1)?0:(temp>>l).count()-(temp>>(r-s.length()+2)).count());
//[l,r] 是我需要的区间,但是我们最终维护的temp数组只记录的字符串匹配的起点
//所以我们令len为字符串长度,那么我们在最终的temp中只需要考虑[l,r-len+1]
//我们先将bitset右移l,提取出[l,n],接着右移 r-len+2位,提取出我们需要的区间
//但是当字符串的长度大于询问区间的时候,bitset中任然可能有存留(l>r-len+1) ,我们需要特判,不然WA on 25
}
}
return 0;
}
test0717
今天的模拟赛太逆天了。
只会
T1 珠宝
题目描述
有
你有一个空间为
问价值
数据范围 :
思路点拨
我们按照一般的
我们比较一般的背包问题的数据规模和本题的数据规模,本题的物品数量十分庞大,但是物品的空间很小。
我们从物品的空间下手,从
首先,我们可以将这些物品价值降序排序,因为我们在同样的空间下总是会先选价值大的。
接下来,我们对这些物品做前缀和,保存到数组
转移的时候,我们发现,两个状态
所以我们枚举我们要转移的状态
那么我们将形如
这个式子对我们的时间没有任何的优化,但是
所以我们的决策点有单调性,使用分治或者单调队列上二分均可通过。本题还算是比较可做的。
T2 [JOI 2020 Final] 火事
题目描述
给定一个长为
定义
你将对
执行一个操作需要一定的代价,执行第
求每个操作需要的代价。
注意:每个操作都是独立的。
思路点拨
考虑
但是,当我们把
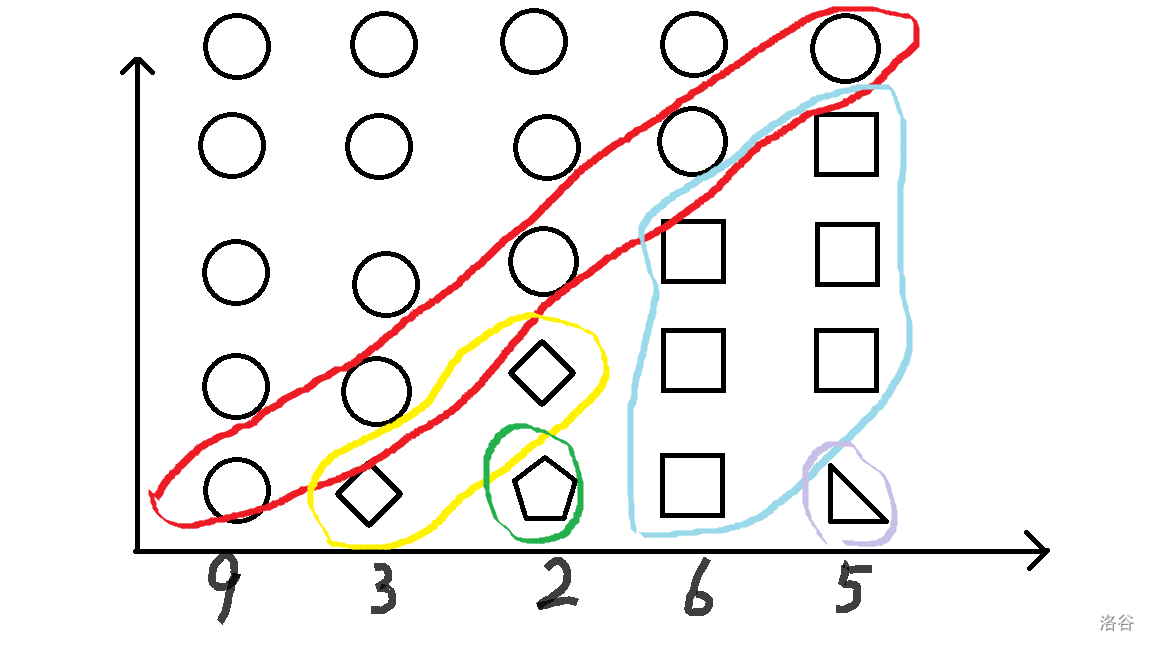
对于一个节点,我们定义
这个平行四边形的顶点分别是
那么每一次询问就是问一个线段
我们可以考虑将一个个平行四边形拆成若干个有规律的部分,使得可以更加方便计算。
一种十分简单的想法就是把一个平行四边形按照横坐标拆成一个个竖线,这样很好处理,但是全部的竖线数量过多。
我们注意到,如果按照纵坐标可以划分成一条条斜线。按照横坐标可以划分成
如何保证线的数量有限,可以利用笛卡尔树一个广为人知的结论
这个式子相当于询问笛卡尔树的每一个节点的左右儿子子树的最小值之和。
我们可以把
每一个节点至多被合并
接下来,我们对于横线和斜线分别考虑。
横线十分简单,将全部询问差分后离线下来就可以扫描线,比较无脑。
斜线不好搞,对于一群在同一条斜线上的点
我们将原平面直角坐标系的点
对于斜线转换后的横线,我们可以如法炮制同样操作。在维护扫描线的时候,考虑到本题时限比较紧张,使用
时间复杂度
T3 Mousetrap
题目描述
有一个有
一个老鼠被放进了迷宫,迷宫的管理者决定和老鼠做个游戏。
一开始,有一个房间被放置了陷阱,老鼠出现在另一个房间。老鼠可以通过走廊到达别的房间,但是会弄脏它经过的走廊。老鼠不愿意通过脏的走廊。
每个时刻,管理者可以进行一次操作:堵住一条走廊使得老鼠不能通过,或者擦干净一条走廊使得老鼠可以通过。然后老鼠会通过一条干净的并且没被堵住的走廊到达另一个房间。只有在没有这样的走廊的情况下,老鼠才不会动。一开始所有走廊都是干净的。管理者不能疏通已经被堵住的走廊。
现在管理者希望通过尽量少的操作将老鼠赶到有陷阱的房间,而老鼠则希望管理者的操作数尽量多。请计算双方都采取最优策略的情况下管理者需要的操作数量。
注意:管理者可以选择在一些时刻不操作。
对于所有的数据,
思路点拨
题目意思比较复杂,所以使用了更为清晰的原题面。
我们为了简化问题,我们将陷阱房作为数的根,这样老鼠就尽量远离根。
我们考虑这只倒霉的老鼠会怎么走。它会一头栽进一个子树然后被自己弄脏的路径困住。
那么在此时,我们伟大的管理员就可以把所有要封死的路径给堵住,最后把老鼠的路径擦干净。
我们先看看在一颗子树中,管理员的操作吧。我们定义
我们考虑类似于数学归纳法的方式求出这个
那么如果管理员无动于衷,老鼠会干什么?肯定会选一个
管理员此时是有一个步骤的,所以他可以把这个最大的
这是因为,我们的老鼠会钻进一个第二大
为什么子树内的边要堵上,有没有可能不堵边更优秀呢?不可能,因为老鼠钻进这条边就至少要擦一条边让他出来。不如花一条边堵上,多一事不如少一事。
对于
其中
但是,老鼠一开始不一定会往自己的子树钻,有可能会走到别个子树钻进去。这是十分复杂的。
注意到答案可以二分,我们对于一个值
bool lis[MAXN];//在s到t的路径上
bool check(int step){
int sum=0;//管理先手
for(int x=s;x!=t;x=dad[x]){
sum++;//我多一步
int ned=0;//这是我需要的步数
for(int i=0;i<e[x].size();i++){
int to=e[x][i];
if(lis[to]) continue;
if(f[to]+g[x]<=step) continue;
if(!sum) return 0;//步数不够,管理员速度不行
sum--;//少了一步
ned++;//这是要堵上的
}
step-=ned;
if(step<0) return 0;
}
return 1;
}
总体时间复杂度
这题太逆天了!
T4 小丑
题目描述
给定一张
思路点拨
我们发现删除操作十分的恶心,考虑转换成添加操作。我们可以将边的数组开两倍,对于一次删除操作

我们可以转换成判断
怎么求解
其实,
发现在分治的过程中,对于每一个分治的段,我们都需要花费大量时间计算并查集。但是,这个并查集可以从分治树的父亲处继承一部分。维护可持久化并查集或者可撤销并查集即可。
时间复杂度
test0719
本场比赛难度还可以,T1和T2还是比较可做。但是题目编排三道计数我真服了。
T1 镜子

思路点拨
首先,对于一般的情况可以拆点分开考虑方向,比较简单。这不是本题的重点。
你可能会疑惑,一面添加的镜子可以用两面,这一点该如何处理?
如果一个格子放了两个镜子,又该怎么办?
其实,上述疑惑都是没有必要的。看图:
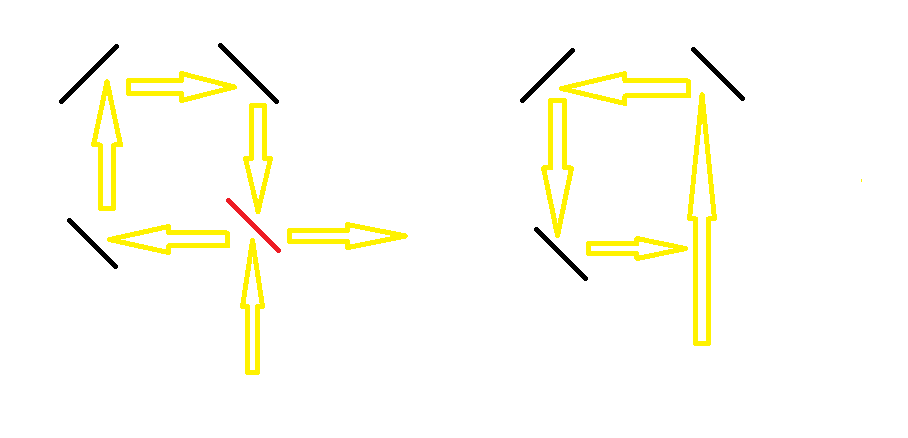
至于一个格子放两个镜子的情况,大家可以感性一下,如果这个格子被经过两个不同的方向,还是由不同方向的镜子折射的,这一定是不优秀的。我们根本不需要考虑上述两种情况。
本题时限比较紧张,考虑到边权只有
T2 [USACO20DEC] Sleeping Cows P
题目描述
Farmer John 有
每天晚上,奶牛们都会按照某种方式寻找睡觉的牛棚。奶牛
我们称奶牛与牛棚的一个匹配是极大的,当且仅当每头奶牛可以进入分配给她的牛棚,且对于每头未被分配牛棚的奶牛无法进入任何未分配的空牛棚。
计算极大的匹配的数量模
思路点拨
我们先可以发现一些显然的事实:
-
本题的组合意义并不是十分明显,计数题可以考虑动态规划。
-
我们没有考虑给其分配牛棚的体积最小的牛也必须大于最大的未匹配牛棚,不然会不合法。
为了消除第二点事实给我们带来的繁杂的影响,我们考虑将牛和牛棚放一起排序。这个
现在我们想想我们的状态需要一些什么。
目前考虑到的下标,这是显然的。
目前待选择牛棚的牛的数量,因为牛棚会减少牛的数量,选择牛会增加牛的数量。
还有一点,我们讲到第二点事实所引出的,需要记录目前下标内的牛是否被全选。
综合下来,我们定义
考虑转移分两类讨论——牛和牛棚:
牛的转移
目前这头牛我们可以选或者不选,对于之前就有没选择的牛的那些状态:
之前的牛都选择的那些状态的转移:
为什么是
牛棚的转移
目前我们存在牛未选的话,这个牛棚必须选,比较简单,略。
如果全部的牛都选的话,这个牛棚爱选不选都可以:
上述的转移都是比较好理解的吧。
我们的初始状态就是
时间复杂度
T3 [JOISC2018] 修行
题目描述
求有多少个长度为
对于
对于
思路点拨
部分分
本题的
定义
转移分两类讨论,
正解
考虑容斥,令
二项式反演得:
那么我们考虑
我们带回一般式:
有两个
前边都是快速幂的柿子,我们想后边的卷积:
其实它是有组合意义的,就是我们考虑将
所以上述的卷积柿子就是


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 25岁的心里话
· 按钮权限的设计及实现