似然
似然
-
问题背景:
- 我们观察到随机变量 的值 ,而 的概率密度函数 已知,但依赖于参数 。
- 参数 来自参数空间 ,观测数据来自样本空间 。
- 目标是根据观测数据 ,推断参数 的可能取值范围。
-
似然函数的定义:
- 似然函数 表示给定数据 时,参数 的可能性大小,定义为:
- 似然函数反映了接近生成数据的 值会使 较大。
- 似然函数 表示给定数据 时,参数 的可能性大小,定义为:
-
离散和连续情况:
- 当 是离散的, 表示 的概率。
- 当 是连续的, 表示概率密度函数。
-
独立观测的似然函数:
- 当 是 个独立观测值的集合 时,似然函数为:
- 当 是 个独立观测值的集合 时,似然函数为:
例 4.1(泊松分布)
假设 是来自泊松密度 (2.6) 的一个观测值。此处数据和参数都是标量,并且:
参数空间是 ,样本空间是 。如果 , 是 的单调递减函数;如果 , 在 处达到最大值,并且在 趋近于零或无穷大时极限值为零。
图 4.1
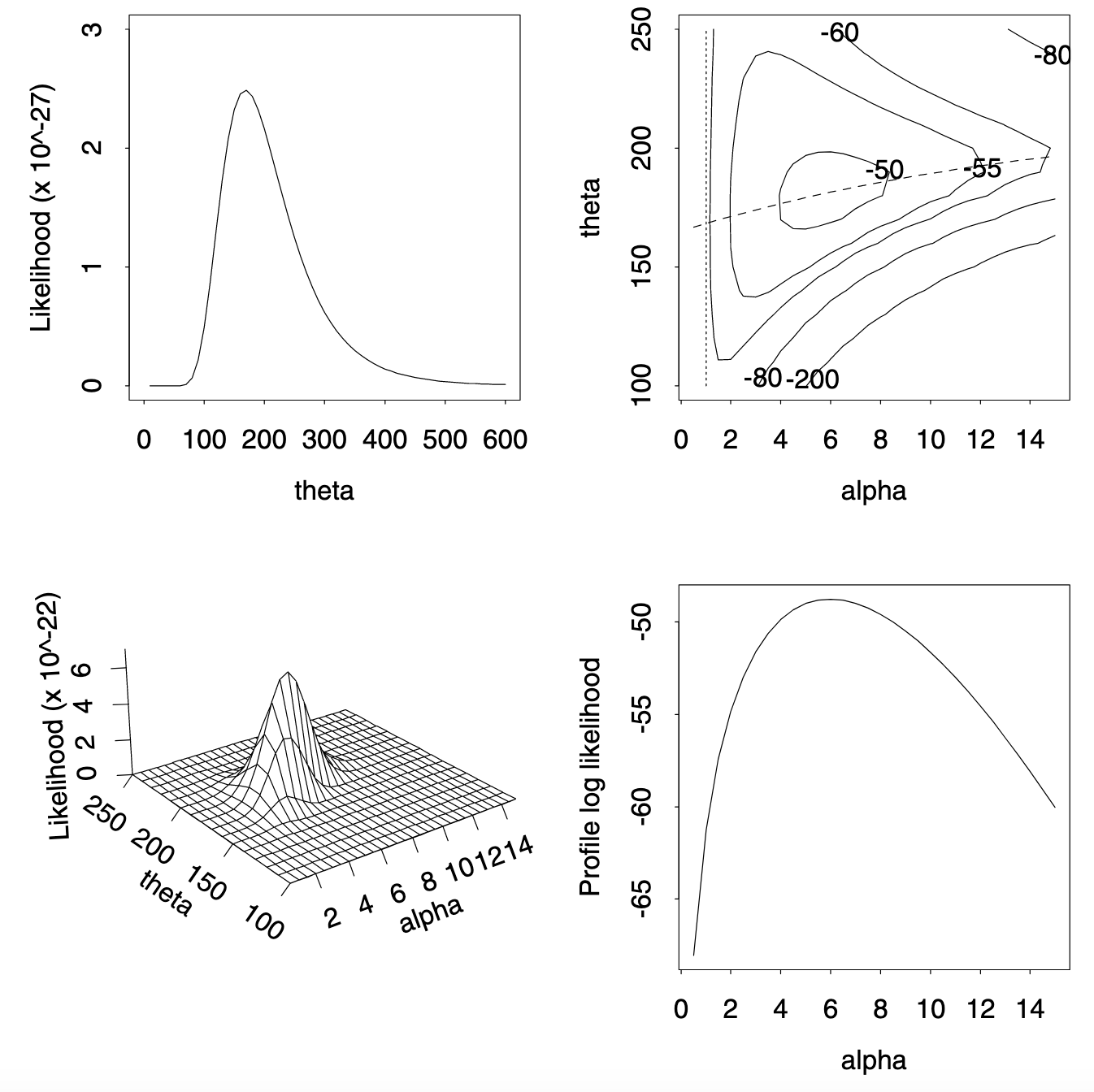
该图展示了在 950 N/mm² 应力下的弹簧失效数据的似然函数。左上角面板是指数模型的似然函数,下方是韦伯模型的似然函数的透视图。右上角面板显示了韦伯模型的对数似然函数等高线图;通过设定 来获得指数模型的似然函数,即沿着垂直虚线切割 。右下角面板显示了 的轮廓对数似然函数,对应于沿上方面板中虚线的对数似然值,对应绘制于 。
例 4.2(指数分布)
设 是来自指数密度 的随机样本 ,其中 。参数空间为 ,样本空间是笛卡尔积 。这里 (4.2) 给出:
在例 1.2 中,在应力 950 N/mm² 下弹簧失效时间为:225, 171, 198, 189, 189, 135, 162, 135, 117, 162,图 4.1 的左上角面板显示了似然函数 (4.3)。该函数是单峰的,在 处达到最大值;。在 时, 等于 ,所以 150 作为解释数据的可能性是 倍于 的可能性。如果我们声明对于 为“合理的” 的取值,那么当 时, 在 (120, 260) 范围内是合理的。
例 4.3(柯西分布)
以 为中心的柯西密度为 ,其中 且 。因此随机样本 的似然函数为:
样本空间是 ,参数空间是 。图 4.2 的左面板显示了例 4.2 的弹簧数据的 。在 的范围内似然函数有三个局部极大值,其中全局极大值为 。右面板显示了对数似然函数 的更多细节。图中至少有四个局部极大值——显然每个观测值都有一个,尤其是在观测值重复时。与前例相比,对于某些 值, 的“合理”集合由不相交区间组成。
例 4.4(韦伯分布)
韦伯密度为:
当 时,这是例 4.2 中的指数密度;指数模型嵌套在韦伯模型中,参数空间是 ,样本空间是 。来自 (4.4) 的随机样本 的联合密度为:
因此似然函数为:
图 4.1 的左下角面板显示了例 4.2 数据的 。似然函数在 且 时达到最大值, 等于 。这比指数模型的最大值大 倍。右上面板显示了对数似然函数 的等高线图,虚线对应于 时获得的指数密度。因子 给出了最大对数似然值之间的差异 。这一显著提高表明韦伯模型更好地拟合了数据。然而,如果通过最大似然值判断模型拟合,韦伯模型至少和指数模型拟合得一样好,因为 ,且只有当最大值发生在 线上时才会相等。
依赖数据
在上面的例子中,假设数据是独立的,虽然不一定是同分布的。在更复杂的问题中,数据的依赖结构可能非常复杂,使得很难明确写出 。如果数据是按时间顺序记录的,例如 先于 , 先于 ,...... 那么可以帮助写成:
例如,如果数据来自马尔科夫过程,(4.7) 式变为:
我们使用了马尔科夫性质,即在给定“现在” 时,“未来” 与“过去” 相互独立。
例 4.6(泊松出生过程)
假设 满足:给定 , 的条件密度是均值为 的泊松分布,即:
如果 服从均值为 的泊松分布,那么数据 的联合密度为:
因此似然函数 (4.8) 等于:
其中 且 。
4.1.2 基本性质
将似然函数绘制在对数刻度上会很方便。这个刻度在数学上也很方便,我们定义对数似然函数为:
关于相对似然函数的陈述就变成了关于对数似然函数差异的陈述。当 具有独立分量 时,我们可以写成:
其中 是来自第 次观测的对数似然函数的贡献。 和 的参数颠倒是为了强调我们主要关注 作为 的函数,以及 作为 的函数。
对于两个独立的数据集 和 ,其似然函数可以结合为:
这里为了清楚起见,数据是似然函数中的一个附加参数。
似然函数的重要性质
似然函数的一个重要性质是它对已知的数据变换具有不变性。假设两个观察者进行了相同的实验,其中一个记录了连续随机变量 的值 ,而另一个记录了 的值 ,其中 是 的已知一对一变换。那么 的概率密度函数为:
这里 被看作 的函数, 是从 到 的变换的雅可比行列式。由于 (4.10) 与 (4.1) 只相差一个不依赖于参数的常数,因此基于 的对数似然等于基于 的对数似然加上一个常数:不同 值的相对似然函数保持不变。这意味着对于某个特定模型 ,似然函数的绝对值与推断 无关。当似然函数的最大值是有限值时,我们定义 的相对似然为:
其取值介于 0 和 1 之间,对数取值介于负无穷大和 0 之间。由于 的绝对值对于推断 并不重要,我们可以忽略常数,选择任何版本的 。从此以后,我们使用符号 表示在定义对数似然时忽略常数。然而,如果我们的目标是比较来自不同分布族的模型,那么不能忽略常数。
例 4.7(弹簧失效数据)
我们可以通过最大似然值比较例 4.2-4.4 中柯西和韦伯模型的数据。在此标准下,最大对数似然值约为 的韦伯模型比最大对数似然值约为 的柯西模型要好得多。显然,将常数添加到其中一个模型而不是另一个模型是没有意义的。
假设 的分布由 决定, 是 的一对一变换,因此 。那么 的似然函数 与 的似然函数 通过表达式 相关。由于通过此变换, 的值不变,因此似然函数对一对一重新参数化是不变的。我们可以使用一个具有特定问题直接解释的参数化。
例 4.8(挑战者号数据)
我们关注在 31°F 时热失效的概率,以原始参数表示为:
如果我们将 重新参数化为 和 ,则有:
图 4.3 右面板中的对数似然图 比左面板中的 更易于解释,因为 的可能范围变化较慢。左面板中的等高线看起来大致呈椭圆形,而右面板中的等高线则不是。对于 的最可能范围是 (0.7, 0.9),其中 的值约为 。
解释
当对于一组数据有一个特定的参数模型时,似然函数为评估不同参数值的合理性提供了一个自然的基础,但如何解释呢?一种观点是可以使用以下量表比较 的值:
在这种纯粹似然的方式下, 的值仅根据相对似然进行比较。像 (4.11) 这样的量表简单且直接可解释,但它存在的缺点是其中的数值 等是任意的,并且不考虑 的维度,因此在实践中这种解释并不是最常见的。我们将在第 4.5 节中讨论似然值的重复抽样校准。
4.2 总结
4.2.1 二次近似
在具有一个或两个参数的问题中,似然函数是可以可视化的。然而,具有几十个参数的模型很常见,有时参数甚至更多,因此我们经常需要对似然函数进行总结。
一个关键思想是,在许多情况下,对数似然函数作为参数的函数大约是二次的。为了说明这一点,图 4.4 左面板显示了从指数分布 中取样量为 的随机样本的对数似然。在每种情况下,样本的平均值为 。面板有两个总体特征。首先,每个对数似然的最大值在 处。为了理解为什么这样,注意到公式 (4.3) 意味着:
当 时达到最大值,即当 。现在,
在 处取值 ,所以 给出了 的唯一最大值。使 或等效的 最大的 值称为最大似然估计,记作 。为了后续引用,注意到值 及其导数 在邻域 中是有界的,前提是 不包括 。
第二, 在最大值处的曲率随 增加而增加,因为 的二阶导数(度量 关于 的曲率)是 的线性函数。函数 被称为观测信息。在此情况下,其在 处的值为 。
图 4.4 的右面板显示了与左面板对应的相对似然。增加 的效果是似然函数变得更加集中在最大值附近,因此 距离 的固定值变得越来越不可能生成数据。为了代数地表示这一点,我们写出对数相对似然 ,作为 并在 附近对 进行泰勒展开得到:
其中 介于 和 之间。我们用导数符号表示对 的求导,因此 ,等等。注意到 。 的每个导数都是 项的和。随着 的增加,我们看到 的界意味着 (4.12) 中的表达式除非在 处,否则将变得越来越负。因此 趋向于 0,对于所有 ,。
为了更仔细地检查对数似然的行为,我们在 (4.12) 的泰勒展开式中取另一个项,得到:
其中 介于 和 之间。现在考虑当 时会发生什么。随着 增加,这相当于“缩放”到 附近更小的区域。现在:
并且,关键在于 和 都是 的线性函数。 的界意味着 (4.13) 右侧的最后一项当 时消失,但二次项变为 ,在此情况下为 。因此,在大样本中,最大值附近的似然是二次函数,可以用最大似然估计 和观测信息 来总结。
这一点的一个含义是,如果我们将自己限制在相对于最大似然估计合理的参数值,例如那些满足 的 ,则我们发现 。与 (4.13) 进行比较,显示我们的“合理” 的范围随着 的增加而减小,其长度大致与 成正比。
讨论的是标量参数,但可扩展到高维,除非用矩阵的二阶导数代替 。
是否有必要对 进行二次近似取决于问题。对于图 4.2 中的对数似然进行这样的总结可能会产生误导,除非非常接近最大值的情况下需要总结。如果可行,绘制似然函数是合理的。
4.2.2 充分统计量
在行为良好的问题中,对于大样本,似然可以通过最大似然估计和观测信息来总结,尽管示例 4.3 和 4.9 显示这种方法可能会失败。一种更好的方法是,似然通常仅通过某些数据的低维函数 来依赖数据,然后可以用此函数来给出合适的总结。因此在示例 4.2 和 4.9 中,似然分别通过 和 依赖于数据。如果我们相信我们的模型是正确的,我们只需要这些函数来计算任意 值的似然。这些函数是充分统计量的例子。
假设我们观察到的 是由密度为 的分布生成的,并且统计量 是 的函数,使得给定 时,相应随机变量 的条件密度与 无关。即
不依赖于 。那么 被称为基于 的 的充分统计量,或者只是 的充分统计量。这个想法是, 中的任何不在 中的信息都由条件密度 (4.14) 给出,如果该条件密度与 无关,则 中关于 的信息不多于 。稍后我们会看到 并不是唯一的。
定义 (4.14) 难以使用,因为在计算条件密度之前我们必须猜测给定统计量 是否是充分的。一个等价且更有用的定义是通过分解准则给出的。该准则表明,对于参数 ,统计量 成为充分统计量的必要和充分条件是,在一族概率密度函数 中, 的密度可以表示为
因此, 的密度分解为 和 的函数 ,以及一个不依赖于 的函数 。
这两个定义的等价性几乎是不言而喻的。首先注意,如果 是充分统计量,则 在给定 时的条件分布与 无关,即
与 无关。但由于 是 的函数 , 和 的联合密度为零,除非 ,因此右侧的分子只是 。重排 (4.16) 意味着如果 是充分的,则 (4.15) 成立, 且 。
相反,如果 (4.15) 成立,我们通过对使得 的 的范围求和或积分来找到 在 处的密度。在离散情况下,
因为求和是在那些使得 的 上。因此, 在给定 时的条件密度为
这表明 是充分的。
本文作者:某宇_My
本文链接:https://www.cnblogs.com/Desire-My/p/18455939
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)