Hash table and application in java
查找的效率取决于在查找是比较的次数,次数越少效率越高,反之越低。最理想的情况是无需比较,一次存取便能找到所查找的记录。根据对应关系f找到给定值K的像f(K),hash function 应运而生,由此思想建的表称为hash table
- 集合hashset底层用的是hashmap。HashSet 封装了一个 HashMap 对象来存储所有的集合元素, HashSet 中的集合元素由 HashMap 的 key 来保存,而 HashMap 的 value 则存储了一个 PRESENT(一个静态的 Object 对象)。
- hash algorithm,HA是一类算法(Hash的原意本是杂凑);hash table,HT是一种数据结构;hash functions,HF是支撑hash table的一类函数
- HA:从不同的输入中,通过一些计算摘取出来一段数据值,来进行区分输入数据。(例:MD5);目的:1.信息安全领域:做加密算法;2.数据结构领域:快速查找。
- HT:根据设定的哈希函数H(key)和处理冲突的方法将一组关键字映像到一个有限的连续的地址集上,并以关键字在地址集中的“像”作为记录在表中的存储位置,这种表称为HT。这一映像过程称为哈希造表或散列,所得存储位置称哈希地址或散列地址。
- HF:根据对应关系f找到给定值K的像f(K),若结构中存在关键字和K相等的记录,则必定在f(K)的存储位置上,由此不需要进行比较便可以直接取得所查记录。在此我们称这个对应关系f为HF。
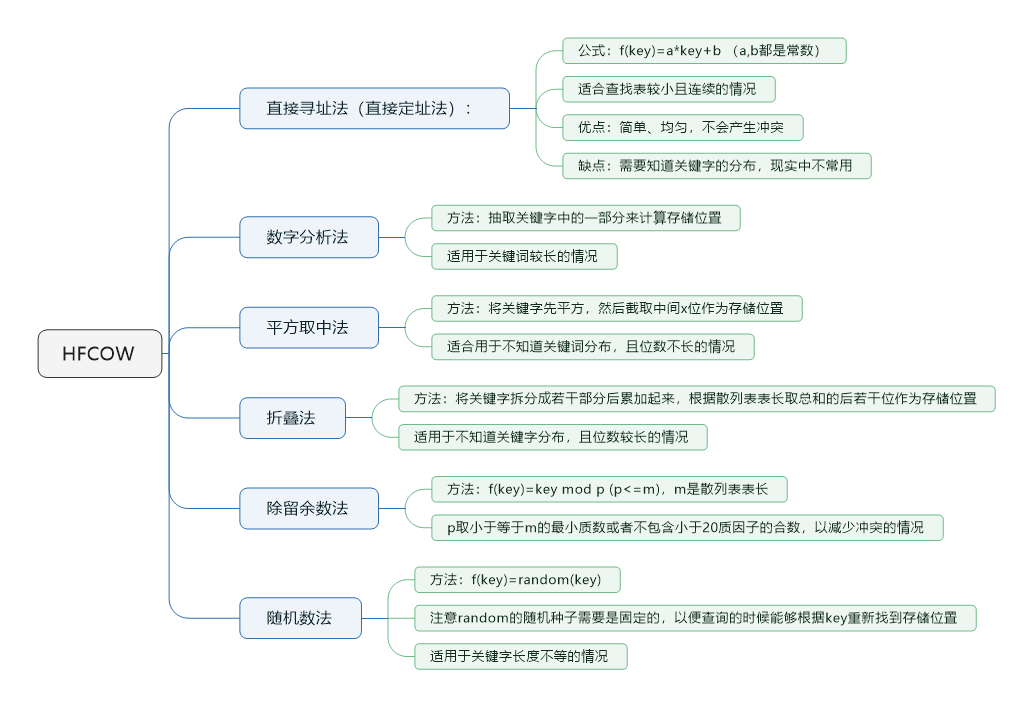
- Hash function`s construct of way:
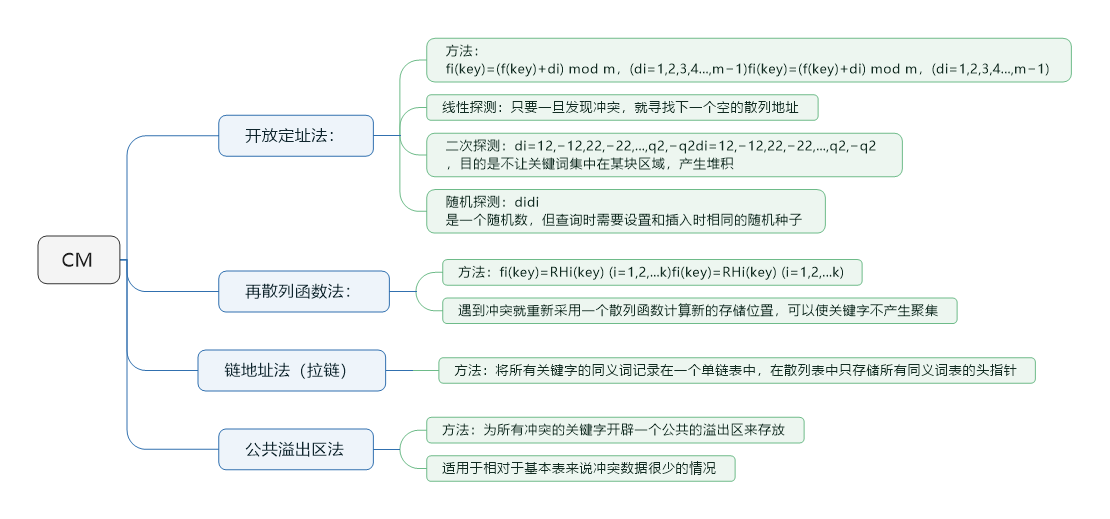
- Conflict Management
treeset保证唯一性。1.让元素自身具备比较性 implements Comparable,重写comparaTo()方法,2.让容器自身具备比较性,implemens Comparator,重写compara()方法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号