深入理解Java虚拟机读书笔记 -- Java内存区域
Graal VM: Run Programs Faster Anywhere. 跨语言全栈虚拟机,可以作为“任何语言”的运行平台使用。
Java内存结构
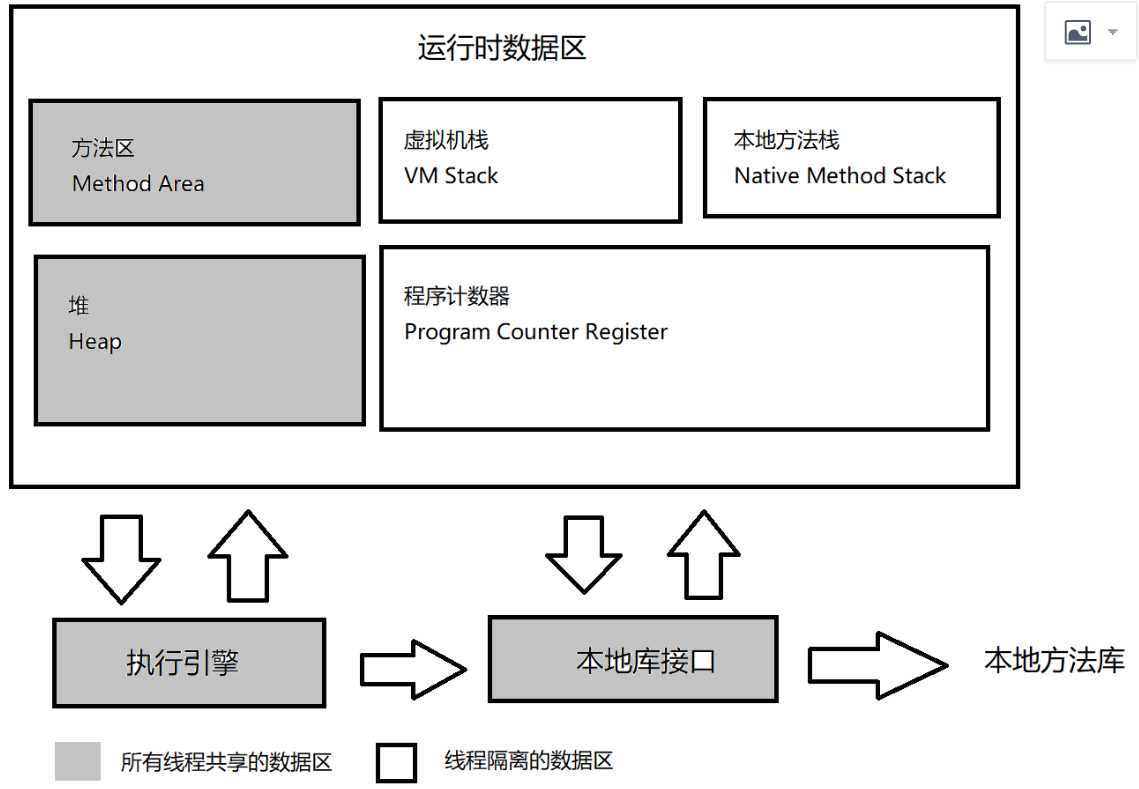
程序计数器:线程私有,较小的内存空间。可以看作是当前线程所执行的字节码的行号指示器。在概念模型里,字节码解释器工作时就是通过改变这个计数器来选取下一条需要执行的字节码指令。因为java虚拟机的多线程时通过线程轮流切换、分配处理器执行时间来实现的,所以为了线程切换之后能恢复,每条线程都需要一个独立的程序计数器。如果线程执行的是一个java方法,则记录虚拟字节码指令的地址,如果是本地方法,这个计数器为空。这个内存区域是唯一一个在《java虚拟机规范》中没有规定OOM的区域。
java虚拟机栈:线程私有。描述java方法执行的线程内存模型:每个方法被执行的时候,JVM都会同步创建一个栈帧(Stack Frame)用于存局部变量表,操作数栈,动态连接,方法出口等。每个方法调用直到执行完毕,就对应一个栈帧在虚拟机栈从入栈到出栈的过程。
局部变量表存放了编译期可知的JVM基本数据类型、对象引用和returnAddress类型(指向一条字节码指令的地址)。这些数据类型在局部变量表的存储以局部变量槽(Slot)来表示,其中64位的long和double会占用2个槽,其余类型占用一个。局部变量表的内存空间是在编译期间完成分配,当进入一个方法,该方法需要多大的局部空间是确定的,运行期间不会改变局部变量表大小。这里“大小”指的是槽的数量。JVM使用多大空间实现一个槽(32bit、64bit或更多),由JVM决定。
如果线程请求超过JVM所允许的深度,抛StackOverflowError。虚拟机栈容量如果扩展,没空间扩展报OOM。如果是HotSpot,线程申请栈空间失败,报OOM。
本地方法栈:和虚拟机栈类似,区别是本地方法栈为本地方法服务。JVM规范没有强制规定本地方法栈的实现。也可能Stackoverflow和OOM。
Java堆:所有线程共享,存放实例对象。JVM规范描述:所有的对象实例以及数组都应当在堆上分配。逻辑上连续的内存空间。主流的JVM都是按照可扩展来实现的(通过-Xmx和-Xms设定)。如果在java堆中没有内存完成实例分配,并且堆也无法再扩展,JVM抛出OOM。
方法区:各个线程共享的内存区域,存储被JVM加载的类型信息(类的结构)、常量、静态变量、即时编译器编译后的代码缓存等数据。JVM规范堆方法区的约束非常宽松,除了和java堆一样不需要连续的内存和可以选择固定大小或者可扩展外,甚至可以选择不实现垃圾回收。GC在这个区比较少,主要针对常量池的回收和类型的卸载。JVM规范规定,方法区无法满足新内存时,抛出OOM。
运行时常量(Runtime Constant Pool):方法区的一部分。Class文件除了有类的版本、字段、方法、接口等描述信息外,还有常量池表(Constant Pool Table),用于存放编译期生成的各种字面量与符号引用,这部分会在类加载后放到方法区的运行时常量池中。JVM对于Class文件的每一部分的格式都有严格的规定。运行时常量池相对与Class文件常量池,具备动态性,运行时也可以将新的常量放入池。也会OOM。
HotSpot虚拟机
普通对象(不包括数组和Class对象)的创建
a. 当JVM遇到一个字节码new指令时,首先检查这个指令是否能在常量池中定位到一个类的符号引用,并检查这个引用代表的类是否被加载、解析和初始化。若没有,则必须先执行相应的类加载过程。对象需要的内存在类加载完成之后便可完全确定。
划分内存有2种:
是否规整由垃圾收集器是否带有压缩整理(Compact)的能力决定的。
1、如果内存是规整的(使用内存放一边,空间放另一边,中间有个分界点的指针),那就把指针向空闲空间移动,即“指针碰撞”(Bump The Pointer),Serial、ParNew等带Compact能力。
2、如果不是规整的,JVM需要维护一个列表,记录哪些内存可用,在列表找到可用空间,分配给对象实例,即“空闲列表”(Free List)。CMS使用基于清除(Sweep)算法的收集器。不过CMS的实现中,为了在多数情况下分配更快,设计了Linear Allocation Buffer的分配缓冲区,通过空闲列表拿到一大块分配缓冲区,在里面仍然使用指针碰撞。
分配内存的线程安全:1、CAS配上失败重试的方式保证更新操作的原子性。 2、把分配内存的动作按照线程划分在不同空间中进行,即每个线程在java堆中预先分配一小块内存,称为本地线程分配缓冲(Thread Local Allocation Buffer,TLAB),只有本地缓冲区用完了,分配新的缓冲区时才需要同步锁定。用-XX:+/-UseTLAB设置。
b.内存分配完,JVM必须将分配到内存空间(不包括对象头)初始化为零值。使用了TLAB,则提前至TLAB。
c.JVM对对象头进行必要设置,设置对象属于哪个类的实例,类的元数据信息,对象的哈希码(实际会延后到调用Object::hashCode()才计算),对象的GC分代年龄等。
java编译器会在遇到new关键字,生成new指令和invokespecial(执行构造方法)指令。
对象的内存布局
对象在堆存储布局:对象头(Header)、实例数据(Instance Data)和对齐填充(Padding)。
对象头:Mark Word + 类型指针
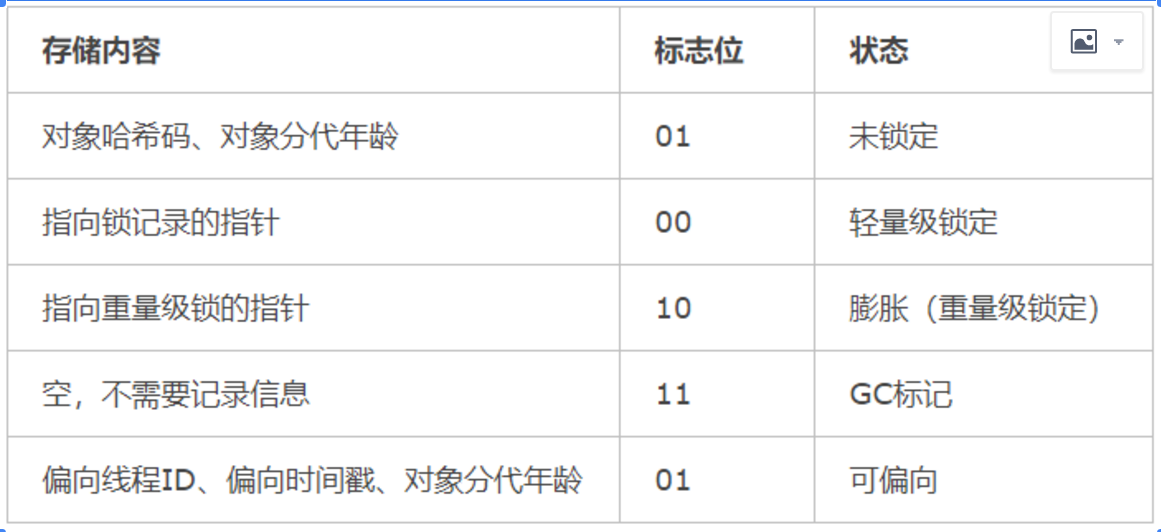
Mark Word:哈希码,GC分代年龄、锁状态标志、线程持有的锁、偏向线程ID、偏向时间戳等,这部分数据的长度在32位和64位的虚拟机(未开启指针压缩)中分别位32和64bit。
不同状态,对象头的内容如下:
类型指针:对象指向它的类型元数据的指针,JVM通过这个指针确定对象是哪个类的实例。(并不是所有的JVM实现都必须在对象头保留类型指针,即查找对象的元数据信息不一定要经过对象本身)。
如果对象是java数组,对象头还有一块用来记录数组长度。
实例数据:各种类型的字段内容必须记录起来。存储顺序受虚拟机分配策略参数影响
(-XX:FieldsAllocationStyle)和字段在java源码中定义顺序的影响。
HotSpot默认的分配顺序:longs/doubles、ints、shorts/chars、bytes/booleans、oops(Ordinary Object Pointers),相同宽度的字段总是分配到一起,在满足这个前提下,父类定义的变量会在子类之前。如果HotSpot的+XX:CompactFields参数值为true(默认就是true),那子类较窄的变量也允许插入父类变量空隙之中,节约空间。
对齐填充:占位符填充。HotSpot的自动内存管理系统要求对象起始地址必须是8字节的整数倍,所以任何对象的大小都必须是8字节的整数倍,对象头部分已经被精心设计成正好是8字节的1倍或者2倍,因为实例数据部分需要对齐填充。
对象的访问定位
对象访问由JVM实现,主要的访问方式:句柄和直接指针。
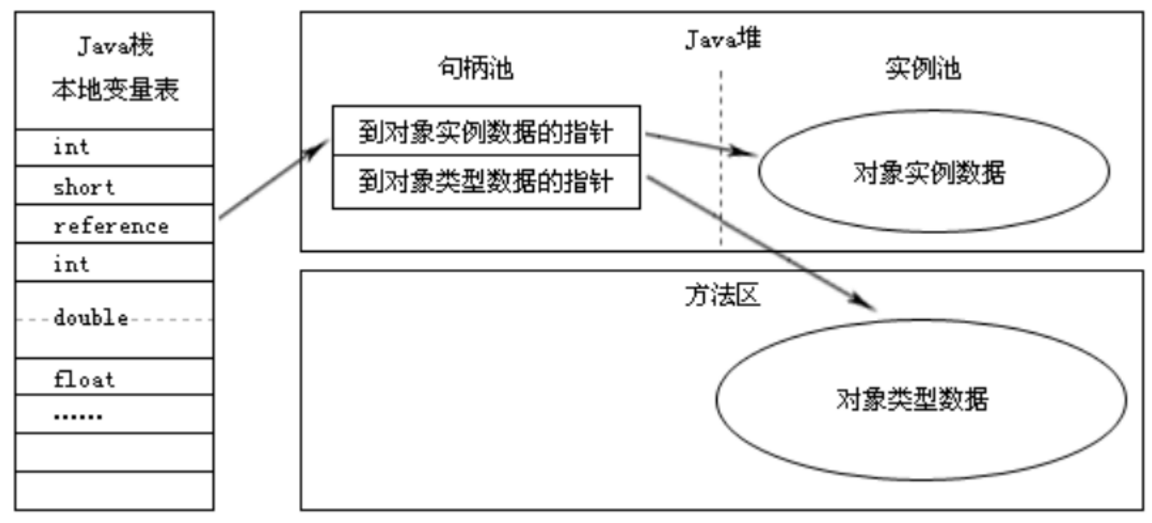
句柄:堆中划分一块内存来作为句柄池,reference存储的是对象的句柄地址,句柄中包含了对象实例数据和类型数据(对象元数据)各自具体的地址信息。reference存储的是稳定的句柄地址,在对象被移动的(GC时对象移动很普遍)时候只会改变句柄的实例数据指针,reference本身不需要修改。
直接指针:reference中存储的直接是对象地址,对象要包含类型数据的信息。如果只是访问对象本身,节省和一次指针定位开销。HotSpot主要使用这种(如果使用Shenandoah收集器的话也会有一次额外的转发)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号