机器学习|特征缩放
什么是特征缩放
特征缩放又称归一化,是机器学习中的一种技术,涉及调整数值数据的量度,使所有数据点在相似的尺度上。例如:身高、体重、年龄、收入等个人特征数据,每个维度的区间不一样,为保证所有维度的特征数据尺度一样,我们就需要对原始数据做特征缩放,将身高、体重、年龄、收入都转化为区间[0,1]之间的数据。
为什么要做特征缩放
- 收敛速度:梯度下降等迭代方法在各特征尺度一致时会更快地收敛。
- 避免数值不稳定性:在某些算法中,如果特征的尺度差异很大,可能会导致数值计算问题。
- 更好的模型解释性:当所有特征都在同一个尺度上,它们的权重可以更容易地相互比较。
目的
- 使数据均匀:数据缩放通过将数据转换到新的尺度上,使不同特征间的数值大小差异减小。
- 提高算法性能:缩放可以加快梯度下降的收敛速度,并提高算法(如支持向量机和 K 近邻算法)的性能。
特征缩放方法
-
最小-最大缩放 (Min-Max Scaling)
- 公式: \(X_{norm} =\frac {X - X_{min}} {X_{max} - X_{min}}\)
- 描述: 将数据缩放到[0,1]范围内的技术。
- 场景: 当数据分布不是高度偏斜,并且不包含极端值时。
-
标准化 (Standardization)
- 公式: \(X_{standard} =\frac {(X - μ)} σ\)
- 描述: 通过使数据的平均值为 0,标准差为 1 来缩放数据。
- 场景:当算法需要数据的标准差为 1,且偏差很小时。
-
稳健缩放 (Robust Scaling)
- 公式: \(X_{robust} =\frac {X - Q1} {Q3 - Q1}\)
- 描述: 缩放技术,可以减少离群值的影响。
- 场景:当数据包含许多离群值或异常值时。
-
L2 Normalization (欧几里得范数)
- 公式: \(X_{l2} =\frac {X - μ} {||X||_2}\)
- 描述: 通过使特征向量的欧几里得长度为 1 来缩放特征。
- 场景:在图像处理和文本分类中,当数据的方向比其大小更重要时。
-
L1 Normalization
- 公式: \(X_{l1} =\frac {X - μ} {||X||_1}\)
- 描述: 通过使特征向量的欧几里得长度为 1 来缩放特征。
- 场景:在图像处理和文本分类中,当数据的方向比其大小更重要时。
-
Power Transformer
a. Box-Cox Transformation- 公式: \(X_{Box-Cox} =\frac {X^{\lambda}-1} {\lambda},for \quad \lambda \neq 0,ln(X) \quad for \quad \lambda=0\)
- 描述: Box-Cox 转换只能应用于正值的数据。它的目标是对非常数方差和非正态分布的数据进行变换,使其更接近正态分布。
- 场景:
- 线性模型:在回归、ANOVA 或设计实验中,当我们希望满足线性模型的正态分布假设时。
- 时间序列分析:稳定化时间序列数据的方差。
- 方差稳定化:在很多统计模型中,稳定的方差是关键。Box-Cox 转换能够稳定化方差,使其不随因变量的值而变化。
- 处理倾斜数据:对于正偏斜或负偏斜的数据,Box-Cox 转换可以帮助减少偏斜。
b. Yeo-Johnson Transformation
- 公式:
\(X_{yeo-Johnson}=\frac {(X+1)^{\lambda}-1} {\lambda} \quad for \quad \lambda \neq 0 \quad and \quad X \geq 0,ln(X+1) \quad for \quad\lambda=0 \quad and \quad X \geq 0,-\frac {(-X+1)^{\lambda}-1} {\lambda} \quad for \quad \lambda \neq 0 \quad and \quad X < 0, -ln(-X+1) \quad for \quad \lambda=0 \quad and \quad X <0\) - 描述: Yeo-Johnson 转换是 Box-Cox 的扩展,它可以应用于正值、负值和零的数据。这种转换同样旨在使数据更接近正态分布。
- 场景:
- 广义线性模型:当我们需要满足广义线性模型的正态分布假设时。
- 包含零或负值的数据:与 Box-Cox 不同,Yeo-Johnson 转换可以应用于包含零或负值的数据。
- 方差稳定化:与 Box-Cox 类似,Yeo-Johnson 转换也可以用来稳定化方差。
- 处理倾斜数据:对于正偏斜或负偏斜的数据,Yeo-Johnson 转换也是一个有效的工具。
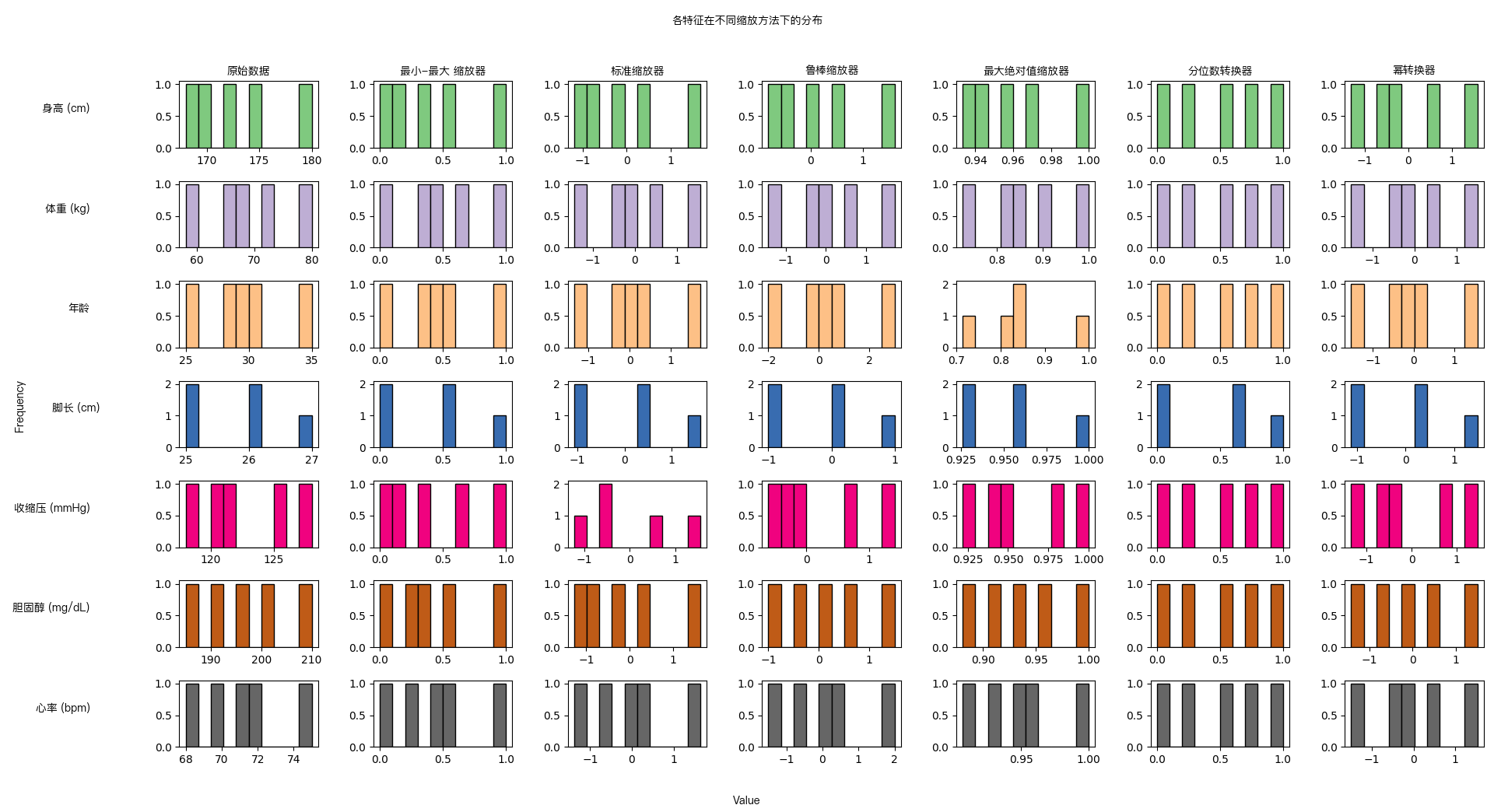
数据缩放对比
原始数据
| ID | 身高(cm) | 体重(kg) | 心率(bpm) | 胆固醇(mg/dL) | 年龄 | 脚长(cm) |
|---|---|---|---|---|---|---|
| 1 | 170 | 68 | 75 | 180 | 25 | 25 |
| 2 | 160 | 50 | 80 | 200 | 30 | 23 |
| 3 | 180 | 77 | 72 | 220 | 28 | 27 |
| 4 | 175 | 65 | 78 | 210 | 32 | 26 |
| 5 | 166 | 58 | 82 | 190 | 29 | 24 |
python 代码
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import (MinMaxScaler, StandardScaler, RobustScaler,
MaxAbsScaler, QuantileTransformer, PowerTransformer)
from matplotlib.font_manager import FontProperties
# 设置中文字体路径
myFont = FontProperties(fname='/System/Library/Fonts/PingFang.ttc')
# Create the dataset
data = {
'身高 (cm)': [170, 175, 168, 180, 172],
'体重 (kg)': [65, 72, 58, 80, 68],
'年龄': [25, 30, 28, 35, 29],
'脚长 (cm)': [25, 26, 25, 27, 26],
'收缩压 (mmHg)': [120, 125, 118, 128, 121],
'胆固醇 (mg/dL)': [190, 200, 185, 210, 195],
'心率 (bpm)': [70, 72, 68, 75, 71]
}
df = pd.DataFrame(data)
# Define a unique color for each feature
colors = plt.cm.Accent(np.linspace(0, 1, len(df.columns)))
# Scaling methods
scalars = {
'原始数据': None,
'最小-最大 缩放器': MinMaxScaler(),
'标准缩放器': StandardScaler(),
'鲁棒缩放器': RobustScaler(),
'最大绝对值缩放器': MaxAbsScaler(),
'分位数转换器': QuantileTransformer(n_quantiles=5),
'幂转换器': PowerTransformer(method='yeo-johnson')
}
# Determine the number of rows and columns for the subplots
n_features = len(df.columns)
n_scalars = len(scalars)
n_rows = n_features
n_cols = n_scalars
fig, axes = plt.subplots(nrows=n_rows, ncols=n_cols, figsize=(20, 4 * n_features))
for row, feature in enumerate(df.columns):
for col, (name, scaler) in enumerate(scalars.items()):
ax = axes[row, col]
if scaler:
scaled_data = scaler.fit_transform(df[[feature]])
else:
scaled_data = df[[feature]].values
ax.hist(scaled_data, bins=10, color=colors[row], edgecolor='black')
if row == 0:
ax.set_title(name, fontproperties=myFont)
if col == 0:
ax.set_ylabel(feature, fontproperties=myFont, rotation=0, labelpad=60, ha='right')
fig.text(0.5, 0.01, 'Value', ha='center', fontproperties=myFont)
fig.text(0.01, 0.5, 'Frequency', va='center', rotation='vertical', fontproperties=myFont)
# Adjust layout
plt.tight_layout(pad=1.0)
plt.subplots_adjust(top=0.90,left=0.12, wspace=0.4, hspace=0.5,bottom=0.08)
plt.suptitle("各特征在不同缩放方法下的分布", fontproperties=myFont)
plt.show()
特征缩放图示

 浙公网安备 33010602011771号
浙公网安备 33010602011771号