
helm安装kafka集群并测试其高可用性
介绍
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。 对于像Hadoop一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消息。
一、KAFKA
体系结构图:

- Producer: 生产者,也就是发送消息的一方。生产者负责创建消息,通过zookeeper找到broker,然后将其投递到 Kafka 中。
- Consumer: 消费者,也就是接收消息的一方。通过zookeeper找对应的broker 进行消费,进而进行相应的业务逻辑处理。
- Broker: 服务代理节点。对于 Kafka 而言,Broker 可以简单地看作一个独立的 Kafka 服务节点或 Kafka 服务实例。大多数情况下也可以将 Broker 看作一台 Kafka 服务器,前提是这台服务器上只部署了一个 Kafka 实例。一个或多个 Broker 组成了一个 Kafka 集群。一般而言,我们更习惯使用首字母小写的 broker 来表示服务代理节点
Send消息流程图:
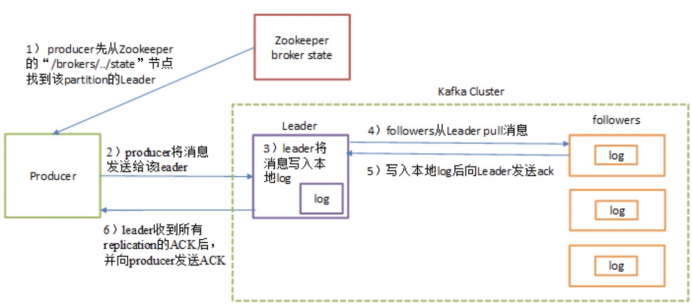
全程解析(Producer-kafka-consumer)
producer 发布消息
producer 采用 push 模式将消息发布到 broker,每条消息都被 append 到 patition 中,属于顺序写磁盘(顺序写磁盘效率比随机写内存要高,保障 kafka 吞吐率)。producer 发送消息到 broker 时,会根据分区算法选择将其存储到哪一个 partition。
其路由机制为:
- 指定了 patition,则直接使用;
- 未指定 patition 但指定 key,通过对 key 进行 hash 选出一个 patition;
- patition 和 key 都未指定,使用轮询选出一个 patition。
写入流程:
- producer 先从 ZooKeeper 的 "/brokers/.../state" 节点找到该 partition 的leader;
- producer 将消息发送给该 leader;
- leader 将消息写入本地 log;
- followers 从 leader pull 消息,写入本地 log 后 leader 发送 ACK;
- leader 收到所有 ISR 中的 replica 的 ACK 后,增加 HW(high watermark,最后 commit 的 offset) 并向 producer 发送 ACK;
Kafka多副本(Replica)机制:
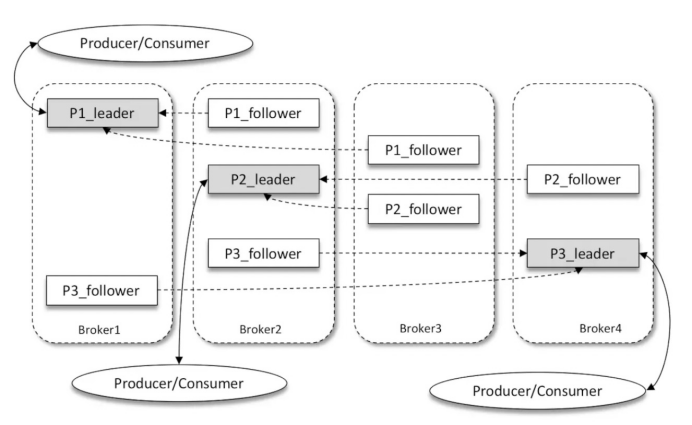
如上图所示,Kafka 集群中有4个 broker,某个主题中有3个分区,且副本因子(即副本个数)也为3,如此每个分区便有1个 leader 副本和2个 follower 副本。生产者和消费者只与 leader 副本进行交互,而 follower 副本只负责消息的同步,很多时候 follower 副本中的消息相对 leader 副本而言会有一定的滞后。
二、Zookeeper
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
原理:
高可以用架构图:
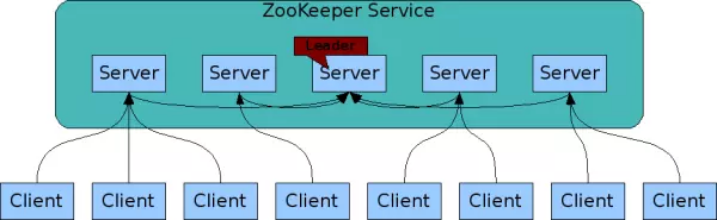
图中每一个Server代表一个安装Zookeeper服务的服务器。组成 ZooKeeper 服务的服务器都会在内存中维护当前的服务器状态,并且每台服务器之间都互相保持着通信。集群间通过 Zab 协议(Zookeeper Atomic Broadcast)来保持数据的一致性。
三、部署kafka&zookeeper集群
我们选择的是官方的chart地址:https://github.com/helm/charts/tree/master/incubator/kafka
1)编写自己的values.yaml文件(注意我的storageClass是已经做好了的nfs存储)
imageTag: "5.2.2"
resources:
limits:
cpu: 2
memory: 4Gi
requests:
cpu: 1
memory: 2Gi
kafkaHeapOptions: "-Xmx2G -Xms2G"
persistence:
enabled: true
storageClass: "managed-nfs-storage"
size: "40Gi"
zookeeper:
resources:
limits:
cpu: 1
memory: 2Gi
requests:
cpu: 100m
memory: 536Mi
persistence:
enabled: true
storageClass: "managed-nfs-storage"
size: "10Gi"
2)安装kafka
添加chart仓库:
$ helm repo add incubator http://storage.googleapis.com/kubernetes-charts-incubator
部署
$ helm install --name kafka -f values.yaml incubator/kafka
最后我们能看到:

四、测试kafka高可用性
1)根据提示创建一个测试客户端
apiVersion: v1
kind: Pod
metadata:
name: testclient
namespace: sscp-test
spec:
containers:
- name: kafka
image: solsson/kafka:0.11.0.0
command:
- sh
- -c
- "exec tail -f /dev/null"
Once you have the testclient pod above running, you can list all kafka
topics with:
kubectl -n sscp-test exec testclient -- kafka-topics --zookeeper kafka-test-zookeeper:2181 --list

To create a new topic:
kubectl -n sscp-test exec testclient -- kafka-topics --zookeeper kafka-test-zookeeper:2181 --topic test1 --create --partitions 1 --replication-factor 1

To listen for messages on a topic:
kubectl -n sscp-test exec -ti testclient -- for x in {1..1000}; do echo $x; sleep 2; done | kafka-console-producer --broker-list kafka-test-headless:9092 --topic test1
To stop the listener session above press: Ctrl+C
To start an interactive message producer session:
kubectl -n sscp-test exec -ti testclient -- kafka-console-producer --broker-list kafka-test-headless:9092 --topic test1
To create a message in the above session, simply type the message and press "enter"
To end the producer session try: Ctrl+C
查看topic连接状态
kafka-consumer-groups --bootstrap-server kafka-sit:9092 --describe --group device-group
泄洪命令
kafka-consumer-groups --bootstrap-server kafka-sit:9092 --group device-group --reset-offsets --to-latest --topic transport-device-req --execute
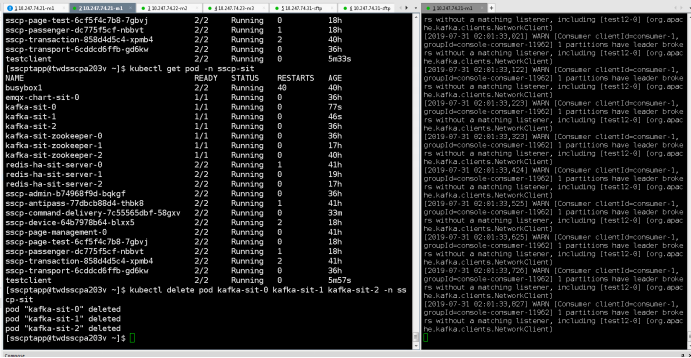
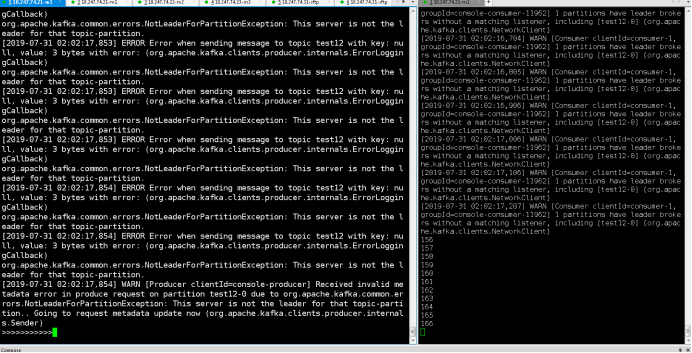
注意:有三个kafka节点,消息要发三个副本才能保持其高可用!!!
#查看group kafka-consumer-groups --bootstrap-server kafka:9092 --list #group下topic详细信息 kafka-consumer-groups --describe --bootstrap-server kafka:9092 --group logstash #删除topic kafka-topics --delete --topic logs-7.15.0 --zookeeper kafka-zookeeper:2181
五、测试Zookeeper高可用性
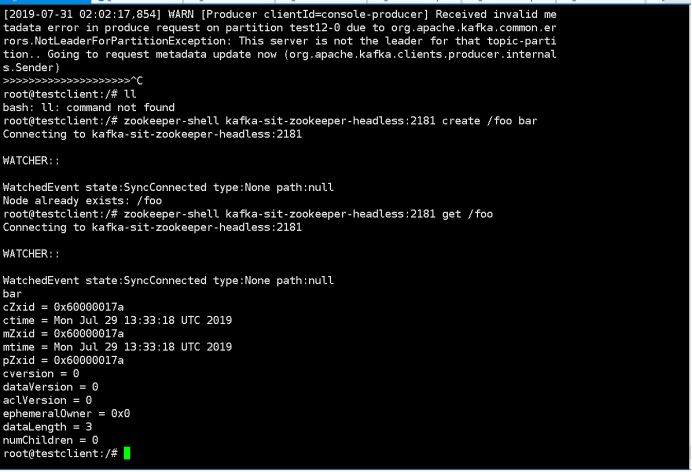
1.Create a node by command below:
“kubectl exec -it testclient bash -n sscp-test”
“zookeeper-shell kafka-test-zookeeper-headless:2181 create /foo bar”
2. Check zookeeper status
Watch existing members:
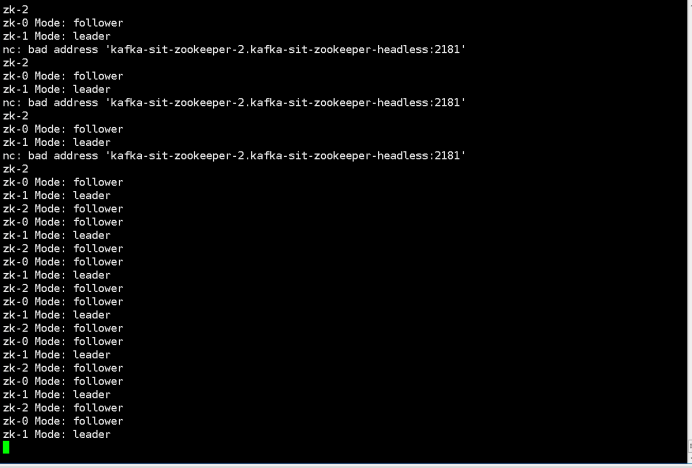
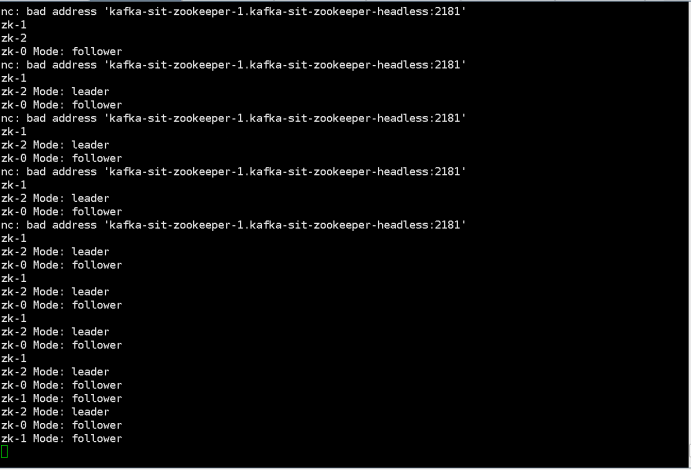
$ kubectl run --attach bbox --image=busybox --restart=Never -- sh -c 'while true; do for i in 0 1 2; do echo zk-${i} $(echo stats | nc kafka-zookeeper-${i}.kafka-zookeeper-headless:2181 | grep Mode); sleep 1; done; done'
zk-2 Mode: follower
zk-0 Mode: follower
zk-1 Mode: leader
zk-2 Mode: follower
3.kill the leader by command below:
“Kubectl delete pod kafka-test-zookeeper-1”
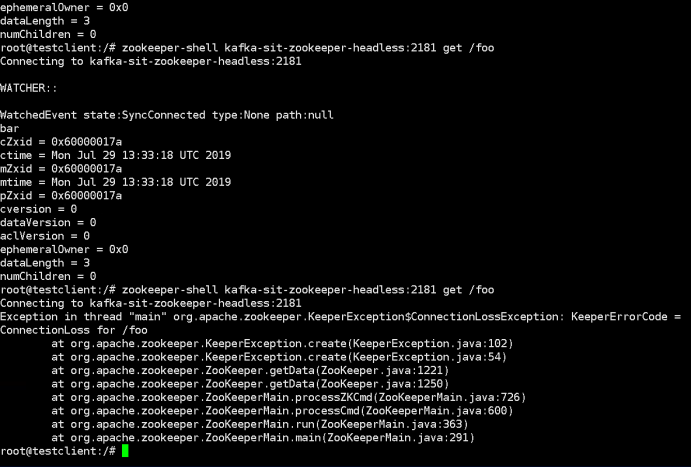
4.Check the previously inserted key by command below:
““kubectl exec -it testclient bash -n sscp-test”
“zookeeper-shell kafka-test-zookeeper-headless:2181 get /foo”
微信

支付宝


 浙公网安备 33010602011771号
浙公网安备 33010602011771号